
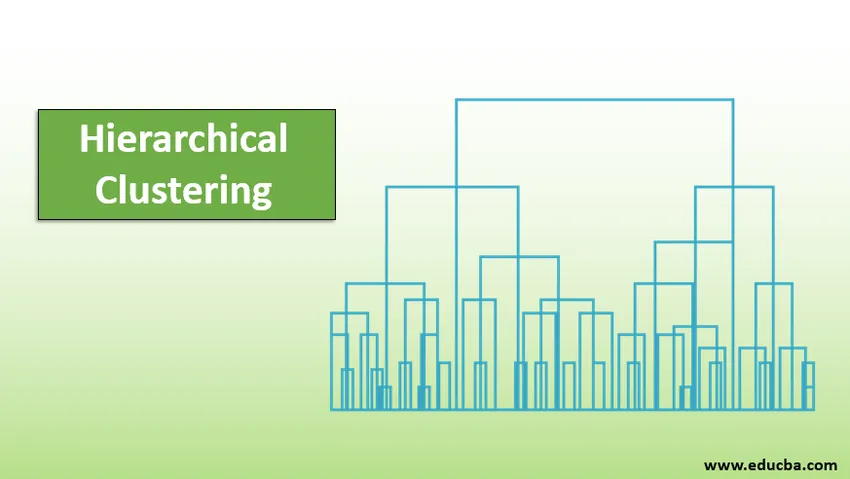
Введение в иерархическую кластеризацию
- Недавно один из наших клиентов попросил нашу команду составить список сегментов с заказом важности среди своих клиентов, чтобы нацелить их на франшизу одного из своих недавно выпущенных продуктов. Ясно, что простое сегментирование клиентов с использованием частичной кластеризации (k-means, c-fuzzy) не выявит порядок важности, в котором иерархическая кластеризация проявляется.
- Иерархическая кластеризация - это разделение данных на разные группы на основе некоторых мер сходства, известных как кластеры, которые по существу направлены на построение иерархии между кластерами. Это в основном обучение без присмотра, и выбор атрибутов для измерения сходства зависит от конкретного приложения.
Кластер иерархии данных
- Агломерационная кластеризация
- Дивизионная кластеризация
Давайте возьмем пример данных, оценки, полученные 5 студентами, чтобы сгруппировать их для предстоящего конкурса.
| Ученик | Метки |
| 10 | |
| В | 7 |
| С | 28 |
| D | 20 |
| Е | 35s |
1. Агломерационная кластеризация
- Для начала мы рассматриваем каждую отдельную точку / элемент здесь как кластеры и продолжаем объединять подобные точки / элементы, чтобы сформировать новый кластер на новом уровне, пока мы не останемся с одним кластером - подход снизу вверх.
- Одиночная связь и полная связь - два популярных примера агломерационной кластеризации. Кроме этой средней связи и центроидной связи. В одной связи мы объединяем на каждом шаге два кластера, два ближайших элемента которых имеют наименьшее расстояние. При полной связи мы объединяем элементы наименьшего расстояния, которые обеспечивают наименьшее максимальное попарное расстояние.
- Матрица близости. Это ядро для выполнения иерархической кластеризации, которая дает расстояние между каждой из точек.
- Давайте создадим матрицу близости для наших данных, приведенных в таблице, так как мы рассчитываем расстояние между каждой из точек с другими точками, это будет асимметричная матрица формы n × n, в нашем случае матрицы 5 × 5.
Популярный метод для расчета расстояния:
- Евклидово расстояние (квадрат)
dist((x, y), (a, b)) = √(x - a)² + (y - b)²
- Манхэттенское расстояние
dist((x, y), (a, b)) =|x−c|+|y−d|
Евклидово расстояние наиболее часто используется, мы будем использовать то же самое здесь, и мы будем идти со сложной связью.
| Студент (Clusters) | В | С | D | Е | |
| 0 | 3 | 18 | 10 | 25 | |
| В | 3 | 0 | 21 | 13 | 28 |
| С | 18 | 21 | 0 | 8 | 7 |
| D | 10 | 13 | 8 | 0 | 15 |
| Е | 25 | 28 | 7 | 15 | 0 |
Диагональные элементы матрицы близости всегда будут 0, так как расстояние между точкой с одной и той же точкой будет всегда 0, следовательно, диагональные элементы освобождаются от рассмотрения для группировки.
Здесь в итерации 1 наименьшее расстояние равно 3, поэтому мы объединяем A и B, чтобы сформировать кластер, и снова формируем новую матрицу близости с кластером (A, B), принимая (A, B) точку кластера за 10, то есть максимум ( 7, 10) поэтому вновь сформированная матрица близости будет
| Кластеры | (А, Б) | С | D | Е |
| (А, Б) | 0 | 18 | 10 | 25 |
| С | 18 | 0 | 8 | 7 |
| D | 10 | 8 | 0 | 15 |
| Е | 25 | 7 | 15 | 0 |
На итерации 2 7 - это минимальное расстояние, поэтому мы объединяем C и E, образуя новый кластер (C, E), повторяем процесс, который повторяется в итерации 1, пока не получим один кластер, здесь мы остановимся на итерации 4.
