

Обзор приложений Kafka
Одно из самых популярных направлений в ИТ-индустрии - «Большие данные», где компания работает с большим количеством данных о клиентах и получает полезные сведения, которые помогают их бизнесу и обеспечивают клиентам лучший сервис. Одна из проблем заключается в обработке и передаче этих больших объемов данных с одного конца на другой для анализа или обработки. Именно здесь вступает в игру Кафка (надежная система обмена сообщениями), которая помогает в сборе и транспортировке огромного объема данных. в реальном времени. Kafka разработан для распределенных систем с высокой пропускной способностью и хорошо подходит для крупномасштабных приложений обработки сообщений. Kafka поддерживает многие из лучших на сегодняшний день коммерческих и промышленных приложений. Существует потребность в профессионалах Kafka, имеющих сильные навыки и практические знания.
В этой статье мы узнаем о Kafka, его функциях, сценариях использования и разберемся с некоторыми известными приложениями, где он используется.
Что такое Кафка?
Apache Kafka был разработан в LinkedIn и позже стал проектом Apache с открытым исходным кодом. Apache Kafka - это быстрая, отказоустойчивая, масштабируемая и распределенная система обмена сообщениями, которая обеспечивает связь между двумя объектами, то есть между производителями (генератором сообщений) и потребителями (получателями сообщений), используя темы, основанные на сообщениях, и предоставляет платформу для управления всеми каналы данных в реальном времени.
Функциональные возможности, которые делают Apache Kafka лучше других систем обмена сообщениями и применимы к системам реального времени, - это высокая доступность, немедленное автоматическое восстановление после сбоев узлов и поддержка доставки сообщений с низкой задержкой. Эти функции Apache Kafka помогают интегрировать его с крупномасштабными системами данных и делают его идеальным компонентом для коммуникации. 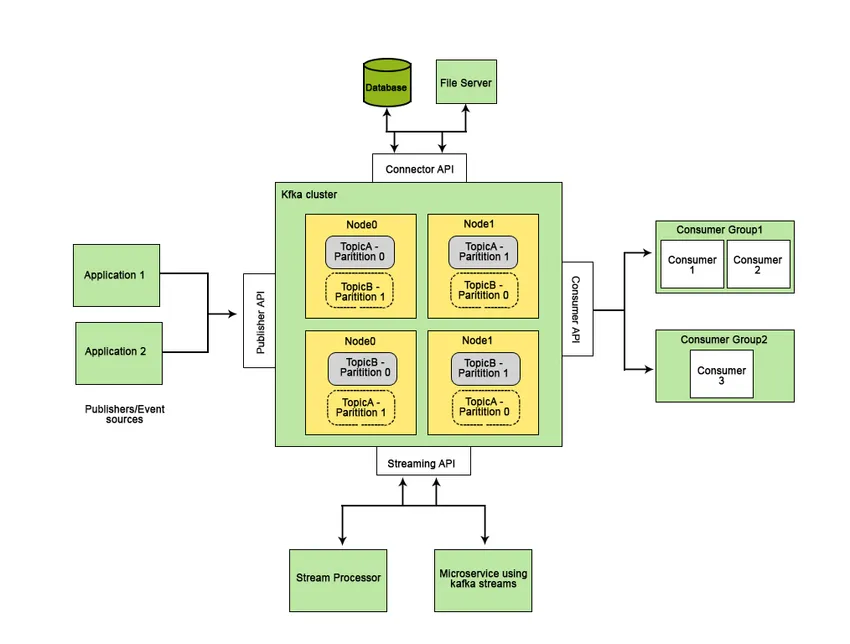
Лучшие приложения Kafka
В этом разделе статьи мы рассмотрим некоторые популярные и широко реализованные варианты использования, а также познакомимся с реальной реализацией Kafka.
Реальные приложения
1. Twitter: потоковая обработка
Twitter - это социальная сетевая платформа, которая использует Storm-Kafka (инструмент обработки потоков с открытым исходным кодом) как часть своей инфраструктуры потоковой обработки, где входные данные (твиты) используются для агрегирования, преобразования и обогащения для дальнейшего использования или последующей деятельности. перерабатывающая деятельность.
