

Введение в методы науки о данных
В современном мире, где данные - это новое золото, для бизнеса доступны различные виды анализа. Результат проекта по науке о данных сильно зависит от типа доступных данных, и, следовательно, его влияние также является переменной величиной. Поскольку существует много различных видов анализа, становится необходимым понять, какие методы базовой линии необходимо выбрать. Основной целью методов науки о данных является не только поиск релевантной информации, но и выявление слабых звеньев, которые, как правило, ухудшают производительность модели.
Что такое наука о данных?
Наука о данных - это область, которая охватывает несколько дисциплин. Он включает в себя научные методы, процессы, алгоритмы и системы для сбора знаний и работы над ними. Эта область включает в себя различные жанры и является общей платформой для объединения концепций статистики, анализа данных и машинного обучения. При этом теоретические знания статистики, а также данные в реальном времени и методы машинного обучения работают рука об руку, чтобы получить плодотворные результаты для бизнеса. Используя различные методы, применяемые в науке о данных, мы в современном мире можем предложить лучшее принятие решений, которые иначе могли бы не заметить человеческий глаз и разум. Помните, машина никогда не забудет! Чтобы максимизировать прибыль в мире, управляемом данными, магия Data Science - необходимый инструмент.
Различные типы техники данных науки
В следующих нескольких параграфах мы рассмотрим общие методы обработки данных, используемые в любом другом проекте. Хотя иногда техника обработки данных может быть специфичной для конкретной бизнес-задачи и может не попадать в перечисленные ниже категории, вполне нормально называть их разными типами. На высоком уровне мы разделяем методы на контролируемые (мы знаем целевое воздействие) и неконтролируемые (мы не знаем о целевой переменной, которую мы пытаемся достичь). На следующем уровне методы могут быть разделены с точки зрения
- Результат, который мы получили бы, или какова цель проблемы бизнеса
- Тип используемых данных.
Давайте сначала посмотрим на сегрегацию, основанную на намерении.
1. Обучение без учителя
- Обнаружение аномалий
В этом типе техники мы идентифицируем любое неожиданное появление во всем наборе данных. Поскольку поведение отличается от фактического использования данных, основными предположениями являются:
- Встречаемость этих случаев очень мала по количеству.
- Разница в поведении значительна.
Объясняются алгоритмы аномалий, такие как Лес изоляции, который обеспечивает оценку для каждой записи в наборе данных. Этот алгоритм является древовидной моделью. Используя этот тип метода обнаружения и его популярность, они используются в различных бизнес-ситуациях, например, при просмотре веб-страниц, уровне оттока, доходе за клик и т. Д. На приведенном ниже графике мы можем объяснить, как выглядит аномалия.
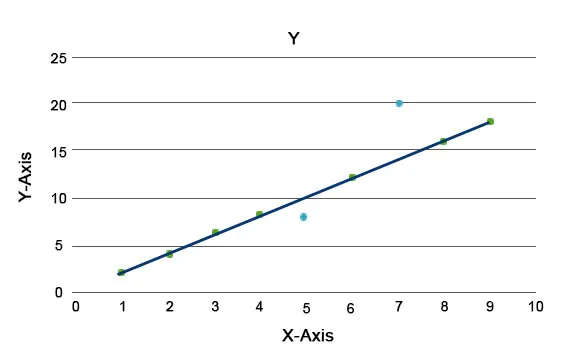
Здесь синие представляют аномалию в наборе данных. Они отличаются от обычной линии тренда и встречаются реже.
- Кластерный анализ
Посредством этого анализа основная задача состоит в том, чтобы разделить весь набор данных на группы так, чтобы тренд или черты в точках данных одной группы были очень похожи друг на друга. В терминологии данных науки мы называем их кластером. Например, в розничном бизнесе существует план по масштабированию бизнеса, и становится необходимым знать, как поведут себя новые клиенты в новом регионе, основываясь на прошлых данных, которые мы имеем. Становится невозможным разработать стратегию для каждого индивидуума в популяции, но будет полезно объединить население в кластеры, чтобы стратегия была эффективной в группе и была масштабируемой.
