

Разница между Hadoop и HBase
Hadoop - это среда Java с открытым исходным кодом, используемая для управления и обработки огромного количества структурированных и неструктурированных данных. Hadoop является масштабируемым, поэтому используется для обработки больших нагрузок на данные. Большие данные хранятся, доступны и обрабатываются в надежном и расширяемом кластере. HBase (база данных Hadoop) - это нереляционная и не только SQL, т.е. база данных NoSQL, которая работает на вершине Hadoop как распределенное и масштабируемое хранилище больших данных. Это база данных с открытым исходным кодом, в которой данные хранятся в виде строк и столбцов, в этой ячейке находится пересечение столбцов и строк.
Ниже приведены основные компоненты архитектуры Hadoop:
- Распределенная файловая система Hadoop (HDFS). Hadoop включает распределенную систему хранения, распределенную файловую систему Hadoop (HDFS). HDFS - это архитектура ведущий-ведомый, которая хранит данные в кластере. Данные распределяются по нескольким подчиненным узлам главным узлом в блоке формы. Главный узел называется Namenode, а подчиненные узлы называются Datanode. HDFS легко расширяется и хранит огромное количество данных на Datanodes. HDFS имеет настраиваемый коэффициент репликации со значением по умолчанию 3, которое можно редактировать.
- MapReduce: MapReduce - это парадигма программирования, параллельно обрабатывающая огромное количество наборов данных по сети. MapReduce относится к двум различным задачам: сопоставить входные данные, в которых данные, разделенные на подмножество данных, называемых кортежами, и задача сокращения берет эти кортежи с карты в качестве входных данных и объединяет их для формирования выходных данных оригинала.
- Yarn: YARN означает еще один навигатор ресурсов, вычислительные ресурсы которого, например, управляют процессором и памятью, планируют запросы ресурсов.
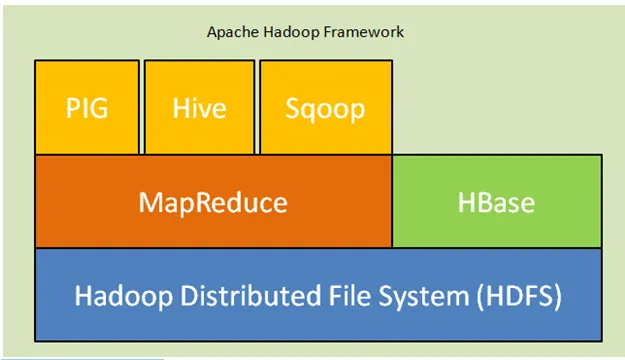
Рис. Apache Hadoop Framework
Регион-сервер обслуживает данные для операций чтения / записи. Все данные HBase хранятся в файле HDFS. HDFS Datanode хранит данные, которыми управляет Region Server. HDFS Namenode хранит информацию метаданных для всех физических блоков данных, которые составляют файлы.
Управление версиями используется для отслеживания изменений в ячейках, что позволяет отслеживать версию содержимого. Отсюда можно получить любую версию контента. Каждое значение ячейки включает атрибут 'version' относительно временной метки для извлечения ячейки. Каждое значение на карте представляет собой непрерывный массив байтов. Карта индексируется ключом строки, ключом столбца и отметкой времени. Архитектура HBase - это масштабируемые, разреженные, распределенные, постоянные и многомерные карты.
Личное сравнение между Hadoop и HBase (Инфографика)
Ниже приводится топ-7 различий между Hadoop и HBase
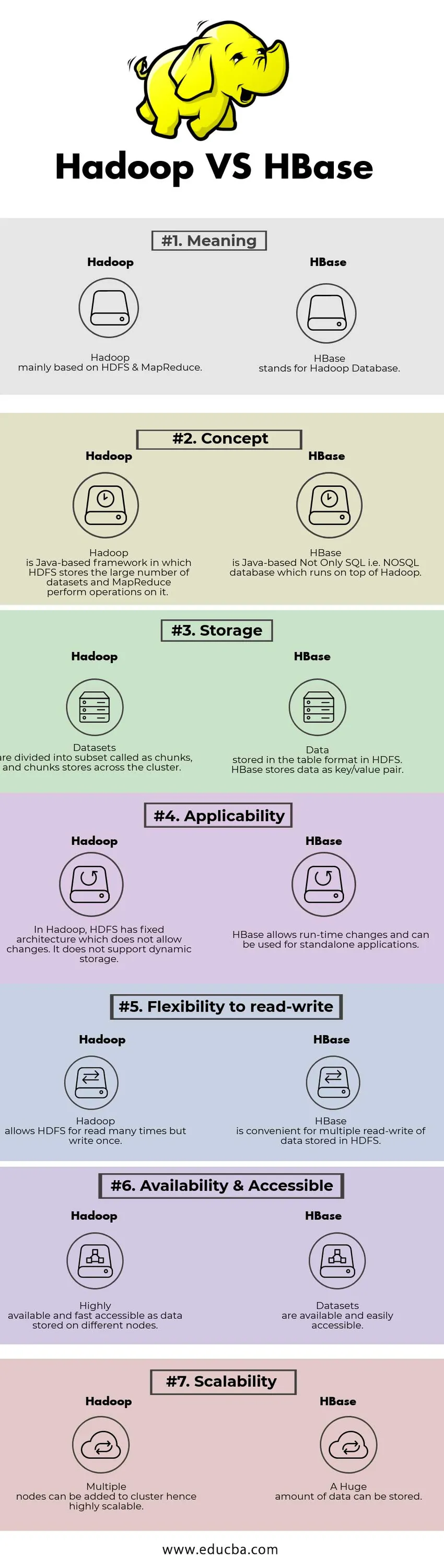
Ключевые различия между Hadoop и HBase
Разница между Hadoop и HBase объясняется в пунктах, представленных ниже:
- Hadoop не подходит для аналитической обработки в Интернете (OLAP), а HBase является частью экосистемы Hadoop, которая обеспечивает произвольный доступ в реальном времени (чтение / запись) к данным в файловой системе Hadoop.