2. LinkedIn: обработка потоков и метрики
LinkedIn использует Kafka для потоковой передачи данных и для оперативных показателей деятельности. LinkedIn использует Kafka для своих дополнительных функций, таких как Newsfeed, для потребления сообщений и выполнения анализа полученных данных.
3. Netflix: мониторинг в реальном времени и обработка потоков
Netflix имеет собственную среду приема, которая выводит входные данные в AWS S3 и использует Hadoop для запуска аналитики видеопотоков, действий пользовательского интерфейса, событий для улучшения взаимодействия с пользователем и Kafka для приема данных в режиме реального времени через API.
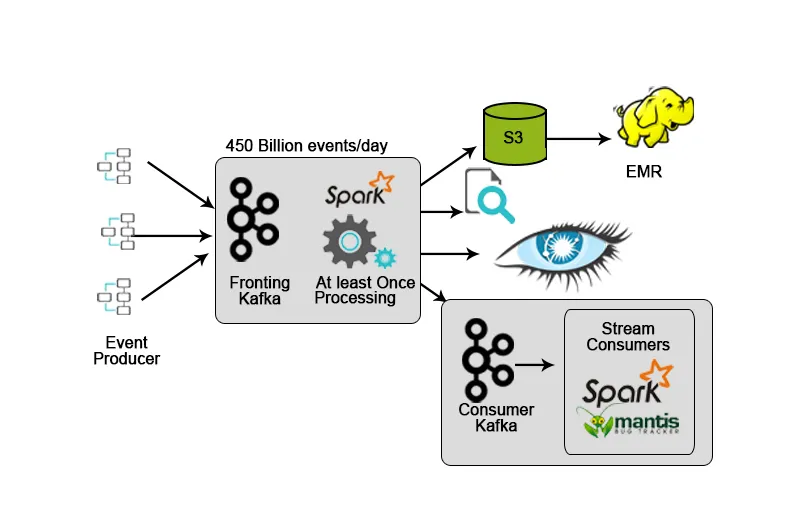
4. Hotstar: обработка потоков
Hotstar представила собственную платформу управления данными - Bifrost, где Kafka используется для потоковой передачи данных, мониторинга и отслеживания целей. Благодаря своей масштабируемости, доступности и возможностям с малой задержкой, Kafka был идеальным выбором для обработки данных, которые платформа hotstar генерирует ежедневно или по любому особому случаю (прямая трансляция любых концертов, любой живой спортивный матч и т. Д.), Где объем данных значительно увеличивается.
Apache Kafka большую часть времени используется как строительный блок для разработки архитектуры потоковых данных. Этот тип архитектуры используется в таких приложениях, как сбор журналов продуктов / серверов, анализ потока кликов и получение информации из данных, сгенерированных машиной.
Но наряду с Kafka нам необходимо использовать дополнительные ресурсы или инструменты для преобразования полученного потока данных в значимые данные, которые помогают получить понимание, которое можно использовать при принятии решений на основе данных. Например, нам может потребоваться получить информацию из необработанных данных, полученных с устройств IoT, или данных, полученных с платформ социальных сетей в режиме реального времени, а также выполнить некоторый анализ или обработку и продемонстрировать их бизнесу для принятия более эффективных решений или оказания помощи в улучшении. выполнение своих услуг.
Для этих типов использования мы хотели бы направить наши входные данные / необработанные данные в озеро данных, где мы можем хранить наши данные и гарантировать качество данных без ущерба для производительности.
Другая ситуация, мы можем считывать данные непосредственно из Kafka, это когда нам нужна чрезвычайно низкая сквозная задержка, например, подача данных в приложения реального времени.
