
Линейная регрессия в Excel (Содержание)
- Введение в линейную регрессию в Excel
- Методы использования линейной регрессии в Excel
Введение в линейную регрессию в Excel
Линейная регрессия - это статистический метод / метод, используемый для изучения взаимосвязи между двумя непрерывными количественными переменными. В этом методе независимые переменные используются для прогнозирования значения зависимой переменной. Если существует только одна независимая переменная, то это простая линейная регрессия, а если число независимых переменных больше, чем одна, то это множественная линейная регрессия. Модели линейной регрессии имеют связь между зависимыми и независимыми переменными путем подгонки линейного уравнения к наблюдаемым данным. Линейный относится к тому факту, что мы используем линию, чтобы соответствовать нашим данным. Зависимые переменные, используемые в регрессионном анализе, также называют ответными или прогнозными переменными, а независимые переменные также называют объясняющими переменными или предикторами.
Линия линейной регрессии имеет уравнение вида: Y = a + bX;
Где:
- X - объясняющая переменная,
- Y является зависимой переменной,
- б - наклон линии,
- a является y-перехватом (то есть значением y, когда x = 0).
Метод наименьших квадратов обычно используется в линейной регрессии, которая рассчитывает линию наилучшего соответствия для наблюдаемых данных путем минимизации суммы квадратов отклонения точек данных от линии.
Методы использования линейной регрессии в Excel
В этом примере показано, как выполнить анализ линейной регрессии в Excel. Давайте посмотрим на несколько методов.
Вы можете скачать этот шаблон Excel с линейной регрессией здесь - Шаблон Excel с линейной регрессиейМетод № 1 - Точечная диаграмма с линией тренда
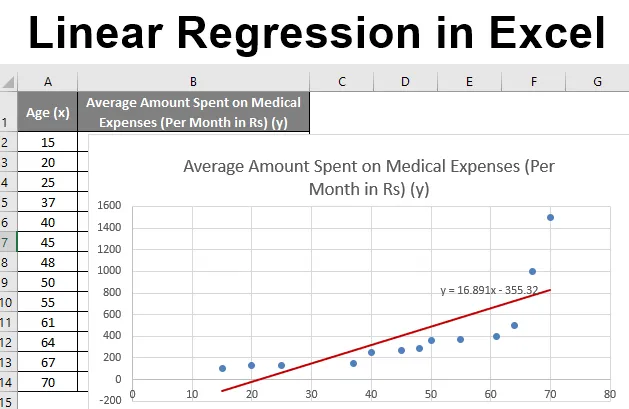
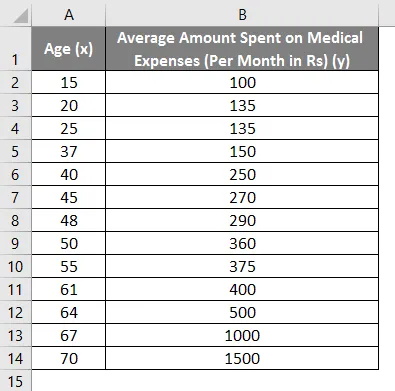
Допустим, у нас есть набор данных о некоторых людях с их возрастом, индексом биомассы (ИМТ) и суммой, потраченной ими на медицинские расходы за месяц. Теперь, имея представление о характеристиках людей, таких как возраст и ИМТ, мы хотим выяснить, как эти переменные влияют на медицинские расходы, и, следовательно, использовать их для проведения регрессии и оценки / прогнозирования средних медицинских расходов для некоторых конкретных людей. Давайте сначала посмотрим, как только возраст влияет на медицинские расходы. Давайте посмотрим на набор данных:
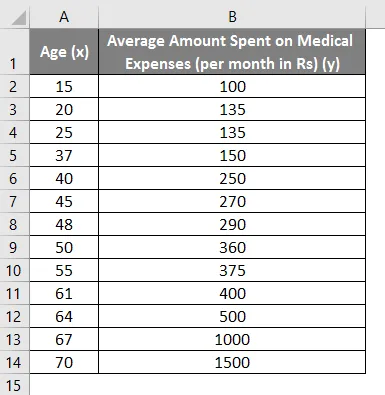
Сумма на медицинские расходы = б * возраст + а
- Выберите два столбца набора данных (x и y), включая заголовки.
