
Введение в обратную ликвидацию
По мере того, как человек и машина стремятся к цифровой эволюции, различные технические машины становятся не только обученными, но и умно обученными для лучшего распознавания объектов реального мира. Такая техника, представленная ранее, называлась «Обратное устранение», которая предназначалась для поддержки необходимых функций при одновременном устранении обязательных функций для обеспечения лучшей оптимизации в машине. Весь уровень распознавания объектов машиной пропорционален возможностям, которые он рассматривает.
Элементы, не имеющие отношения к прогнозируемому результату, должны быть выгружены из машины, и это завершается обратным устранением. Хорошая Точность и временная сложность распознавания Машиной любого объекта реального слова зависят от его обучения. Таким образом, обратное устранение играет свою жесткую роль для выбора характеристик. Он рассчитывает степень зависимости признаков от зависимой переменной, находит значимость ее принадлежности в модели. Чтобы подтвердить это, он проверяет рассчитанную скорость со стандартным уровнем значимости (скажем, 0, 06) и принимает решение для выбора функции.
Почему мы влекем за собой обратную ликвидацию ?
Необязательные и избыточные черты способствуют сложности машинной логики. Это пожирает время и ресурсы модели без необходимости. Таким образом, вышеупомянутая техника играет компетентную роль, чтобы выковать модель из простого. Алгоритм культивирует лучшую версию модели, оптимизируя ее производительность и сокращая расходуемые назначенные ресурсы.
Это ограничивает наименее примечательные особенности модели, которые вызывают шум при определении линии регрессии. Нерелевантные признаки объекта могут привести к неправильной классификации и прогнозированию. Нерелевантные особенности объекта могут представлять собой дисбаланс в модели по сравнению с другими существенными характеристиками других объектов. Устранение в обратном направлении способствует подгонке модели к лучшему случаю. Следовательно, обратное исключение рекомендуется использовать в модели.
Как применить обратную ликвидацию?
Обратное исключение начинается со всех переменных признака, проверяя его с зависимой переменной в соответствии с выбранным критерием модели. Это начинает уничтожать те переменные, которые ухудшают подходящую линию регрессии. Повторять это удаление до тех пор, пока модель не подойдет. Ниже приведены шаги для практики обратной ликвидации:
Шаг 1: Выберите соответствующий уровень значимости для модели машины. (Возьмите S = 0, 06)
Шаг 2: Подайте все доступные независимые переменные в модель с учетом зависимой переменной и вычислите наклон и точку пересечения, чтобы нарисовать линию регрессии или подгонки.
Шаг 3: Обходите все независимые переменные, которые имеют наибольшее значение (Take I), один за другим и переходите к следующему тосту:
а) Если I> S, выполнить 4-й шаг.
б) Остальное прервать и модель идеальна.
Шаг 4: Удалите эту выбранную переменную и увеличьте обход.
Шаг 5: Снова подделать модель и снова вычислить наклон и пересечение линии подгонки с остаточными переменными.
Вышеупомянутые этапы сводятся к отклонению тех признаков, уровень значимости которых выше выбранного значения значимости (0, 06), чтобы избежать чрезмерной классификации и чрезмерного использования ресурсов, которые наблюдаются как высокая сложность.
Достоинства и недостатки обратной ликвидации
Вот некоторые достоинства и недостатки обратного устранения, приведенные ниже подробно:
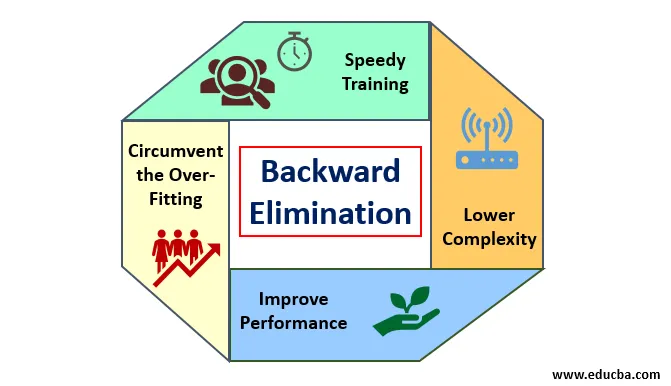
1. Достоинства
Преимущества обратной ликвидации заключаются в следующем:
- Быстрое обучение: Машина обучается с использованием набора доступных функций шаблона, который выполняется за очень короткое время, если из модели удалены ненужные функции. Быстрое обучение набора данных проявляется только тогда, когда модель имеет дело со значительными характеристиками и исключает все шумовые переменные. Это привлекает простую сложность для обучения. Но модель не должна подвергаться недостаточной подгонке, которая возникает из-за отсутствия особенностей или неадекватных образцов. Выборочная особенность должна быть многочисленной в модели для лучшей классификации. Время, необходимое для обучения модели, должно быть меньше при сохранении точности классификации и оставлено без переменной недоказания.
