
Разница между Hadoop и Redshift
Hadoop - это платформа с открытым исходным кодом, разработанная Apache Software Foundation, обладающая основными преимуществами масштабируемости, надежности и распределенных вычислений. Обработка данных, хранение, доступ, безопасность - это несколько типов функций, доступных в экосистеме Hadoop. HDFS обладает высокой пропускной способностью, что означает возможность обрабатывать большие объемы данных с возможностью параллельной обработки. Redshift - это веб-служба облачного хостинга, разработанная подразделением Amazon Web Services в Amazon.com Inc., из существующих сервисов, предоставляемых Amazon. Он используется для проектирования крупномасштабного хранилища данных в облаке. Redshift - это сервис хранилища данных в масштабе петабайт, полностью управляемый и экономически эффективный для работы с большими наборами данных.
Давайте подробнее рассмотрим Hadoop и Redshift:
Hadoop HDFS обладает высокой отказоустойчивостью и была разработана для работы на недорогих аппаратных системах. Hadoop может обрабатывать минимальный размер шрифта от TeraBytes до GigaBytes файлов в своей системе. HDFS представляет собой архитектуру «главный-подчиненный», состоящую из узлов имен и узлов данных, где узел имен содержит метаданные, а узел данных содержит реальные данные для обработки или обработки.
RedShift использует различные методы загрузки данных, такие как отчеты BI (Business Intelligence), аналитические инструменты и интеллектуальный анализ данных. Redshift предоставляет консоль для создания и управления кластерами Amazon Redshift. Основным компонентом хранилища данных Redshift является кластер.
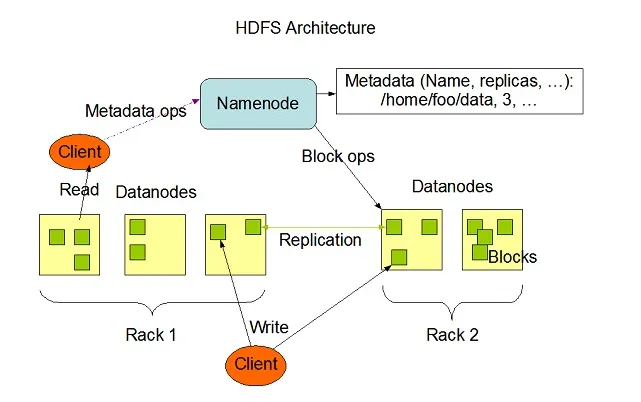
Источник изображения: Apache.org
RedShift Архитектура:
 Источник изображения: Amazon.com
Источник изображения: Amazon.com
Сравнение лицом к лицу Hadoop против Redshift (инфографика):
Ниже приведены 10 лучших сравнений между Hadoop и Redshift:

Ключевые отличия Hadoop от Redshift:
Ниже приведены основные различия между Hadoop и Redshift:
1. Архитектура Hadoop HDFS (распределенная файловая система Hadoop) имеет узлы имен и узлы данных, в то время как Redshift имеет узлы лидера и вычислительные узлы, где вычислительные узлы будут разделены как слайсы.
2. Hadoop предоставляет интерфейс командной строки для взаимодействия с файловой системой, тогда как RedShift имеет консоль управления для взаимодействия с сервисами хранения Amazon, такими как S3, DynamoDB и т. Д.,
3. Операции с базой данных должны быть настроены разработчиками. В Redshift автоматизирует операции с базой данных, анализируя планы выполнения.
4.Hadoop имеет несколько сторонних инструментов поддержки, которые легко интегрируются, тогда как Redshift поддерживает только продукты, разработанные Amazon в своем облаке.
5. С точки зрения архитектуры Hadoop архитектура, сеть, хранилище, безопасность и производительность считаются основными элементами, тогда как в Redshift эти элементы можно легко и гибко настраивать с помощью консоли управления облаком Amazon.
6.Hadoop - это архитектура файловой системы, основанная на интерфейсах прикладного программирования Java (API), тогда как Redshift основана на реляционной модели Database Management System (RDBMS).
7.Hadoop может иметь интеграцию с разными поставщиками, и Redshift не имеет поддержки в этом случае, когда Amazon является их единственным поставщиком. Что делать, если пользователь недоволен услугой? В этом случае Hadoop является преимуществом.
8. Большинство существующих компаний все еще используют Hadoop, тогда как новые клиенты выбирают RedShift.
9. С точки зрения производительности Hadoop всегда отстает, а Redshift всегда выигрывает в случае выполнения запросов на больших объемах данных.
