

Обзор архитектуры интеллектуального анализа данных
Интеллектуальный анализ данных - это способ найти и исследовать шаблоны базового или продвинутого уровня в сложном наборе больших наборов данных, который включает методы, размещенные на пересечении статистики, машинного обучения, а также систем баз данных. Можно сказать, что это междисциплинарная область статистики и компьютерных наук, целью которой является извлечение информации с использованием интеллектуальных методов и приемов из конкретного набора данных посредством извлечения и, тем самым, преобразования данных. Действия по управлению данными и операции по предварительной обработке данных наряду с соображениями вывода также принимаются во внимание. В этой статье мы углубимся в архитектуру интеллектуального анализа данных.
Архитектура интеллектуального анализа данных
Интеллектуальный анализ данных - это метод извлечения интересных знаний из множества огромных объемов данных, которые затем хранятся во многих источниках данных, таких как файловые системы, хранилища данных, базы данных. Основные компоненты архитектуры интеллектуального анализа данных включают в себя:
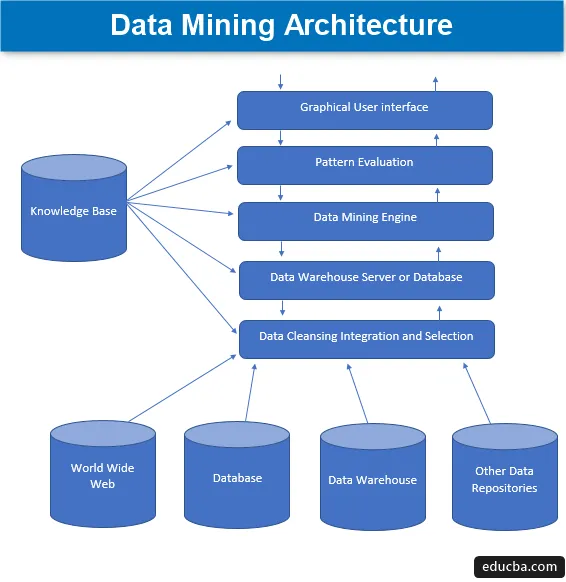
1. Источники данных
Огромное разнообразие нынешних документов, таких как хранилище данных, база данных, www или широко известная всемирная паутина, которая становится фактическим источником данных. В большинстве случаев это также может быть случай, когда данные отсутствуют ни в одном из этих «золотых» источников, а только в виде текстовых файлов, простых файлов или файлов последовательностей или электронных таблиц, и затем данные необходимо обрабатывать в очень Таким же образом, как обработка будет осуществляться на данных, полученных из золотых источников. Большая часть основной части данных сегодня поступает из Интернета или всемирной паутины, поскольку все, что присутствует в Интернете сегодня, - это данные в той или иной форме, которые образуют некую форму единиц хранения информации.
Перед дальнейшей обработкой данных различные процессы, через которые они проходят, включают в себя очистку, интеграцию и выборку данных, прежде чем, наконец, данные будут переданы в базу данных или любой сервер EDW (хранилище корпоративных данных). Основная проблема, которая порой связана с этим набором данных, - это разные уровни источников и широкий спектр форматов данных, которые формируют компоненты данных. Поэтому данные не могут быть непосредственно использованы для обработки в их наивном состоянии, а обработаны, преобразованы и обработаны гораздо более удобным способом. Таким образом, надежность и полнота данных также обеспечивается. Таким образом, основной шаг включает сбор, очистку и интеграцию данных, а также публикацию, что только соответствующие данные передаются. Вся эта деятельность является частью отдельного набора инструментов и методов.
2. Сервер или база данных хранилища данных
Сервер базы данных - это фактическое пространство, в котором хранятся данные после их получения из различного числа источников данных. Сервер содержит фактический набор данных, который становится готовым для обработки, и, следовательно, сервер управляет поиском данных. Вся эта деятельность основана на запросе данных человека.
3. Data Mining Engine
В случае интеллектуального анализа данных движок формирует основной компонент и является наиболее важной частью, или, скажем, движущей силой, которая обрабатывает все запросы и управляет ими и используется для содержания ряда модулей. В число имеющихся модулей входят такие задачи майнинга, как метод классификации, метод ассоциации, метод регрессии, характеристика, прогнозирование и кластеризация, анализ временных рядов, наивный байесовский метод, опорные векторные машины, методы ансамбля, методы повышения и суммирования, случайные леса, деревья решений, и т.п.
4. Модули оценки шаблонов
Этот метод оценки модулей в основном отвечает за измерение интереса ко всем тем шаблонам, которые используются для расчета базового уровня порогового значения, а также используется для взаимодействия с механизмом интеллектуального анализа данных для координации оценки других модулей. В общем, основная цель этого компонента - искать и искать все интересные и полезные шаблоны, которые могут сделать данные сравнительно лучшего качества.
5. Графический интерфейс пользователя
Когда данные передаются с помощью механизмов и среди различных шаблонов оценки модулей, возникает необходимость взаимодействовать с различными присутствующими компонентами и делать их более удобными для пользователя, чтобы можно было эффективно и эффективно использовать все представленные компоненты и, следовательно, возникает необходимость в графическом пользовательском интерфейсе, широко известном как GUI.
Это используется для установления чувства контакта между пользователем и системой интеллектуального анализа данных, тем самым помогая пользователям эффективно и легко получать доступ к системе и использовать ее, чтобы избежать каких-либо сложностей, возникающих в процессе. Это форма абстракции, когда пользователям показываются только соответствующие компоненты, а все сложности и функциональные возможности, ответственные за создание системы, скрыты ради простоты. Всякий раз, когда пользователь отправляет запрос, модуль затем взаимодействует с общим набором системы интеллектуального анализа данных, чтобы создать релевантный вывод, который может быть легко показан пользователю гораздо более понятным способом.
6. База знаний
Это компонент, который формирует основу всего процесса интеллектуального анализа данных, поскольку он помогает вести поиск или оценивать интересность сформированных шаблонов. Эта база знаний состоит из убеждений пользователей, а также данных, полученных из опыта пользователей, которые, в свою очередь, полезны в процессе интеллектуального анализа данных. Движок может получить набор входных данных из созданной базы знаний и тем самым обеспечить более эффективные, точные и надежные результаты.
Интеллектуальный анализ данных является сегодня одним из наиболее важных методов, который связан с управлением данными и их обработкой, которые составляют основу любой организации. Анализ данных в любой организации принесет плодотворные результаты. Каждый компонент технологии и архитектуры интеллектуального анализа данных имеет свой собственный способ выполнения обязанностей, а также эффективного завершения интеллектуального анализа данных. Различные модули необходимы для правильного взаимодействия, чтобы получить ценный результат и успешно завершить сложную процедуру интеллектуального анализа данных, предоставляя бизнесу необходимый набор информации.
Рекомендуемые статьи
Это было руководство по архитектуре интеллектуального анализа данных. Здесь мы обсудим основные компоненты архитектуры интеллектуального анализа данных. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Инструмент интеллектуального анализа данных
- Преимущества Data Mining
- Что такое кластеризация в интеллектуальном анализе данных?
- HTML5 Интервью Вопросы и ответы
- Наиболее используемые техники ансамблевого обучения
- Алгоритмы моделей в Data Mining