

Введение в функции в R
Функция определяется как набор операторов для выполнения и выполнения любой конкретной логической задачи. Функция принимает некоторые входные параметры, которые называются аргументами для выполнения этой задачи. Функции помогают разбить код на более простые куски, организовав его логически, что проще для чтения и понимания. В этой теме мы собираемся узнать о функциях в R.
Как написать функции в R?
Чтобы написать функцию в R, вот синтаксис:
Fun_name <- function (argument) (
Function body
)
Здесь видно, что зарезервированное слово «функция» используется в R для определения любой функции. Функция принимает входные данные в форме аргументов. Тело функции представляет собой набор логических операторов, которые выполняются над аргументами и затем возвращают выходные данные. «Fun_name» - это имя, данное функции, через которую она может вызываться в любом месте R-программы.
Давайте посмотрим на пример, который будет более ясным в понимании концепции функции в R.
Код R
Multi <- function(x, y) (
# function to print x multiply y
result <- x*y
print(paste(x, "Multiply", y, "is", result))
)
выход:
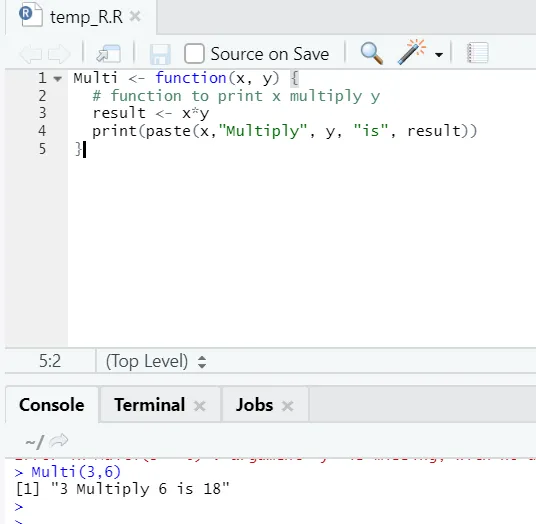
Здесь мы создали имя функции «Multi», которая принимает два аргумента в качестве входных данных и обеспечивает умноженный вывод. Первый аргумент - x, а второй - y. Как видите, мы вызвали функцию с именем «Multi». Здесь, если кто-то хочет, аргументы также могут быть установлены в значение по умолчанию.
Различные типы функций в R
Различные функции R с синтаксисом и примерами (встроенные, математические, статистические и т. Д.)
1) Встроенная функция -
Это функции, которые поставляются с R для решения конкретной задачи, принимая аргумент в качестве входных данных и предоставляя выходные данные на основе заданного входного сигнала. Давайте обсудим некоторые важные общие функции R здесь:
a) Сортировка: данные могут быть в порядке возрастания или убывания. Данные могут быть, является ли вектор продолжения переменной или фактором переменной.
Синтаксис:

Вот объяснение его параметров:
- x: это вектор непрерывной переменной или факторной переменной
- убывающий: это может быть установлено как Истина / Ложь для управления порядком по возрастанию или убыванию. По умолчанию это FALSE`.
- last: если вектор имеет значения NA, должен ли он быть последним или нет
R код и вывод:
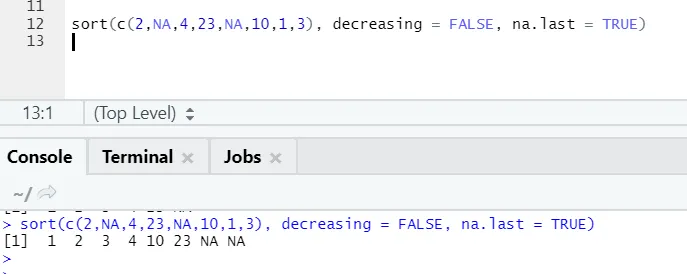
Здесь можно заметить, как значения «NA» выравниваются в конце. Так как наш параметр na.last = True был истинным.
б) Seq: генерирует последовательность чисел между двумя указанными числами.
Синтаксис
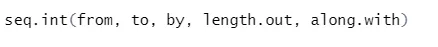
Вот объяснение его параметров:
- от, до начала и конца значения последовательности.
- по: Увеличение / разрыв между двумя последовательными числами в последовательности
- length.out: требуемая длина последовательности.
- Along.with: Относится к длине от длины этого аргумента
R код и вывод:
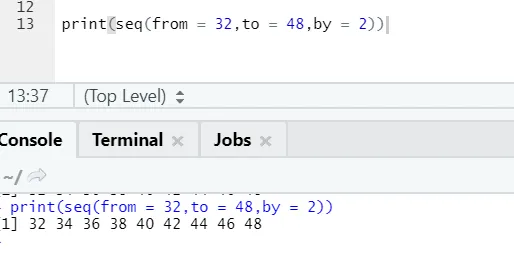
Здесь можно заметить, что сгенерированная последовательность имеет приращение 2, потому что определяется как 2.
c) Toupper, tolower: две функции: toupper и tolower - это функции, применяемые к строке для изменения регистра букв в предложениях.