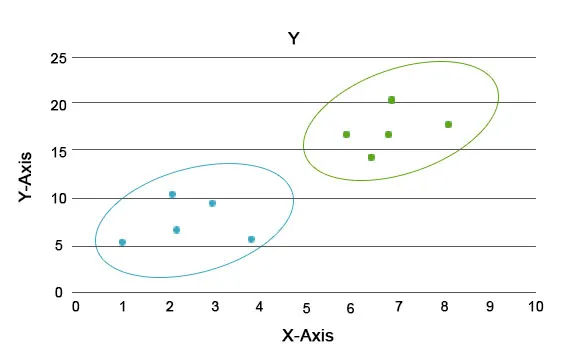
Здесь синий и оранжевый цвета - это разные скопления, имеющие уникальные черты внутри себя.
- Анализ Ассоциации
Этот анализ помогает нам в создании интересных отношений между элементами в наборе данных. Этот анализ раскрывает скрытые отношения и помогает в представлении элементов набора данных в форме правил ассоциации или наборов частых элементов. Правило ассоциации разбито на 2 этапа:
- Генерация набора частых элементов : в этом случае создается набор, в котором часто встречающиеся элементы создаются вместе.
- Генерация правил: Набор, созданный выше, проходит через различные уровни формирования правил, чтобы построить скрытые отношения между собой. Например, набор может попадать либо в концептуальные проблемы, либо в проблемы реализации, либо в проблемы приложения. Затем они разветвляются в соответствующих деревьях для построения правил ассоциации.
Например, APRIORI - это алгоритм построения правил ассоциации.
2. Контролируемое обучение
- Регрессивный анализ
В регрессионном анализе мы определяем зависимую / целевую переменную и оставшиеся переменные как независимые переменные и в конечном итоге выдвигаем гипотезу о том, как одна / несколько независимых переменных влияют на целевую переменную. Регрессия с одной независимой переменной называется одномерной, а с более чем одной - многомерной. Давайте разберемся, используя одномерный, а затем масштабируемый для многовариантного.
Например, y является целевой переменной, а x 1 является независимой переменной. Итак, из знания прямой мы можем записать уравнение как y = mx 1 + c. Здесь «m» определяет, насколько сильно на y влияет x 1 . Если «m» очень близко к нулю, это означает, что при изменении x 1, y сильно не изменяется. Если число больше 1, влияние усиливается, и небольшое изменение x 1 приводит к значительному изменению y. Подобно одномерному, в многомерном можно записать как y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Здесь влияние каждой независимой переменной определяется ее соответствующим «m».
- Классификационный анализ
Подобно кластерному анализу, построены алгоритмы классификации, имеющие целевую переменную в форме классов. Разница между кластеризацией и классификацией заключается в том, что при кластеризации мы не знаем, к какой группе относятся точки данных, тогда как при классификации мы знаем, к какой группе они принадлежат. И это отличается от регрессии с точки зрения того, что число групп должно быть фиксированным числом, в отличие от регрессии, оно непрерывно. Существует несколько алгоритмов в классификационном анализе, например, машины опорных векторов, логистическая регрессия, деревья решений и т. Д.
Вывод
В заключение, мы понимаем, что каждый тип анализа сам по себе огромен, но здесь мы можем дать небольшое представление о различных методах. В следующих нескольких заметках мы рассмотрим каждую из них по отдельности и подробно рассмотрим различные подтехники, применяемые в каждой родительской технике.
Рекомендуемая статья
Это руководство по технике наук о данных. Здесь мы обсуждаем введение и различные типы методов в науке о данных. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Инструменты Науки Данных | Лучшие 12 инструментов
- Алгоритмы Науки Данных с Типами
- Введение в Data Science Career
- Наука о данных против визуализации данных
- Примеры многомерной регрессии
- Создать дерево решений с преимуществами
- Краткий обзор Data Science Lifecycle