Весь процесс изображен на рисунке ниже:
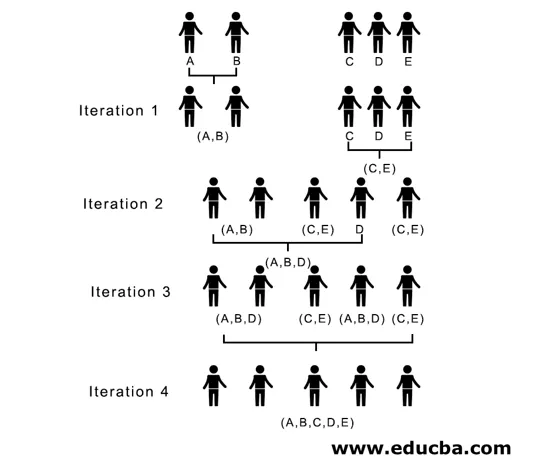
(A, B, D) и (D, E) - 2 кластера, сформированные на итерации 3, на последней итерации мы можем видеть, что у нас остался один кластер.
2. Разделительная кластеризация
Для начала мы рассматриваем все точки как один кластер и разделяем их на самое дальнее расстояние, пока не закончим с отдельными точками как отдельными кластерами (необязательно мы можем остановиться в середине, зависит от минимального числа элементов, которые мы хотим в каждом кластере) на каждом шагу. Это просто противоположность агломерационной кластеризации, и это нисходящий подход. Разделительная кластеризация - это способ повторения k означает кластеризацию.
Выбор между агломеративной и разделительной кластеризацией опять-таки зависит от приложения, но следует учитывать несколько моментов:
- Разделение сложнее, чем агломерационная кластеризация.
- Разделительная кластеризация более эффективна, если мы не создадим полную иерархию вплоть до отдельных точек данных.
- Агломерационная кластеризация принимает решение с учетом локальных шаблонов, не принимая во внимание глобальные паттерны, которые изначально нельзя изменить.
Визуализация иерархической кластеризации
Супер полезным методом для визуализации иерархической кластеризации, которая помогает в бизнесе, является Дендограмма. Дендограммы - это древовидные структуры, которые записывают последовательность слияний и расщеплений, в которой вертикальная линия представляет расстояние между кластерами, расстояние между вертикальными линиями и расстояние между кластерами прямо пропорционально, т.е. чем больше расстояние, тем больше кластеров, вероятно, будет неодинаковым.
Мы можем использовать дендограмму, чтобы определить количество кластеров, просто нарисуйте линию, которая пересекается с самой длинной вертикальной линией на дендограмме, количество пересеченных вертикальных линий будет количеством рассматриваемых кластеров.
Ниже приведен пример дендограммы.
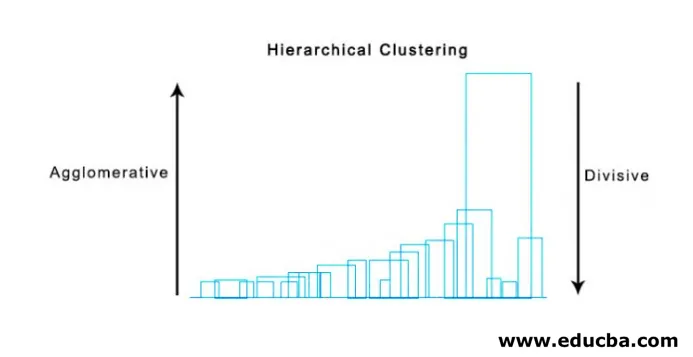
Существуют довольно простые и прямые пакеты python и его функции для выполнения иерархической кластеризации и построения дендограмм.
- Иерархия от Сципи.
- Cluster.hierarchy.dendogram для визуализации.
Общие сценарии, в которых используется иерархическая кластеризация
- Сегментация клиентов по маркетингу продуктов или услуг.
- Планирование города для определения мест для строительства конструкций / услуг / строительства.
- Анализ социальной сети, например, выявил всех фанатов MS Dhoni для рекламы его биографического фильма.
Преимущества иерархической кластеризации
Преимущества приведены ниже:
- В случае частичной кластеризации, такой как k-средних, число кластеров должно быть известно до кластеризации, что невозможно в практических приложениях, тогда как при иерархической кластеризации предварительное знание количества кластеров не требуется.
- Иерархическая кластеризация выводит иерархию, то есть структуру, более информативную, чем неструктурированный набор плоских кластеров, возвращаемых частичной кластеризацией.
- Иерархическая кластеризация проста в реализации.
- Выводит результаты в большинстве сценариев.
Вывод
Тип кластеризации имеет большое значение при представлении данных, поскольку иерархическая кластеризация более информативна и проста для анализа, более предпочтительна, чем частичная кластеризация. И это часто связано с тепловыми картами. Не забывайте, что атрибуты, выбранные для расчета сходства или различий, преимущественно влияют как на кластеры, так и на иерархию.
Рекомендуемые статьи
Это руководство по иерархической кластеризации. Здесь мы обсудим введение, преимущества иерархической кластеризации и общие сценарии, в которых используется иерархическая кластеризация. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Алгоритм кластеризации
- Кластеризация в машинном обучении
- Иерархическая кластеризация в R
- Методы кластеризации
- Как убрать иерархию в таблице?