- Более низкая сложность: сложность модели оказывается высокой, если модель учитывает степень характеристик, включая шум и несвязанные функции. Модель занимает много места и времени для обработки такого набора функций. Это может повысить степень точности распознавания образов, но она также может содержать шум. Чтобы избавиться от такой высокой сложности модели, алгоритм обратного исключения играет необходимую роль, убирая нежелательные функции из модели. Это упрощает логику обработки модели. Лишь несколько существенных функций достаточно для того, чтобы получить хорошее соответствие, удовлетворяющее разумной точности.
- Повышение производительности: производительность модели зависит от многих аспектов. Модель подвергается оптимизации с использованием обратной ликвидации. Оптимизация модели - это оптимизация набора данных, используемого для обучения модели. Производительность модели прямо пропорциональна скорости ее оптимизации, которая зависит от частоты значимых данных. Процесс обратного исключения не предназначен для запуска изменений от любого низкочастотного предиктора. Но он только начинает изменяться с высокочастотных данных, потому что в большей степени сложность модели зависит от этой части.
- Обход перегонки: Ситуация переборки возникает, когда модель получает слишком много наборов данных, и проводится классификация или прогноз, в которых некоторые предикторы получают шум от других классов. В этой примерке модель должна давать неожиданно высокую точность. В случае чрезмерной подгонки модель может не классифицировать переменную из-за путаницы, созданной в логике из-за слишком большого числа условий. Техника обратного устранения исключает постороннюю особенность, чтобы обойти ситуацию чрезмерной подгонки.
2. Недостатки
Недостатки обратной ликвидации следующие:
- В методе обратного исключения невозможно выяснить, какой предиктор отвечает за отклонение другого предиктора из-за его значимости. Например, если предикатор X имеет какое-то значение, которое было достаточно хорошим, чтобы находиться в модели после добавления предикатора Y. Но значение X устаревает, когда в модель входит другой предиктор Z. Таким образом, в алгоритме обратного исключения не видно какой-либо зависимости между двумя предикторами, которая возникает в «методе прямого выбора».
- После отбрасывания любого признака из модели с помощью алгоритма обратного исключения, этот признак не может быть выбран снова. Короче говоря, обратное исключение не имеет гибкого подхода для добавления или удаления признаков / предикторов.
- Нормы выбора значения значимости (0, 06) в модели негибки. Обратное исключение не имеет гибкой процедуры, позволяющей не только выбирать, но и изменять незначительное значение, как требуется, для получения наилучшего соответствия при адекватном наборе данных.
Вывод
Метод обратного исключения реализован для улучшения производительности модели и оптимизации ее сложности. Он ярко используется во множественных регрессиях, где модель имеет дело с обширным набором данных. Это простой и простой подход по сравнению с прямым выбором и перекрестной проверкой, в которых встречается перегрузка оптимизации. Техника обратного устранения инициирует устранение признаков более высокой значимости. Его основная цель - сделать модель менее сложной и запретить переопределение ситуации.
Рекомендуемые статьи
Это руководство по обратной ликвидации. Здесь мы обсуждаем, как применять обратную ликвидацию наряду с достоинствами и недостатками. Вы также можете посмотреть следующие статьи, чтобы узнать больше
- Гиперпараметр машинного обучения
- Кластеризация в машинном обучении
- Виртуальная машина Java
- Неуправляемое машинное обучение