R код и вывод:
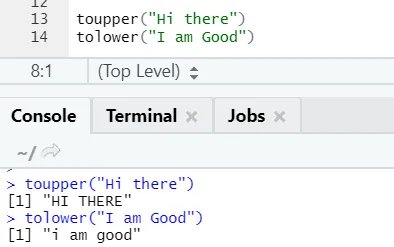
Можно заметить, как меняются регистры букв при применении к функции.
г) Rnorm: это встроенная функция, которая генерирует случайные числа.
R код и вывод:
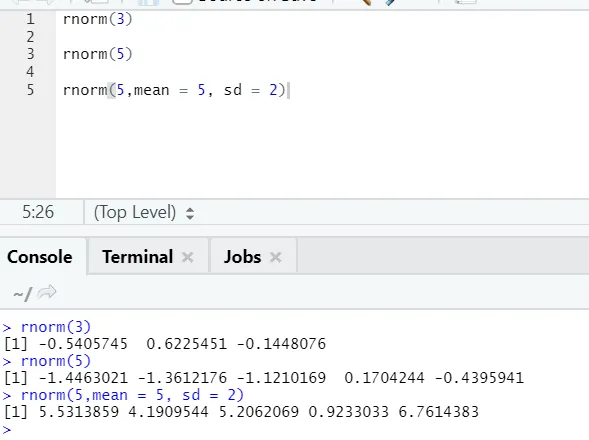
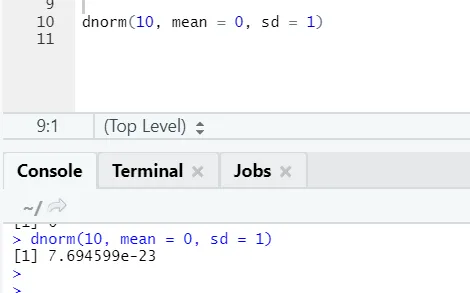
Функция rnorm принимает первый аргумент, который говорит, сколько чисел нужно сгенерировать.
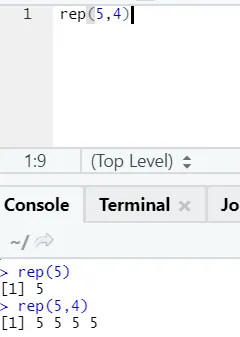
e) Rep: эта функция реплицирует значение столько раз, сколько указано.
Синтаксис R: rnorm (x, n)
Здесь x представляет значение для репликации, а n представляет количество повторений.
R код и вывод:
f) Вставить: эта функция объединяет строки вместе с каким-то конкретным символом между ними.
синтаксис
paste(x, sep = “”, collapse = NULL)
Код R
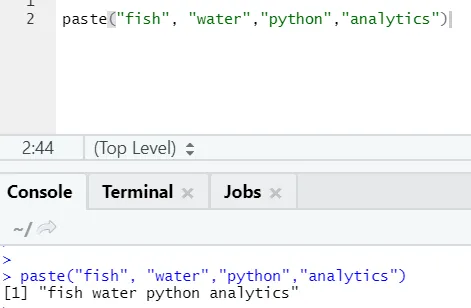
paste("fish", "water", sep=" - ")
R выход:
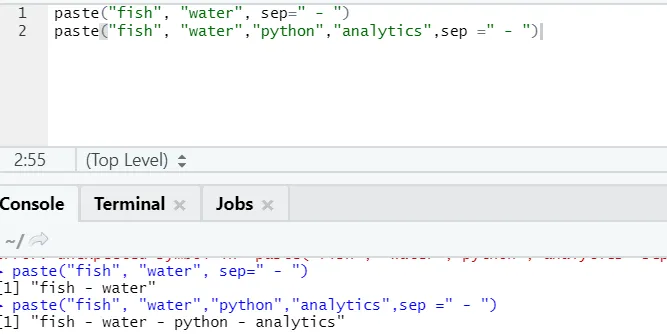
Как видите, мы можем вставить более двух строк. Sep - это тот специфический символ, который мы добавили между строками. По умолчанию sep это пробел.
Существует еще одна похожая функция, о которой все должны знать: paste0.
Функция paste0 (x, y, collapse) работает аналогично paste (x, y, sep = «», collapse)
Пожалуйста, смотрите пример ниже:
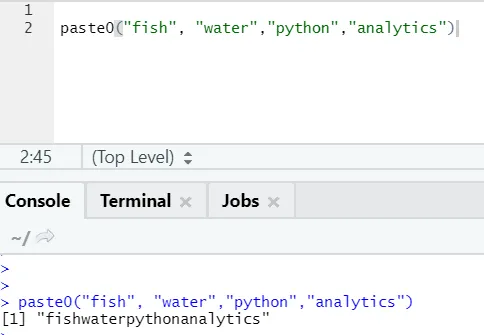
Проще говоря, чтобы подвести итог вставить и вставить0:
Paste0 быстрее, чем paste, когда дело доходит до объединения строк без разделителя. Поскольку paste всегда ищет «sep» и то, что в нем по умолчанию является пробелом.
