

Разница между MapReduce и Spark
Map Reduce - это платформа с открытым исходным кодом для записи данных в HDFS и обработки структурированных и неструктурированных данных, представленных в HDFS. Map Reduce ограничивается пакетной обработкой, а на других Spark может выполнять любой тип обработки. SPARK - это независимый обработчик для обработки в реальном времени, который можно установить в любой распределенной файловой системе, такой как Hadoop. SPARK обеспечивает производительность, которая в 10 раз быстрее, чем Map Reduce на диске, и в 100 раз быстрее, чем Map Reduce в сети в памяти.
Нужно для искры
- Итеративная аналитика: Map-Reduction не так эффективен, как SPARK, для решения задач, требующих итеративной аналитики, поскольку он должен выходить на диск для каждой итерации.
- Интерактивная аналитика: Map-Reduce часто используется для выполнения специальных запросов, для которых требуется получить доступ к дисковой памяти, что опять-таки не так эффективно, как SPARK, поскольку последняя ссылается на оперативную память, которая работает быстрее.
- Не подходит для OLTP: поскольку он работает на пакетно-ориентированной среде, он не подходит для большого количества коротких транзакций.
- Не подходит для графика: библиотека Apache Graph обрабатывает график, что добавляет усложнение Map Reduce.
- Не подходит для тривиальных операций. Для таких операций, как фильтр и объединения, может потребоваться переписать задания, что усложняется из-за шаблона ключ-значение.
Сравнение лицом к лицу между MapReduce и Spark (Инфографика)
Ниже приведено 15 лучших отличий между MapReduce и Spark.

Ключевые различия между MapReduce и Spark
Ниже приведены списки точек, описывающие ключевые различия между MapReduce и Spark:
- Spark подходит для работы в режиме реального времени, поскольку он обрабатывает с использованием оперативной памяти, тогда как MapReduce ограничен пакетной обработкой.
- У Spark есть RDD (Resilient Distributed Dataset), который дает нам высокоуровневых операторов, но в Map Reduce нам необходимо кодировать каждую операцию, что делает ее сравнительно сложной.
- Spark может обрабатывать графики и поддерживает инструмент машинного обучения.
- Ниже представлена разница между экосистемой MapReduce и Spark.
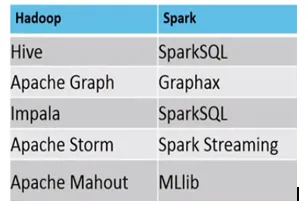
Пример использования MapReduce и Spark:
Spark: обнаружение мошенничества с кредитными картами
MapReduce: Создание регулярных отчетов, которые требуют принятия решений.
MapReduce и Spark Сравнительная таблица
| Основа сравнения | Уменьшение карты | искра |
| Фреймворк | Платформа с открытым исходным кодом для записи данных в HDFS и обработки структурированных и неструктурированных данных, представленных в HDFS. | Среда с открытым исходным кодом для быстрой и универсальной обработки данных |
| скорость | Map-Reduce обрабатывает данные (чтение и запись) с диска, поэтому просачивание происходит медленнее, чем у Spark. | Spark по крайней мере в 10 раз быстрее на диске и в 100 раз быстрее в памяти, чем у Map Reduce. |
| трудность | Нам нужно кодировать / обрабатывать каждый процесс. | Благодаря наличию RDD (Resilient Distributed Dataset) его легко программировать. |
| Реальное время | Не подходит для транзакции OLTP только для пакетного режима | Он может обрабатывать обработку в реальном времени. Использование SPARK Streaming. |
| Задержка | Платформа высокоуровневых вычислений | Низкоуровневая вычислительная среда с задержкой. |
| Отказоустойчивость | Главные демоны проверяют сердцебиение подчиненных демонов, и в случае отказа подчиненных демонов главные демоны перепланируют все ожидающие и выполняемые операции другому подчиненному. | СДР обеспечивают отказоустойчивость к ИСКРЕ. Они ссылаются на набор данных, присутствующий во внешнем хранилище, например (HDFS, HBase), и работают параллельно. |
| планировщик | В Map Reduce мы используем внешний планировщик, такой как Oozie. | Поскольку SPARK работает с вычислениями в памяти, он действует как собственный планировщик. |
| Стоимость | Карта Reduce сравнительно дешевле по сравнению с SPARK. | Поскольку он работает в памяти, он требует много оперативной памяти, что делает его сравнительно более дорогим. |
| Платформа Разработана на | Map Reduce была разработана с использованием Java. | SPARK был разработан с использованием Scala. |
| Язык поддерживается | Map Reduce в основном поддерживает C, C ++, Ruby, Groovy, Perl, Python. | Spark поддерживает Scala, Java, Python, R, SQL. |
| Поддержка SQL | Map Reduce выполняет запросы с использованием языка запросов Hive. | Spark имеет свой собственный язык запросов, известный как Spark SQL. |
| Масштабируемость | В Map Reduce мы можем добавить до n узлов. Самый большой кластер Hadoop имеет 14000 узлов. | В Spark также мы можем добавить n узлов. Самый большой кластер Spark имеет 8000 узлов. |
| Машинное обучение | Map Reduce поддерживает инструмент Apache Mahout для машинного обучения. | Spark поддерживает инструмент MLlib для машинного обучения. |
| Кэширование | Сокращение карт не может кешировать данные в памяти, поэтому оно не такое быстрое по сравнению со Spark. | Spark кэширует данные в памяти для дальнейших итераций, поэтому он очень быстрый по сравнению с Map Reduce. |
| Безопасность | Map Reduce поддерживает больше проектов и функций безопасности по сравнению со Spark | Безопасность Spark еще не созрела, как в Map Reduce |
Вывод - MapReduce vs Spark
В соответствии с вышеупомянутой разницей между MapReduce и Spark, совершенно очевидно, что SPARK является гораздо более продвинутым вычислительным механизмом по сравнению с Map Reduce. Spark совместим с любым типом файлов, а также работает намного быстрее, чем Map Reduce. Кроме того, искра также имеет возможности обработки графиков и машинного обучения.
С одной стороны, Map Reduce ограничивается пакетной обработкой, а с другой стороны, Spark может выполнять любой тип обработки (пакетная, интерактивная, итеративная, потоковая, графическая). Из-за большой совместимости Spark является фаворитом Data Scientist и, следовательно, заменяет Map Reduce и быстро растет. Но все же нам нужно хранить данные в HDFS, а иногда нам может понадобиться HBase. Поэтому нам нужно запустить Spark и Hadoop, чтобы получить лучшее.
Рекомендуемые статьи:
Это было руководство по MapReduce vs Spark, их значению, сравнению «голова к голове», ключевым различиям, сравнительной таблице и выводам. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- 7 важных вещей о Apache Spark (Руководство)
- Hadoop vs Apache Spark - Интересные вещи, которые нужно знать
- Apache Hadoop против Apache Spark | 10 лучших сравнений, которые вы должны знать!
- Как работает MapReduce?
- Слияние технологий и бизнес-аналитики