- Нажмите «Вставить» и разверните раскрывающийся список «Диаграмма разброса» и выберите эскиз «Разброс» (первый)
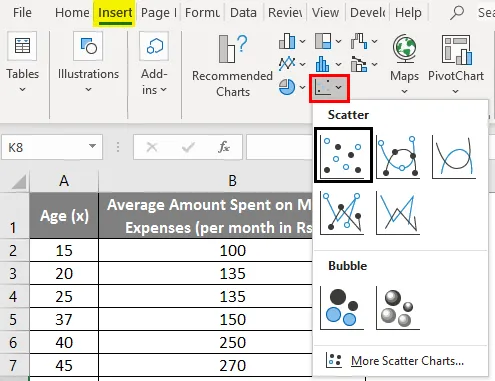
- Теперь появится график рассеяния, и мы нарисуем на этом линию регрессии. Для этого щелкните правой кнопкой мыши любую точку данных и выберите «Добавить линию тренда».
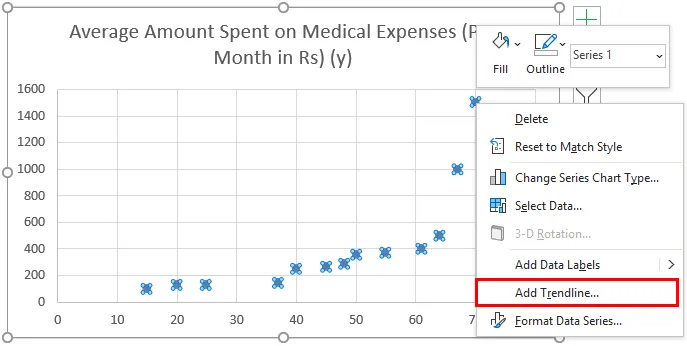
- Теперь на панели «Format Trendline» справа выберите «Linear Trendline» и «Показать уравнение на графике».
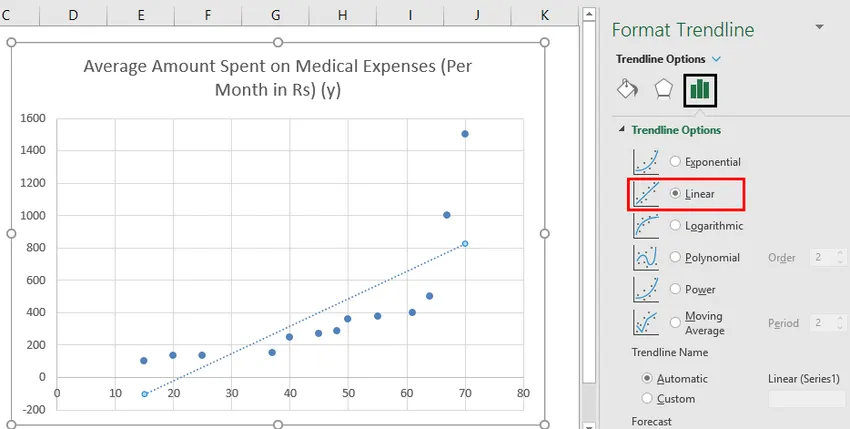
- Выберите «Показать уравнение на графике».
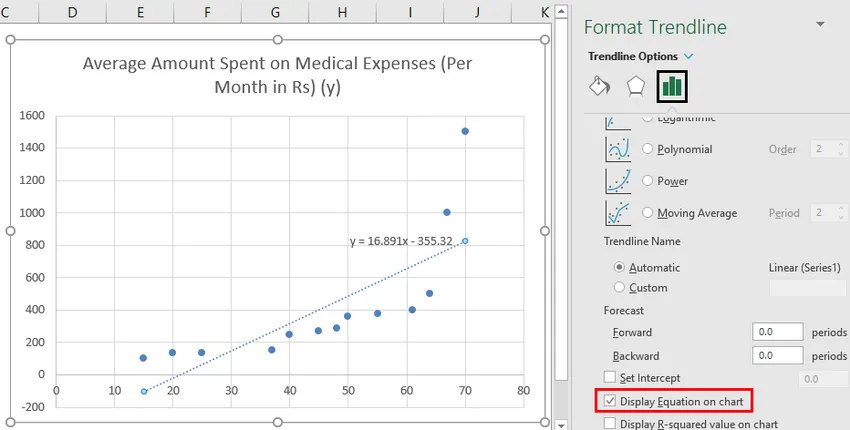
Мы можем импровизировать диаграмму в соответствии с нашими требованиями, такими как добавление названий осей, изменение масштаба, цвета и типа линии.