10.Hadoop использует модель программирования Map Reduce для выполнения заданий. Amazon Redshift использует Elastic Map Reduce от Amazon.
11.Hadoop использует модель программирования Map Reduce для запуска заданий. Amazon Redshift использует Elastic Map Reduce от Amazon.
12.Hadoop предпочтительнее запускать пакетные задания ежедневно, что удешевляется, тогда как Redshift выходит дешевле в случае технологии онлайн-аналитической обработки (OLAP), которая существует за многими инструментами бизнес-аналитики.
13.Hadoop работает в 10 раз медленнее, чем Redshift, при выполнении запросов аналогично тому, как Hadoop в 10 раз дороже, чем Redshift, в результате чего Hadoop меньше всего выбирается перед Redshift.
14. Что касается загрузки данных, Hadoop также отстает от Redshift в том, что система потратила часы на загрузку данных из хранилища в свою систему обработки файлов.
15.Hadoop может использоваться для недорогих хранилищ, архивирования данных, озер данных, хранилищ данных и анализа данных, тогда как Redshift входит в возможности хранилищ данных, что ограничивает многоцелевое использование.
16. Платформа Hadoop обеспечивает поддержку различных внешних поставщиков и собственных проектов Apache, таких как Storm, Spark, Kafka, Solr и т. Д., А с другой стороны, Redshift имеет ограниченную поддержку интеграции только со своими продуктами Amazon.
Сравнительная таблица Hadoop и Redshift
| ОСНОВА ДЛЯ
СРАВНЕНИЕ | Hadoop | RedShift |
| Доступность | Open Source Framework от Apache Projects | Платные услуги, предоставляемые Amazon |
| Реализация | Предоставлено поставщиками Hortonworks, Cloudera и т. Д., | Разработано и предоставлено Amazon |
| Производительность | Задания Hadoop MapReduce медленнее | Redshift работает быстрее, чем кластер Hadoop |
| Масштабируемость | Ограничения в масштабируемости | Легко быть уменьшенным / увеличенным согласно требованию |
| ценообразование | Расходы на запуск $ 200 в месяц | Цена зависит от региона сервера и дешевле, чем Hadoop
Например: $ 20 / месяц |
| скорость | Быстрее, но медленнее по сравнению с Redshift | В 10 раз быстрее, чем Hadoop |
| Скорость запроса | Занимает 1491 секунду, чтобы запустить данные 1.2TB | 155 секунд для запуска данных 1.2TB |
| Интеграция данных | Гибкость с локальной файловой системой и любой базой данных | Может загружать данные только из Amazon S3 или DynamoDB |
| Формат данных | Все форматы данных поддерживаются | Строгие форматы данных, такие как форматы файлов CSV |
| Простота использования | Сложно и сложнее справляться с административной деятельностью | Автоматизированное резервное копирование и администрирование хранилища данных |
Вывод - Hadoop против Redshift
И последнее заключение, в котором можно сделать вывод, что лучшим победителем в этом сравнении является Redshift, который выигрывает с точки зрения простоты операций, обслуживания и производительности, в то время как Hadoop не хватает с точки зрения масштабируемости производительности и стоимости услуг с единственным преимуществом простой интеграции с инструментами сторонних производителей. и продукты. Redshift в последнее время развивается с огромным ростом и принятием многими клиентами и клиентами из-за его высокой доступности и меньшей стоимости операций по сравнению с Hadoop делает его все более популярным. Но до сих пор большинство существующих компаний из списка Fortune 1000 использовали платформы Hadoop в своих архитектурах для управления данными клиентов.
В большинстве случаев RedShift был лучшим выбором для любого делового клиента или клиента для обработки больших и конфиденциальных данных любых финансовых учреждений или публичной информации с большей целостностью и безопасностью данных.
Помимо этого, у Hadoop есть свои преимущества: проект с открытым исходным кодом, доступный в течение многих лет, также приводит к замене существующих систем в качестве процесса, несущего затраты. Продукт должен быть окончательно выбран на основе требований и гибкости, а не цены или популярности в зависимости от потребностей бизнеса.
Рекомендуемая статья:
Это было руководство по Hadoop против Redshift, их значению, сравнению «голова к голове», ключевым различиям, сравнительной таблице и выводам. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Hadoop vs Hive - узнай лучшие отличия
- HADOOP vs RDBMS | Знай 12 полезных отличий
- Apache Hadoop против Apache Spark | 10 лучших сравнений, которые вы должны знать!
- Большие данные против Data Science - чем они отличаются?
- Руководство по Hadoop против Spark
- Топ-4 провайдеров облачного хостинга с функциями