- Структура Hadoop отказоустойчива и поддерживает быструю передачу данных между узлами даже при сбоях системы. HBase - это нереляционная база данных Not-Only-SQL с открытым исходным кодом, которая работает поверх Hadoop. HBase подпадает под теорему типа CAP (непротиворечивость, доступность и допуск раздела).
- Hadoop наиболее подходит для выполнения пакетной аналитики. Тем не менее, одним из его самых больших недостатков является неспособность проводить анализ в режиме реального времени, что является тенденцией в ИТ-индустрии. HBase, с другой стороны, может обрабатывать большие наборы данных и не подходит для пакетной аналитики. Вместо этого он используется для записи / чтения данных из Hadoop в режиме реального времени.
- Как Hadoop, так и HBase способны обрабатывать как структурированные, полуструктурированные, так и неструктурированные данные. В Hadoop HDFS не хватает механизма обработки в памяти, замедляющего процесс анализа данных; так как он использует простой старый MapReduce, чтобы сделать это. HBase, напротив, может похвастаться механизмом обработки в памяти, который резко увеличивает скорость чтения / записи.
- Hadoop очень прозрачен в выполнении анализа данных. С другой стороны, HBase, являясь базой данных NoSQL в табличном формате, извлекает значения, сортируя их по различным значениям ключа.
Сравнительная таблица Hadoop и HBase
| БАЗА ДЛЯ СРАВНЕНИЯ | Hadoop | HBase |
| Смысл | Hadoop в основном на основе HDFS и MapReduce. | HBase обозначает базу данных Hadoop. |
| концепция | Hadoop - это основанная на Java инфраструктура, в которой HDFS хранит большое количество наборов данных, а MapReduce выполняет над ней операции. | HBase - это не только SQL, основанный на Java, то есть база данных NoSQL, которая работает поверх Hadoop. |
| Место хранения | Наборы данных делятся на подмножества, называемые чанками, и чанки хранятся по всему кластеру. | Данные хранятся в табличном формате в HDFS. HBase хранит данные в виде пары ключ / значение. |
| применимость | В Hadoop HDFS имеет фиксированную архитектуру, которая не допускает изменений. Он не поддерживает динамическое хранение. | HBase позволяет вносить изменения во время выполнения и может использоваться для автономных приложений. |
| Гибкость для чтения-записи | Hadoop позволяет читать HDFS много раз, но писать один раз. | HBase удобен для многократного чтения-записи данных, хранящихся в HDFS |
| Доступность и доступность | Высокая доступность и быстрая доступность, поскольку данные хранятся на разных узлах. | Наборы данных доступны и легко доступны |
| Масштабируемость | Несколько кластеров могут быть добавлены в кластер, что обеспечивает высокую степень масштабирования. | Огромное количество данных может быть сохранено. |
Вывод - Hadoop против HBase
Архитектура Hadoop в основном основана на HDFS и MapReduce. HBase является вспомогательным компонентом в системе Hadoop. HBase способен хранить огромные таблицы и обеспечивать быстрый произвольный доступ к доступным данным, а HDFS подходит для хранения больших файлов. Как Hadoop, так и HBase обеспечивают быстрый доступ к данным, но с помощью HBase можно выполнять операции чтения / записи, а для HDFS можно выполнять многократное чтение и однократную запись. В этой статье описывается понимание Hadoop и HBase, кратко освещаются особенности и проводится тщательное сравнение.
Рекомендуемая статья
- Apache Hadoop против Apache Spark | 10 лучших сравнений, которые вы должны знать!
- Hadoop vs Hive - узнай лучшие отличия
- HBase vs Cassandra - кто лучше (Инфографика)
- 12 лучших сравнений Apache Hive и Apache HBase (Инфографика)
- Hadoop vs Spark: каковы особенности