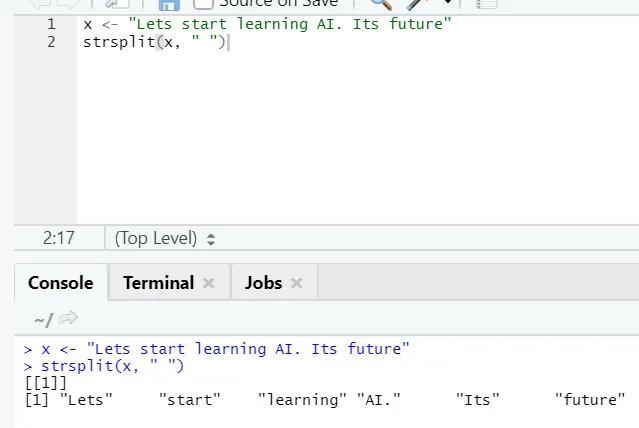
g) Strsplit: эта функция предназначена для разделения строки. Давайте посмотрим на простые случаи:
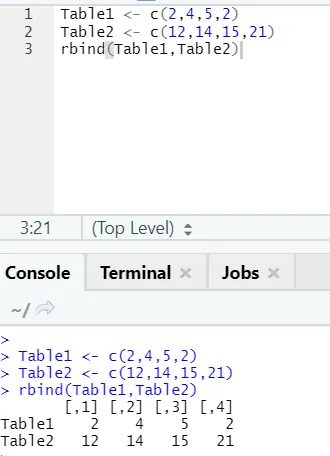
h) Rbind: функция rbind помогает комбинировать векторы с одинаковым количеством столбцов, один над другим.
пример
я) cbind: это объединяет векторы с одинаковым количеством строк, бок о бок.
пример
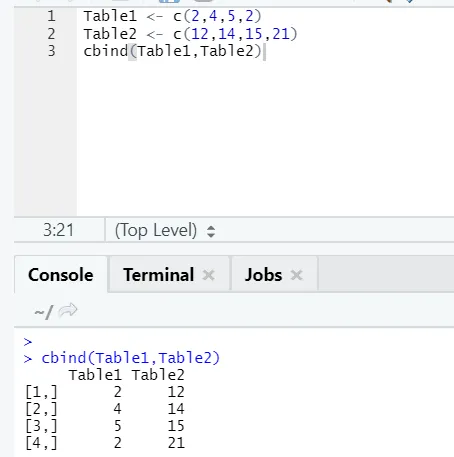
Если количество строк не совпадает, ниже приведена ошибка, которую вы найдете:

И cbind, и rbind помогают в манипулировании данными и их изменении.
2) Математическая функция -
R предоставляет широкий спектр математических функций. Давайте рассмотрим некоторые из них подробно:
а) Sqrt: эта функция вычисляет квадратный корень числа или числового вектора.
R код и вывод:
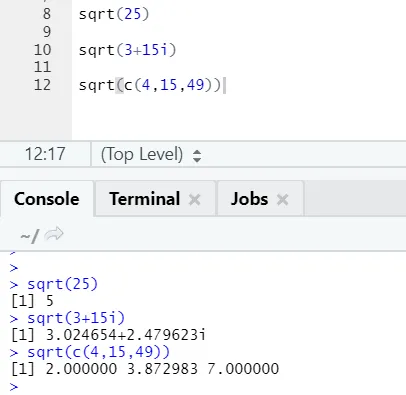
Можно увидеть, как был вычислен квадратный корень из числа, комплексного числа и последовательности числового вектора.
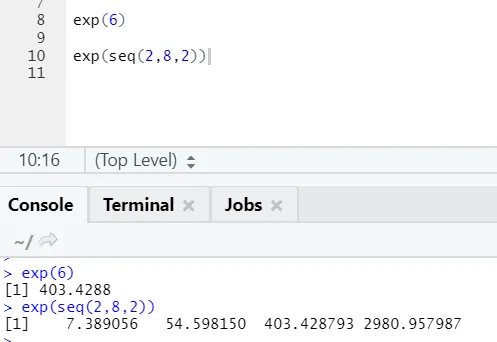
б) Exp: эта функция рассчитывает экспоненциальное значение числа или числового вектора.
R код и вывод:
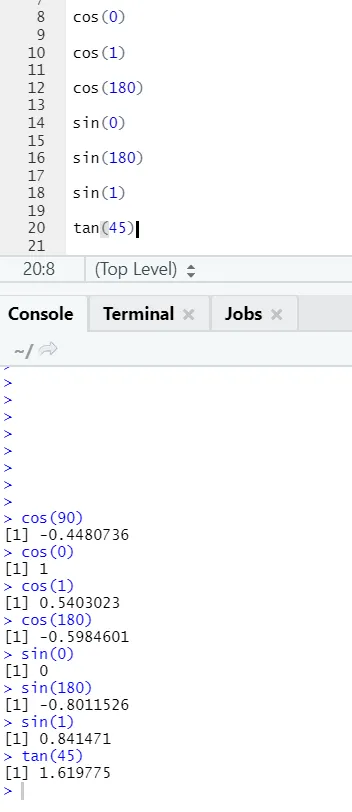
c) Cos, Sin, Tan: это тригонометрические функции, реализованные в R здесь.
