
Определение алгоритма среднего сдвига
Алгоритм среднего сдвига подпадает под неконтролируемое обучение, которое классифицируется как алгоритм кластеризации. Идеология алгоритма «Среднее смещение» заключается в том, что он итеративно назначает точки данных кластерам, сдвигаясь к точке, имеющей точку с самой высокой плотностью (режим). В основе логики среднего сдвига лежит концепция оценки плотности ядра, называемая KDE.
Кластеризация алгоритма среднего сдвига
Фукунага и Хостеллер обнаружили неконтролируемую технику обучения для поиска кластеров:
- Среднее смещение также известно как алгоритм поиска мод, который назначает точки данных кластерам путем смещения точек данных в область высокой плотности. Самая высокая плотность точек данных называется моделью в регионе. Алгоритм Mean Shift имеет приложения, широко используемые в области компьютерного зрения и сегментации изображений.
- KDE - это метод оценки распределения точек данных. Это работает, помещая ядро в каждую точку данных. Ядро в математике - это весовая функция, которая будет применять весовые коэффициенты для отдельных точек данных. Добавление всего отдельного ядра генерирует вероятность.
Функция ядра обязана удовлетворять следующим условиям:
- Первое требование - убедиться, что оценка плотности ядра нормализована.
- Второе требование заключается в том, что KDE хорошо ассоциируется с симметрией пространства.
Две популярные функции ядра
Ниже приведены две популярные функции ядра:
- Плоское ядро
- Гауссово ядро
- В зависимости от используемого параметра ядра, результирующая функция плотности меняется. Если параметр ядра не указан, ядро Gaussian вызывается по умолчанию. KDE использует концепцию функции плотности вероятности, которая помогает найти локальные максимумы распределения данных. Алгоритм работает, заставляя точки данных притягивать друг друга, позволяя точкам данных двигаться в область высокой плотности.
- Точки данных, которые пытаются сходиться к локальным максимумам, будут принадлежать к одной кластерной группе. В отличие от алгоритма кластеризации K-средних, выходные данные алгоритма среднего сдвига не зависят от предположений о форме точки данных и количестве кластеров. Количество кластеров будет определяться алгоритмом по отношению к данным.
- Для реализации алгоритма Mean Shift мы используем пакет Python SKlearn.
Реализация алгоритма среднего сдвига
Ниже приведена реализация алгоритма:
Пример № 1
На основе учебника Sklearn для алгоритма кластеризации среднего сдвига. В первом фрагменте будет реализован алгоритм среднего смещения для поиска кластеров двумерного набора данных. Пакеты, используемые для реализации алгоритма среднего смещения.
Код:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Важно отметить, что мы будем использовать библиотеку sklearn make_blobs для генерации точек данных, центрированных в 3 местах. Чтобы применить алгоритм «Среднее смещение» к сгенерированным точкам, мы должны установить полосу пропускания, которая представляет взаимодействие между длинами. Библиотека Склеарна имеет встроенные функции для оценки пропускной способности.
Код:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
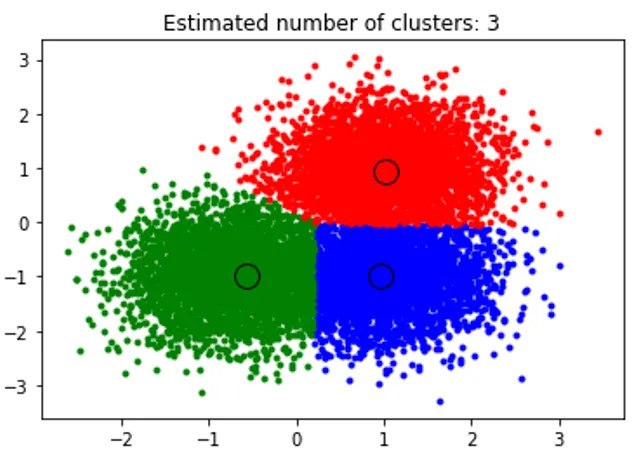
title('Estimated cluster numbers: %d'% n_clusters_)
show()
Приведенный выше фрагмент выполняет кластеризацию, и алгоритм находит кластеры с центром в каждом созданном нами BLOB-объекте. Мы можем видеть, что на изображении ниже, представленном фрагментом, показан алгоритм «Среднее смещение», способный определить количество кластеров, необходимых во время выполнения, и определить соответствующую полосу пропускания для представления длины взаимодействия.
Выход:
Пример № 2
Основано на сегментации изображения в компьютерном зрении. Второй фрагмент расскажет, как алгоритм среднего смещения используется в Deep Learning для сегментации цветного изображения. Мы используем алгоритм среднего сдвига для идентификации пространственных кластеров. В предыдущем фрагменте мы использовали набор двумерных данных, тогда как в этом примере мы будем исследовать трехмерное пространство. Пиксель изображения будет считаться точками данных (r, g, b). Нам нужно преобразовать изображение в формат массива, чтобы каждый пиксель представлял точку данных на изображении, которое мы собираемся представить в сегмент. Кластеризация значений цвета в пространстве возвращает серию кластеров, где пиксели в кластере будут похожи на пространство RGB. Пакеты, используемые для реализации алгоритма среднего смещения:
Код:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Ниже фрагмент для выполнения сегментации исходного изображения:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Сгенерированное изображение утверждает, что этот подход для идентификации форм изображений и определения пространственных кластеров может быть эффективно выполнен без какой-либо обработки изображений.
Выход:


Преимущества и применение Алгоритм среднего сдвига
Ниже приведены преимущества и применение среднего алгоритма:
- Он широко используется для решения компьютерного зрения, где он используется для сегментации изображения.
- Кластеризация точек данных в режиме реального времени без упоминания количества кластеров.
- Хорошо выполняет на сегментации изображения и отслеживания видео.
- Более устойчивы к выбросам.
Плюсы алгоритма среднего сдвига
Ниже приведены плюсы алгоритма среднего смещения:
- Вывод алгоритма не зависит от инициализации.
- Процедура эффективна, так как имеет только один параметр - Bandwidth.
- Нет предположений о количестве кластеров данных и форме.
- Он имеет лучшую производительность, чем K-Means Clustering.
Минусы алгоритма среднего сдвига
Ниже приведены минусы алгоритма среднего смещения:
- Дорого для больших функций.
- По сравнению с кластеризацией K-Means это очень медленно.
- Выход алгоритма зависит от параметра пропускной способности.
- Вывод зависит от размера окна.
Вывод
Хотя это простой подход, который в основном используется для решения проблем, связанных с сегментацией изображения, кластеризацией. Это сравнительно медленнее, чем K-Means, и это дорого в вычислительном отношении.
Рекомендуемые статьи
Это руководство по алгоритму среднего сдвига. Здесь мы обсуждаем проблемы, связанные с сегментацией изображений, кластеризацией, преимуществами и двумя функциями ядра. Вы также можете просмотреть другие наши статьи, чтобы узнать больше-
- Алгоритм кластеризации K-средних
- Алгоритм КНН в R
- Что такое генетический алгоритм?
- Методы ядра
- Ядерные методы в машинном обучении
- Подробное объяснение алгоритма C ++