

Введение в Joins in Hive
Соединения используются для извлечения различных выходных данных с использованием нескольких таблиц, объединяя их на основе определенных столбцов. Теперь для того, чтобы таблицы были в Hive, мы должны создать таблицы и загрузить данные в каждую таблицу. Мы собираемся использовать две таблицы (клиент и продукт) здесь для понимания цели.
Разные команды
Ниже приведены команды для создания и загрузки данных в этих таблицах:
Для таблицы клиента : 6 строк
Создать команду
Создать внешнюю таблицу, если не существует клиента (строка идентификатора, строка имени, строка города)
формат строки с разделителями
поля заканчиваются на ''
расположение '/user/hive/warehouse/test.db/customer'
tblproperties («skip.header.line.count» = «1»);
Команда загрузки
Загрузить данные локально по пути '/home/cloudera/Customer_Neha.txt' в таблицу customer;
Данные таблицы клиента

Для таблицы продуктов : 6 строк
Создать команду
Создать внешнюю таблицу, если не существует продукта (строка Cust_Id,
Строка продукта, Строка цены)
формат строки с разделителями
поля заканчиваются на ''
расположение '/user/hive/warehouse/test.db/product'
tblproperties («skip.header.line.count» = «1»);
Команда загрузки
Загрузите локальный путь к данным /home/cloudera/Product_Neha.txt в таблицу product;
Данные Таблицы Продуктов
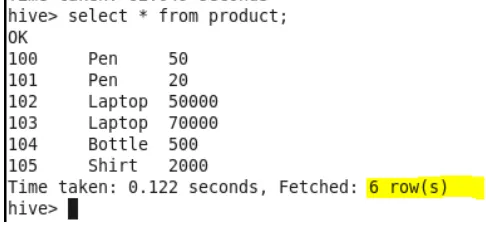
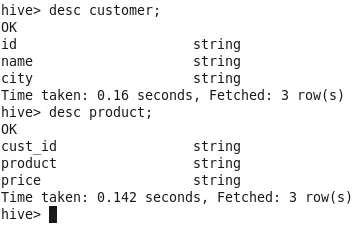
Чтобы проверить схему таблицы, используйте команду «desc table name»;
Теперь у нас есть данные в таблицах, давайте поиграемся с этим ????
Типы соединений в улье
Соединение - это даст перекрестный продукт обеих данных таблицы в качестве вывода. Как видите, у нас есть 6 строк в каждой таблице. Таким образом, вывод для Join будет 36 строк. Количество картографов-1. Тем не менее, здесь нет сокращения оператора.
команда

Выход:
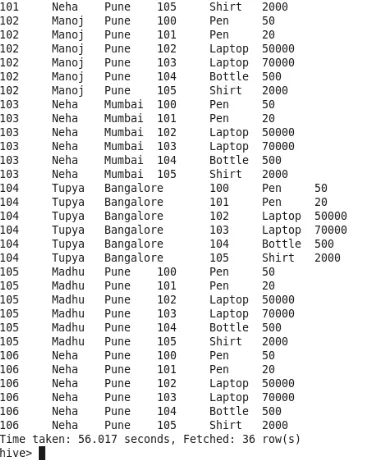
1. Полное соединение
Полное объединение без совпадения даст перекрестное произведение обеих таблиц.
Количество картографов-2
Номер редуктора-1
Этого также можно достичь, используя «Join», но с меньшим количеством картографов и редукторов.
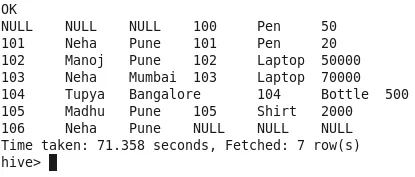
Полное соединение с условием совпадения
Все строки будут объединены из обеих таблиц. Если строки не совпадают в другой таблице, в выводе будет заполнено значение NULL (Observe Id-100, 106). Строки не пропущены.
Количество картографов-2
Номер редуктора-1
команда

Выход:
2. Внутреннее соединение
Если внутреннее соединение используется без предложения «on», в качестве результата будет получено перекрестное произведение. Тем не менее, мы должны использовать конкретные столбцы, на которых может быть выполнено объединение. Столбец Id из таблицы customer и столбец Cust_id из таблицы product являются моими конкретными столбцами. Выходные данные содержат строки, в которых совпадают Id и Cust_Id. Вы можете заметить, что строки с Id-106 и Cust_Id-100 пропускаются при выводе, потому что их нет в другой таблице.
команда

Выход:

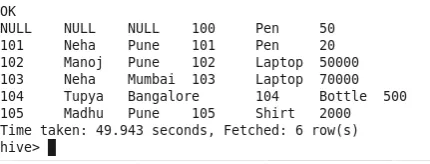
3. Левое соединение
Все строки из левой таблицы объединяются с соответствующими строками из правой таблицы. Если в правой таблице есть строки с идентификаторами, которых нет в левой таблице, эти строки будут пропущены (обратите внимание на Cust_Id-100 в выходных данных). Если правая таблица не имеет строк с идентификаторами, которые есть в левой таблице, NULL будет заполнен в выходных данных (наблюдайте Id-106 в выходных данных).
Номер Mapper-1
Номер редуктора-0
команда

Выход:
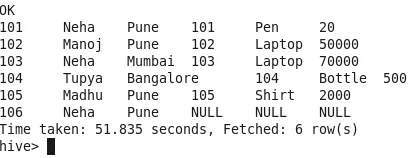
4. Правильное соединение
Все строки в правой таблице сопоставляются со строками левой таблицы. Если в левой таблице нет ни одной строки, будет заполнено значение NULL (Observ Id 100). Строки из левой таблицы будут пропущены, если это совпадение не найдено в правой таблице (Observ Id 106).
Номер Mapper-1
Номер редуктора-0
команда

Выход:
Вывод - присоединяется в улье
«Объединить», как следует из слова, может объединить две или более таблиц в базе данных. Это похоже на объединения в SQL. Соединения используются для извлечения различных выходных данных с использованием нескольких таблиц, объединяя их на основе определенных столбцов. На основании требования можно решить, какое объединение будет работать для вас. Например, если вы хотите проверить, какие идентификаторы присутствуют в левой таблице, а не в правой, вы можете просто использовать левое соединение. В зависимости от сложности в ульях можно выполнять различные оптимизации. Некоторые из примеров - это соединения перераспределения, соединения репликации и полу соединения.
Рекомендуемые статьи
Это руководство к Joins in Hive. Здесь мы обсуждаем типы объединений, такие как полное соединение, внутреннее соединение, левое соединение и правое соединение в кусте, а также его команда и вывод. Вы также можете посмотреть следующие статьи, чтобы узнать больше
- Что такое улей?
- Команды улья
- Обучение ульям (2 курса, 5+ проектов)
- Apache Pig против Apache Hive - Лучшие 12 полезных отличий
- Особенности Улей Альтернативы
- Использование функции ORDER BY в Hive
- 6 лучших типов соединений в MySQL с примерами