
Введение в Bagging и Boosting
Bagging и Boosting - это два популярных метода ансамбля. Поэтому, прежде чем разбираться в Bagging и Boosting, давайте разберемся, что такое ансамбль обучения. Это методика использования нескольких алгоритмов обучения для обучения моделей с одним и тем же набором данных для получения прогноза в машинном обучении. После получения прогноза от каждой модели мы будем использовать методы усреднения модели, такие как средневзвешенное значение, дисперсия или максимальное голосование, чтобы получить окончательный прогноз. Этот метод направлен на получение более точных прогнозов, чем индивидуальная модель. Это приводит к большей точности, избегая переоснащения и уменьшает смещение и ко-дисперсию. Два популярных метода ансамбля:
- Bagging (Bootstrap Aggregating)
- стимулирование
Bagging:
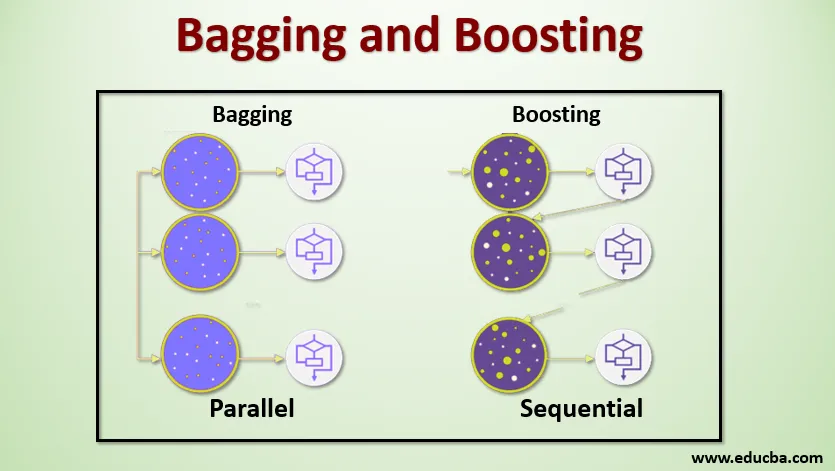
Пакетирование, также известное как Bootstrap Aggregating, используется для повышения точности и делает модель более обобщенной, уменьшая дисперсию, то есть избегая переобучения. В этом мы возьмем несколько подмножеств обучающего набора данных. Для каждого подмножества мы берем модель с такими же алгоритмами обучения, как дерево решений, логистическая регрессия и т. Д., Чтобы предсказать выходные данные для того же набора тестовых данных. Получив прогноз от каждой модели, мы используем метод усреднения моделей, чтобы получить окончательный результат прогнозирования. Одним из известных методов, используемых в Bagging, является Random Forest . В Случайном лесу мы используем несколько деревьев решений.
Повышение :
Повышение в основном используется для уменьшения систематической ошибки и дисперсии в контролируемой технике обучения. Это относится к семейству алгоритмов, которые преобразуют слабых учеников (базовый ученик) в сильных учеников. Слабый ученик - это классификаторы, которые верны лишь в небольшой степени по отношению к фактической классификации, в то время как сильные ученики - это классификаторы, которые хорошо коррелируют с фактической классификацией. Несколько известных методов повышения - это AdaBoost, GRADIENT BOOSTING, XgBOOST (экстремальное повышение градиента). Итак, теперь мы знаем, что такое пакетирование и повышение и каковы их роли в машинном обучении.
Обработка мешков и повышение
Теперь давайте разберемся, как работает багинг и бустинг:
мешковина
Чтобы понять, как работает Bagging, предположим, что у нас есть N моделей и набор данных D. Где m - это количество данных, а n - это количество объектов в каждой информации. И мы должны делать бинарную классификацию. Сначала мы разделим набор данных. Сейчас мы разделим этот набор данных только на обучающие и тестовые наборы. Давайте назовем набор обучающих данных как общее количество обучающих примеров.