R код и вывод:
d) Abs: эта функция возвращает абсолютное положительное значение числа.
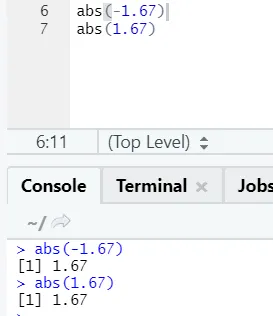
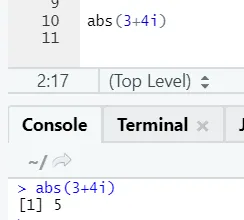
Как видите, отрицательное или положительное число будет возвращено в абсолютной форме. Давайте посмотрим на это для комплексного числа:
д) Журнал: это найти логарифм числа.
Вот пример, показанный ниже:
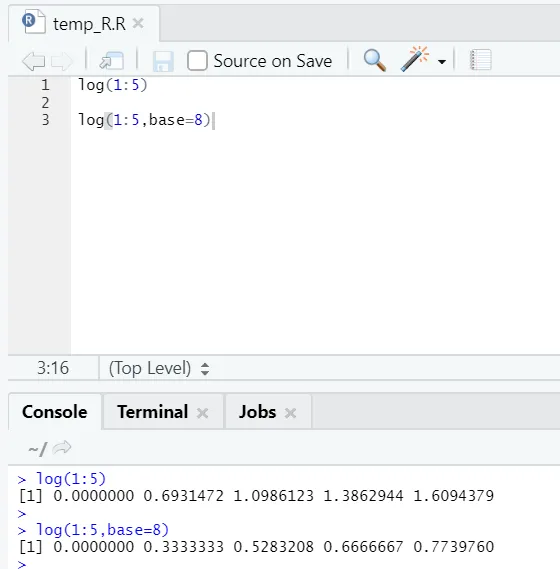
Здесь каждый получает гибкость, чтобы изменить основание согласно требованию.
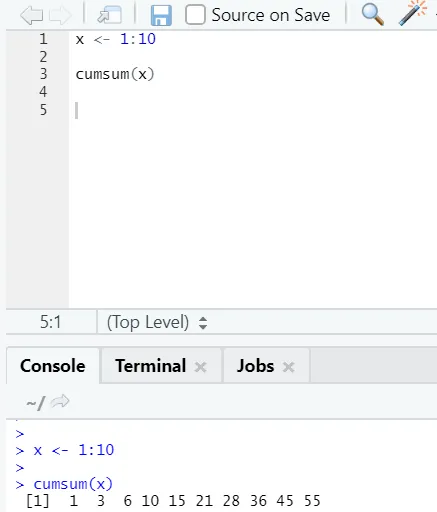
е) Cumsum: это математическая функция, которая дает кумулятивные суммы. Вот пример ниже:
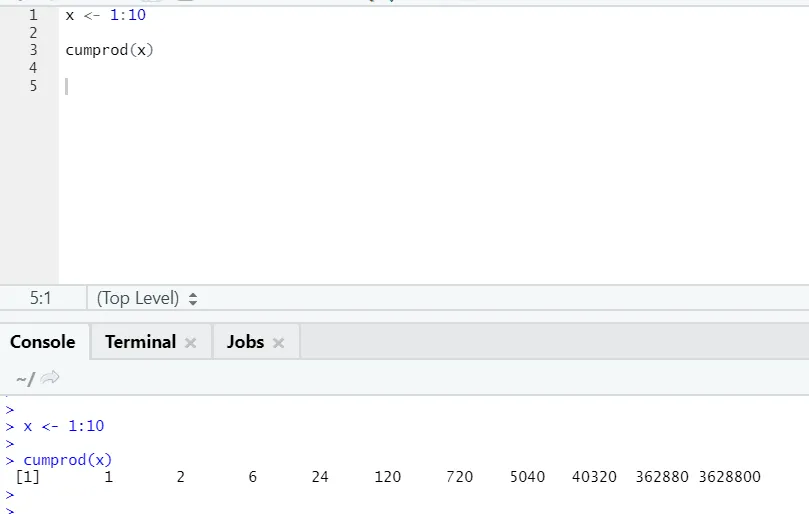
g) Cumprod: подобно математической функции Cumsum, у нас есть cumprod, где происходит кумулятивное умножение.