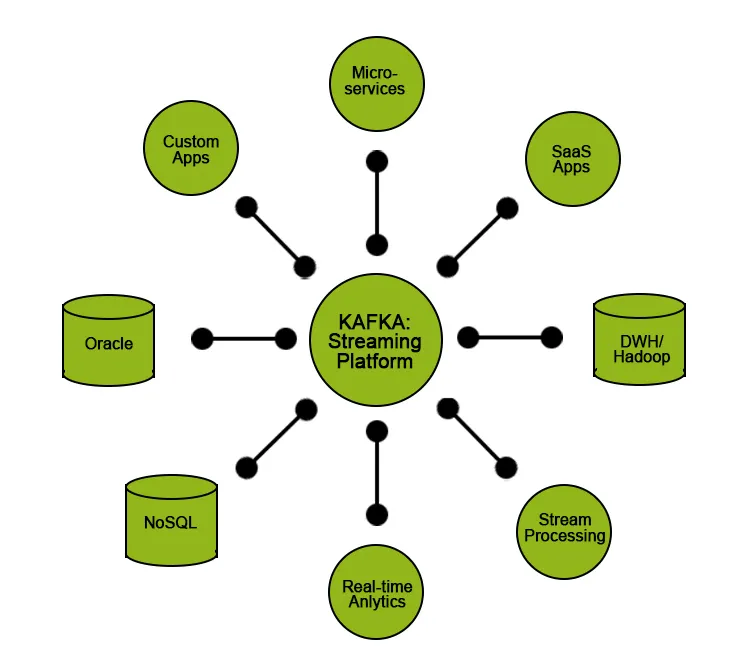
Kafka предоставляет пользователям определенные функции:
- Публикуйте и подписывайтесь на данные.
- Храните данные в том порядке, в котором они были сгенерированы.
- Обработка данных в реальном времени / на лету.
Кафка большую часть времени используется для:
- Реализация потоковых конвейеров данных на лету, которые надежно получают данные между двумя объектами в системе.
- Реализация потоковых приложений на лету, которые преобразуют, обрабатывают или обрабатывают потоки данных.
Случаи использования
Ниже приведены некоторые широко используемые примеры использования приложения Kafka:
1. Обмен сообщениями
Kafka работает лучше, чем другие традиционные системы обмена сообщениями, такие как ActiveMQ, RabbitMQ и т. Д. Для сравнения, Kafka предлагает лучшую пропускную способность, встроенные средства разбиения, возможности репликации и отказоустойчивости, что делает ее лучшей системой обмена сообщениями для крупномасштабных приложений обработки.,
2. Отслеживание активности сайта
Пользовательские действия (просмотры страниц, поиск или любые выполненные действия) могут отслеживаться и передаваться для мониторинга или анализа в режиме реального времени через Kafka или с помощью Kafka для хранения данных такого рода в Hadoop или хранилище данных для последующей обработки или манипулирования. Отслеживание активности генерирует огромное количество данных, которые необходимо перенести в нужное место без какой-либо потери данных.
3. Регистрация агрегации
Агрегация журналов - это процесс сбора / объединения физических файлов журналов с разных серверов приложения в единый репозиторий (файловый сервер или HDFS) для обработки. Kafka предлагает хорошую производительность, меньшую сквозную задержку по сравнению с Flume.

Вывод
Kafka интенсивно используется в пространстве больших данных как способ очень быстрого приема и перемещения больших объемов данных благодаря своим характеристикам производительности и функциям, которые помогают в достижении масштабируемости, надежности и устойчивости. В этой статье мы обсудили Apache Kafka, его возможности, варианты использования и приложения, а также то, что делает его лучшим инструментом для потоковой передачи данных.
Рекомендуемые статьи
Это руководство к приложениям Kafka. Здесь мы обсуждаем, что такое Kafka, наряду с лучшими приложениями Kafka, которые включают широко реализованные сценарии использования и некоторые реальные реализации. Вы также можете посмотреть следующие статьи, чтобы узнать больше
- Что такое Кафка?
- Как установить Кафку?
- Кафка Интервью Вопросы
- Апач Кафка против Флюм
- Топ 8 устройств IoT, которые вы должны знать
- Кафка против Кинезис | Отличия от инфографики
- Различные типы инструментов Kafka с компонентами
- Узнайте о главных отличиях ActiveMQ от Кафки