Возьмите образец записей из учебного набора и используйте его для обучения первой модели, скажем, m1. Для следующей модели, м2 повторно сэмплируйте тренировочный набор и возьмите другой образец с тренировочного набора. Мы сделаем то же самое для N моделей. Поскольку мы производим повторную выборку обучающего набора данных и отбираем из него выборки, не удаляя ничего из набора данных, возможно, у нас есть две или более записи обучающих данных, общих для нескольких выборок. Этот метод повторной выборки обучающего набора данных и предоставления образца в модель называется «Выборка строк с заменой». Предположим, что мы обучили каждую модель, и теперь мы хотим увидеть прогноз на тестовых данных. Поскольку мы работаем над двоичной классификацией, выходные данные могут быть 0 или 1. Тестовый набор данных передается каждой модели, и мы получаем прогноз из каждой модели. Скажем, из N моделей более N / 2 моделей предсказали, что оно равно 1, следовательно, используя метод усреднения моделей, такой как максимальное голосование, мы можем сказать, что прогнозируемый результат для тестовых данных равен 1.
стимулирование
В процессе повышения мы берем записи из набора данных и последовательно передаем их базовым обучающимся, здесь базовыми обучаемыми может быть любая модель. Предположим, у нас есть m записей в наборе данных. Затем мы передаем несколько записей базовому ученику BL1 и обучаем его. Как только BL1 обучается, мы передаем все записи из набора данных и видим, как работает базовый учащийся. Для всех записей, которые неправильно классифицированы базовым учеником, мы только берем их и передаем другому базовому ученику, скажем, BL2, и одновременно мы передаем неверные записи, классифицированные BL2, для обучения BL3. Это будет продолжаться до тех пор, пока мы не укажем определенное количество базовых моделей учащихся, которые нам нужны. Наконец, мы объединяем результаты этих базовых учеников и создаем сильного ученика, в результате чего сила предсказания модели улучшается. Ok. Итак, теперь мы знаем, как работают Bagging и Boosting.
Преимущества и недостатки упаковки и повышения
Ниже приведены основные преимущества и недостатки.
Преимущества Bagging
- Самым большим преимуществом упаковки является то, что несколько слабых учеников могут работать лучше, чем один сильный ученик.
- Это обеспечивает стабильность и повышает точность алгоритма машинного обучения, который используется в статистической классификации и регрессии.
- Это помогает в уменьшении дисперсии, то есть избегает переоснащения.
Недостатки Bagging
- Это может привести к большому смещению, если оно не смоделировано должным образом, и, следовательно, может привести к недостаточному подгонке.
- Поскольку мы должны использовать несколько моделей, это становится вычислительно дорогостоящим и может не подходить в различных случаях использования.
Преимущества повышения
- Это один из наиболее успешных методов решения задач классификации двух классов.
- Хорошо справляется с отсутствующими данными.
Недостатки повышения
- Повышение трудно реализовать в режиме реального времени из-за повышенной сложности алгоритма.
- Высокая гибкость этого метода приводит к множеству параметров, которые напрямую влияют на поведение модели.
Вывод
Основной вывод заключается в том, что Bagging и Boosting - это парадигма машинного обучения, в которой мы используем несколько моделей для решения одной и той же проблемы и повышения производительности. И если мы правильно объединяем слабых учеников, мы можем получить стабильную, точную и надежную модель. В этой статье я дал общий обзор Bagging и Boosting. В следующих статьях вы познакомитесь с различными методами, используемыми в обеих. Наконец, я в заключение напомню, что Bagging и Boosting являются одними из наиболее часто используемых методов обучения ансамбля. Настоящее искусство повышения производительности заключается в вашем понимании того, когда использовать какую модель и как настраивать гиперпараметры.
Рекомендуемые статьи
Это руководство по Bagging и Boosting. Здесь мы обсуждаем Введение в Bagging и Boosting, и оно работает вместе с преимуществами и недостатками. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Введение в техники ансамбля
- Категории алгоритмов машинного обучения
- Алгоритм повышения градиента с примером кода
- Что такое алгоритм повышения?
- Как создать дерево решений?