Пожалуйста, смотрите пример ниже:
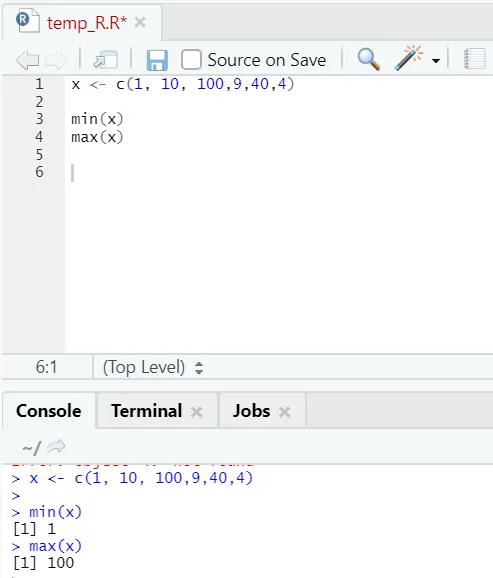
h) Макс, Мин: это поможет вам найти максимальное / минимальное значение в наборе чисел. Ниже приведены примеры, связанные с этим:
я) Потолок: потолок математическая функция возвращает наименьшее из целых чисел выше, чем указано.
Давайте посмотрим на пример:
потолок (2, 67)
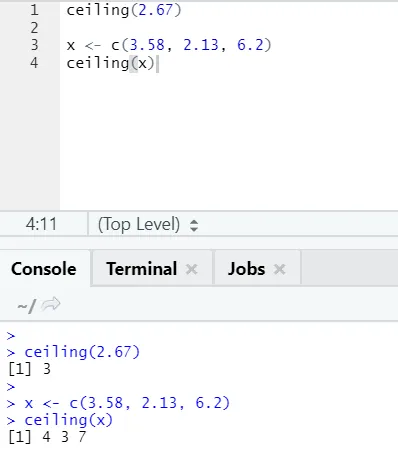
Как вы можете заметить, потолок применяется как к числу, так и к списку, и полученный результат является наименьшим из следующего более высокого целого числа.
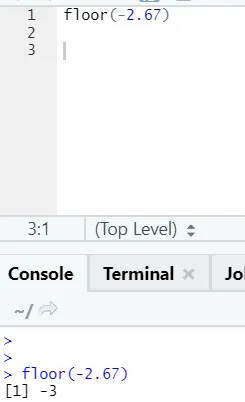
j) Floor: floor - математическая функция, которая возвращает целое число наименьшего значения из указанного числа.
Приведенный ниже пример поможет вам лучше понять это:
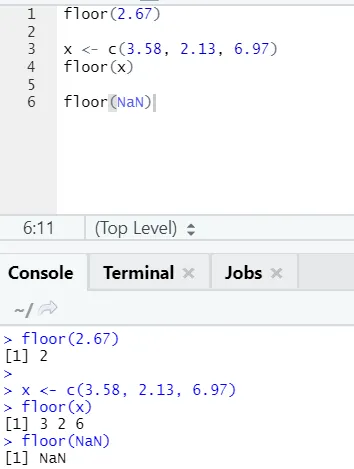
Это работает так же и для отрицательных значений. Пожалуйста, взгляните:
3) Статистические функции -
Это функции, которые описывают соответствующее распределение вероятностей.
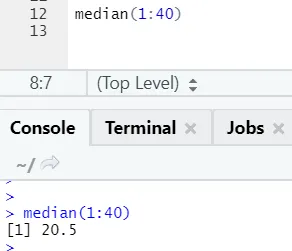
а) Медиана: рассчитывается медиана из последовательности чисел.
Синтаксис
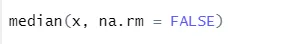
R код и вывод:
б) Днорм: это относится к нормальному распределению. Функция dnorm возвращает значение функции плотности вероятности для нормального распределения заданных параметров для x, µ и σ.
R код и вывод:
c) Cov: Ковариация указывает, являются ли два вектора положительно, отрицательно или полностью не связаны между собой.
Код R
x_new = c(1., 5.5, 7.8, 4.2, -2.7, -5.5, 8.9)
y_new = c(0.1, 2.0, 0.8, -4.2, 2.7, -9.4, -1.9)
cov(x_new, y_new)
R выход:
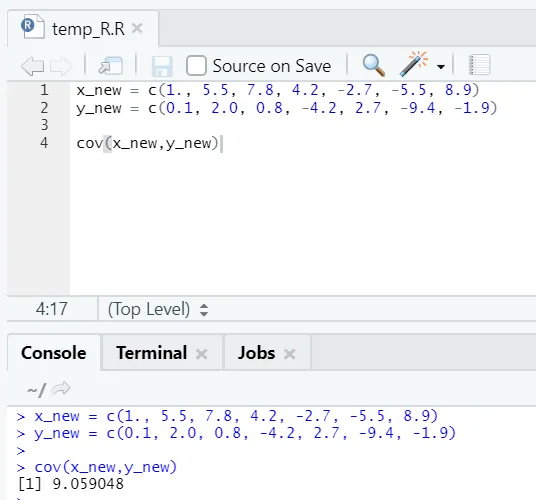
Как видите, два вектора положительно связаны, что означает, что оба вектора движутся в одном направлении. Если ковариация отрицательна, это означает, что x и y обратно связаны и, следовательно, движутся в противоположном направлении.