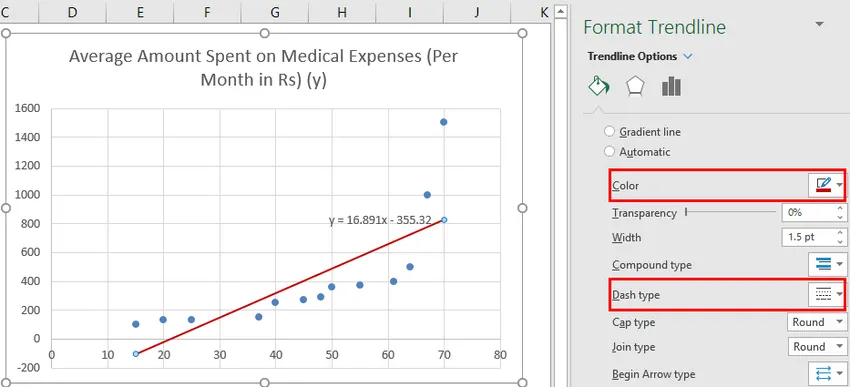
После Импровизации диаграммы мы получаем вывод.

Метод № 2 - Анализ надстройки ToolPak Метод
Пакет инструментов анализа иногда не включен по умолчанию, и нам нужно сделать это вручную. Для этого:
- Нажмите на меню «Файл».
После этого нажмите «Опции».
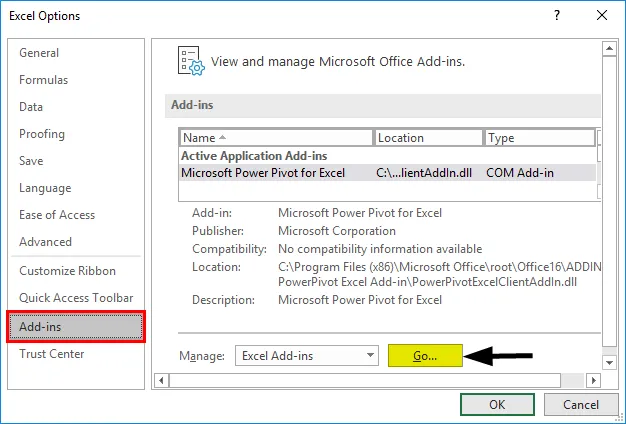
- Выберите «Надстройки Excel» в поле «Управление» и нажмите «Перейти»
- Выберите «Пакет инструментов анализа» -> «ОК»
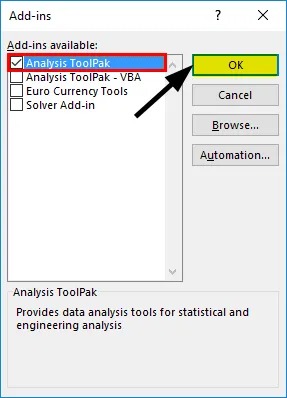
Это добавит инструменты «Анализ данных» на вкладку «Данные». Теперь запустим регрессионный анализ:
- Нажмите «Анализ данных» на вкладке «Данные»
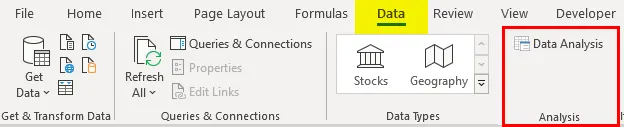
- Выберите «Регрессия» -> «ОК».
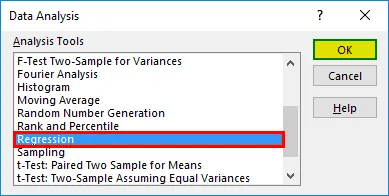
- Откроется диалоговое окно регрессии. Выберите диапазон ввода Y и диапазон ввода X (медицинские расходы и возраст соответственно). В случае множественной линейной регрессии мы можем выбрать больше столбцов независимых переменных (например, если мы хотим увидеть влияние ИМТ также на медицинские расходы).
- Установите флажок «Метки», чтобы включить заголовки.
- Выберите желаемый вариант вывода.
- Установите флажок «Остатки» и нажмите «ОК».
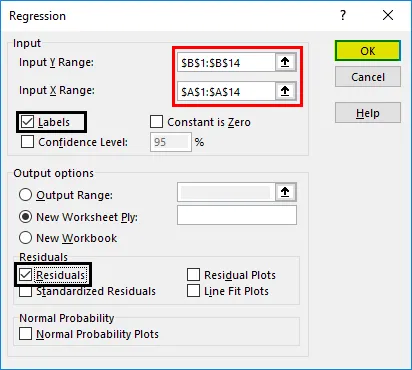
Теперь результаты нашего регрессионного анализа будут созданы в новом рабочем листе с указанием статистики регрессии, ANOVA, остатков и коэффициентов.