г) Cor: это функция, чтобы найти корреляцию между векторами. Это фактически дает коэффициент ассоциации между двумя векторами, который известен как «коэффициент корреляции». Корреляция добавляет коэффициент степени по ковариации. Если два вектора положительно коррелируют, корреляция также скажет вам, насколько сильно они положительно связаны.
Эти три типа методов, которые могут использоваться, чтобы найти корреляцию между двумя векторами:
- Корреляции Пирсона
- Корреляция Кендалла
- Корреляция Спирмена
В простом формате R это выглядит так:
cor(x, y, method = c("pearson", "kendall", "spearman"))
Здесь x и y - векторы.
Давайте посмотрим на практический пример корреляции по встроенному набору данных.
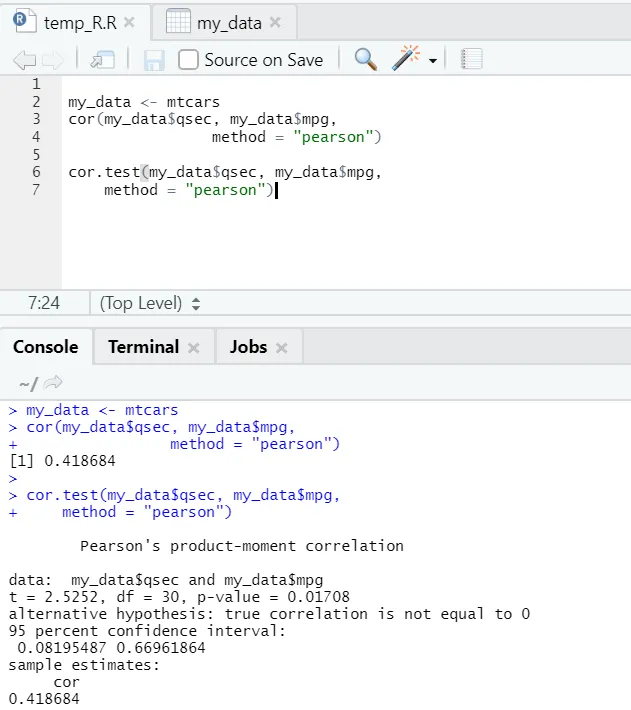
Итак, здесь вы можете видеть, что функция «cor ()» дала коэффициент корреляции 0, 41 между «qsec» и «mpg». Однако была также продемонстрирована еще одна функция, т. Е. «Cor.test ()», которая сообщает не только коэффициент корреляции, но также значение p и значение t, связанные с ним. Интерпретация становится намного проще с функцией cor.test.
Аналогичное можно сделать с двумя другими методами корреляции:
R код для метода Пирсона:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = " pearson ")
cor.test(my_data$qsec, my_data$mpg, method = " pearson")
R-код для метода Кендалла:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = " kendall")
cor.test(my_data$qsec, my_data$mpg, method = " kendall")
R-код для метода Спирмена:
my_data <- mtcars
cor(my_data$qsec, my_data$mpg, method = "spearman")
cor.test(my_data$qsec, my_data$mpg, method = "spearman")
Коэффициент корреляции находится в диапазоне от -1 до 1.
Если коэффициент корреляции отрицателен, это означает, что при увеличении x у уменьшается.
Если коэффициент корреляции равен нулю, это означает, что не существует никакой связи между x и y.
Если коэффициент корреляции положительный, это означает, что при увеличении х у также имеет тенденцию к увеличению.
e) T-тест: T-тест скажет вам, поступают ли два набора данных из одинаковых (при условии) нормальных распределений или нет.
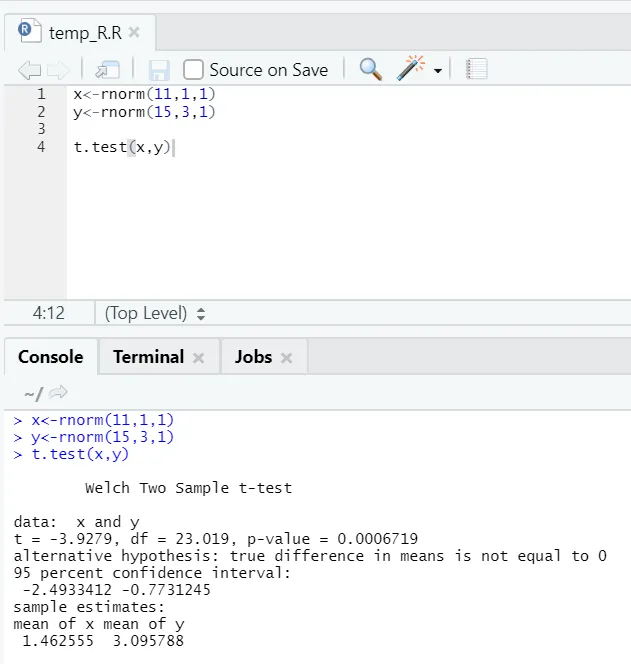
Здесь вам следует отвергнуть нулевую гипотезу о том, что два средних значения равны, поскольку значение p меньше 0, 05.
Этот показанный экземпляр имеет тип: непарные наборы данных с неравными отклонениями. Точно так же можно попробовать с парным набором данных.
f) Простая линейная регрессия: показывает связь между предиктором / независимой и ответной / зависимой переменной.
Простым практическим примером может быть прогнозирование веса человека, если рост известен.
R синтаксис
lm(formula, data)
Здесь формула отображает соотношение между выходом, т. Е. Y, и входной переменной iex. Данные представляют набор данных, к которому необходимо применить формулу.
Давайте рассмотрим один практический пример, где площадь пола является входной переменной, а рента - выходной переменной.
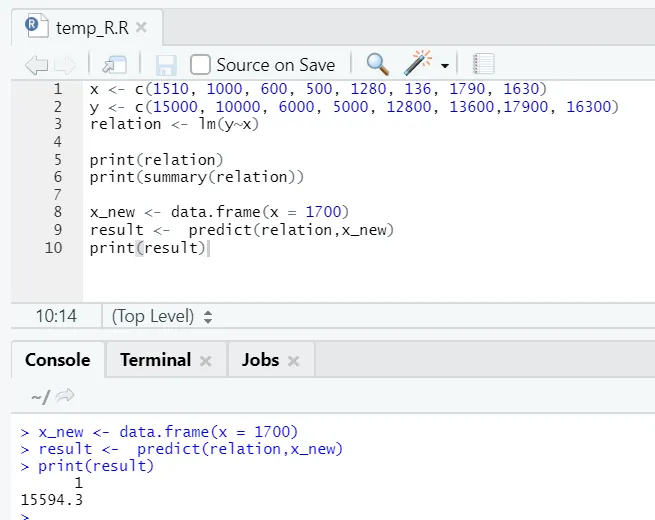
х <- с (1510, 1000, 600, 500, 1280, 136, 1790, 1630)
у <- с (15000, 10000, 6000, 5000, 12800, 13600, 170000, 16300)
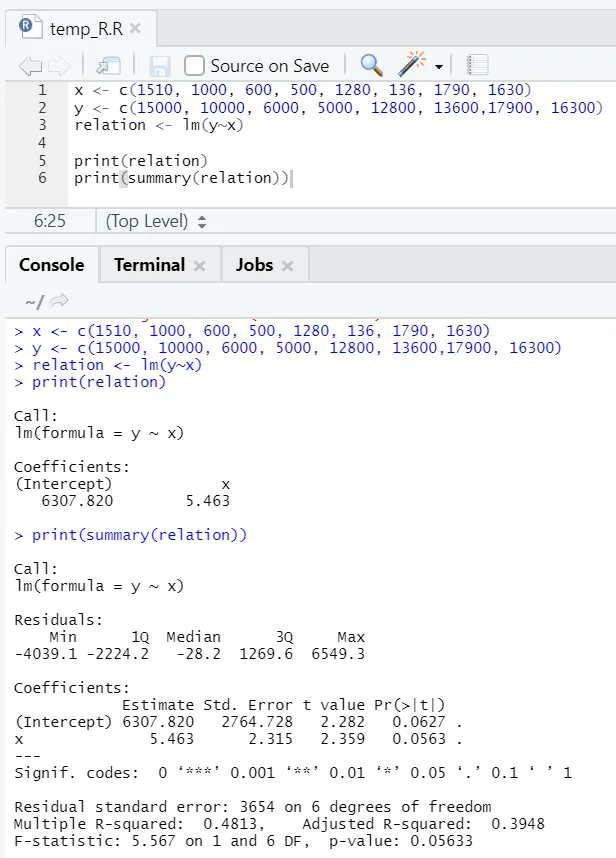
Здесь P-значение составляет не менее 5%. Следовательно, нулевая гипотеза не может быть отклонена. Нет особого смысла доказывать связь между площадью и арендной платой.
Здесь значение R-квадрата равно 0, 4813. Это означает, что только 48% дисперсии в выходной переменной может быть объяснено входной переменной.
Допустим, теперь нам нужно спрогнозировать значение площади пола, основываясь на приведенной выше модели.