Выходная интерпретация:
- Статистика регрессии показывает, насколько хорошо уравнение регрессии соответствует данным:
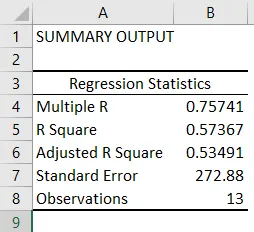
- Множество R - это коэффициент корреляции, который измеряет силу линейных отношений между двумя переменными. Он лежит в диапазоне от -1 до 1, и его абсолютное значение показывает силу отношения с большим значением, указывающим на более сильное отношение, низким значением, указывающим на отрицательное значение, и нулевым значением, указывающим на отсутствие отношения.
- Квадрат R - это коэффициент определения, используемый в качестве показателя качества соответствия. Он находится в диапазоне от 0 до 1, а значение, близкое к 1, указывает на то, что модель хорошо подходит. В этом случае 0, 57 = 57% значений y объясняются значениями x.
- Скорректированный квадрат R - это квадрат R, скорректированный на количество предикторов в случае множественной линейной регрессии.
- Стандартная ошибка отображает точность регрессионного анализа.
- Наблюдения отображают количество модельных наблюдений.
- Anova рассказывает об уровне изменчивости в рамках регрессионной модели.

Обычно это не используется для простой линейной регрессии. Однако «Значения F значимости» указывают на то, насколько надежны наши результаты, при этом значение больше 0, 05 предлагает выбрать другого предиктора.
- Коэффициенты являются наиболее важной частью, используемой для построения уравнения регрессии.

Итак, наше уравнение регрессии будет: у = 16, 891 х - 355, 32. Это то же самое, что сделано методом 1 (точечная диаграмма с линией тренда).
Теперь, если мы хотим предсказать средние медицинские расходы в возрасте 72 лет:
Итак, у = 16, 891 * 72 -355, 32 = 860, 832
Таким образом, мы можем предсказать значения y для любых других значений x.
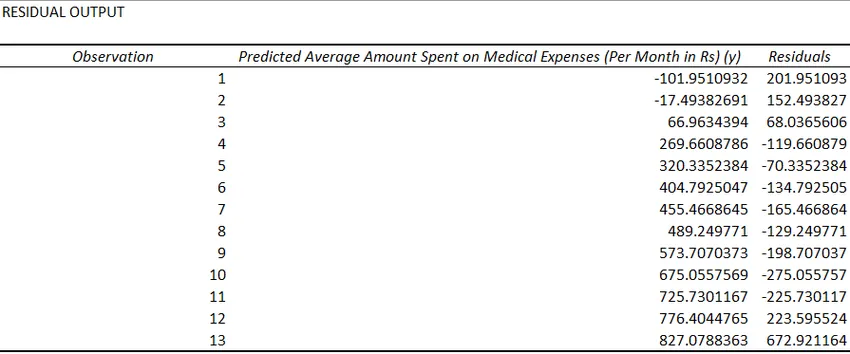
- Остатки указывают на разницу между фактическими и прогнозируемыми значениями.
Последний метод регрессии используется не так часто и требует статистических функций, таких как slope (), intercept (), correl () и т. Д. Для проведения регрессионного анализа.
Что нужно помнить о линейной регрессии в Excel
- Регрессионный анализ обычно используется для определения статистически значимой взаимосвязи между двумя наборами переменных.
- Он используется для прогнозирования значения зависимой переменной на основе значений одной или нескольких независимых переменных.
- Всякий раз, когда мы хотим приспособить модель линейной регрессии к группе данных, следует тщательно соблюдать диапазон данных, как если бы мы использовали уравнение регрессии для прогнозирования любого значения за пределами этого диапазона (экстраполяция), тогда это может привести к неверным результатам.
Рекомендуемые статьи
Это руководство по линейной регрессии в Excel. Здесь мы обсудим, как сделать линейную регрессию в Excel вместе с практическими примерами и загружаемым шаблоном Excel. Вы также можете просмотреть наши другие предлагаемые статьи -
- Как подготовить платежную ведомость в Excel?
- Использование формулы MAX в Excel
- Учебники по ссылкам на ячейки в Excel
- Создание регрессионного анализа в Excel
- Линейное программирование в Excel