Код R
x_new <- data.frame(x = 1700)
result <- predict(relation, x_new)
print(result)
R выход:
После выполнения вышеприведенного кода R результат будет выглядеть следующим образом:
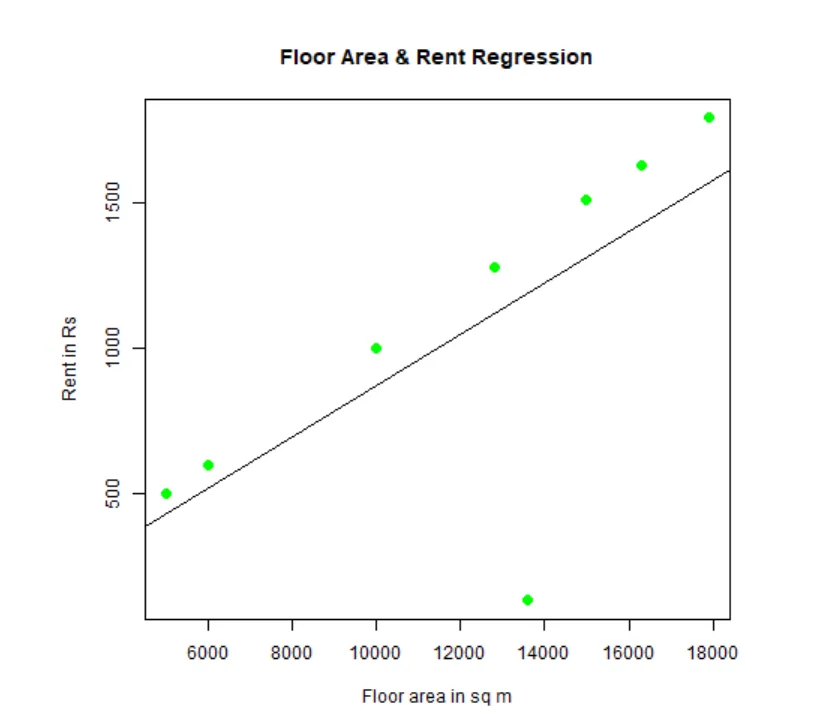
Можно подогнать и визуализировать регрессию. Вот код R для этого:
# Дайте файлу диаграммы png имя.
png(file = "LinearRegressionSample.png.webp")
# Постройте график.
plot(y, x, col = "green", main = "Floor Area & Rent Regression",
abline(lm(x~y)), cex = 1.3, pch = 16, xlab = "Floor area in sq m", ylab = "Rent in Rs")
# Сохраните файл.
dev.off()
Этот график «LinearRegressionSample.png.webp» будет создан в вашем текущем рабочем каталоге.
г) критерий хи-квадрат
Это статистическая функция в R. Этот тест имеет значение, чтобы доказать, существует ли корреляция между двумя категориальными переменными.
Этот тест также работает как любые другие статистические тесты, основанные на p-значении, можно принять или отклонить нулевую гипотезу.
R синтаксис
chisq.test(data), /code>
Давайте посмотрим на один практический пример этого.
Код R
# Загрузить библиотеку.
library(datasets)
data(iris)
# Создать фрейм данных из основного набора данных.
iris.data <- data.frame(iris$Sepal.Length, iris$Sepal.Width)
# Создать таблицу с необходимыми переменными.
iris.data = table(iris$Sepal.Length, iris$Sepal.Width)
print(iris.data)
# Выполните тест хи-квадрат.
print(chisq.test(iris.data))
R выход:
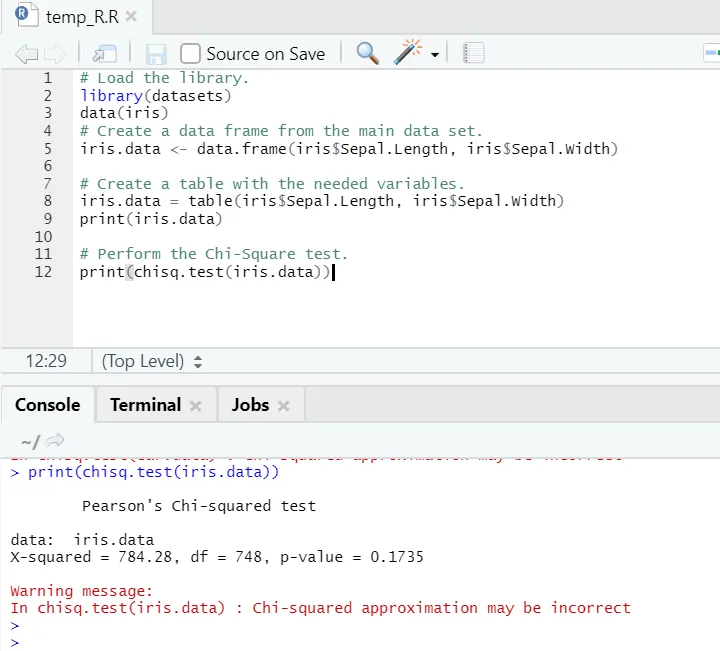
Как видно, тест хи-квадрат был выполнен над набором данных радужной оболочки, учитывая две его переменные: «Sepal. Длина »и« Sepal.Width ».
Значение р составляет не менее 0, 05, следовательно, между этими двумя переменными не существует корреляции. Или мы можем сказать, что эти две переменные не зависят друг от друга.
Вывод
Функции в R просты, просты в установке, просты для понимания и при этом очень мощные. Мы видели множество функций, которые используются как часть основ в R. Как только вы освоитесь с этими функциями, рассмотренными выше, вы можете исследовать другие разновидности функций. Функции помогут вам сделать ваш код простым и лаконичным. Функции могут быть встроенными или определяемыми пользователем, все зависит от необходимости решения проблемы. Функции дают хорошую форму программе.
Рекомендуемые статьи
Это руководство по функциям в R. Здесь мы обсудим, как написать Функции в R и различные типы функций в R с синтаксисом и примерами. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Строковые функции R
- Строковые функции SQL
- Строковые функции T-SQL
- Строковые функции PostgreSQL