
Введение в обучение усилению
Усиленное обучение является типом машинного обучения, и, следовательно, оно также является частью искусственного интеллекта, при применении которого к системам системы выполняют шаги и обучаются на основе результатов шагов, чтобы получить сложную цель, которая установлена для системы.
Понимать Усиление обучения
Давайте попробуем разобраться в обучении с подкреплением с помощью двух простых случаев:
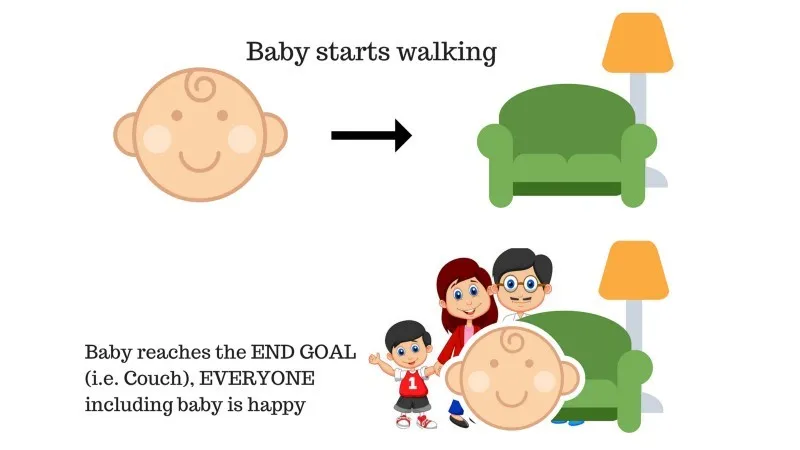
Дело 1
В семье есть ребенок, и она только начала ходить, и все очень этому рады. Однажды родители пытаются поставить цель, дайте ребенку дойти до дивана и посмотреть, сможет ли ребенок это сделать.
Результат случая 1: ребенок успешно достигает дивана, и, таким образом, все в семье очень счастливы видеть это. Выбранный путь теперь идет с положительным вознаграждением.
Очки: Награда + (+ n) → Положительная награда.
Источник: https://images.app.goo.gl/pGCXJ1N1bzLAer126
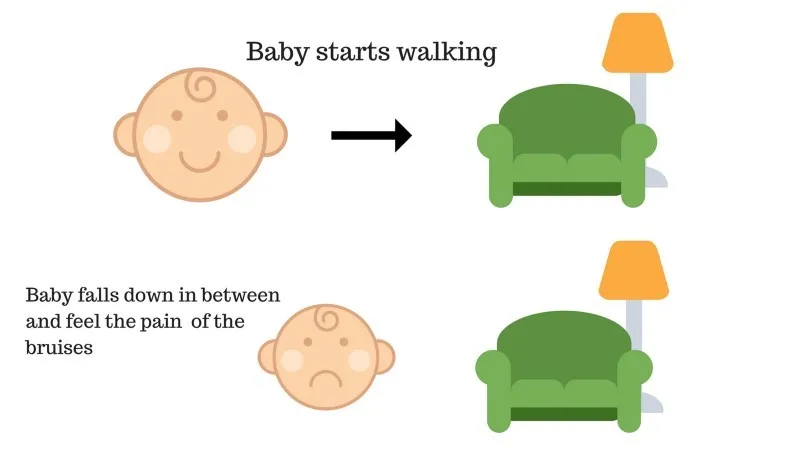
Дело № 2
Ребенок не смог добраться до кушетки, и ребенок упал. Это больно! Что может быть причиной? На пути к дивану могут быть некоторые препятствия, и ребенок упал на препятствия.
Результат случая 2: ребенок падает на некоторые препятствия, и она плачет! О, это было плохо, она поняла, чтобы не попасть в ловушку препятствий в следующий раз. Выбранный путь теперь идет с отрицательной наградой.
Очки: Награды + (-n) → Отрицательное вознаграждение.
Источник: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Это теперь мы видели случаи 1 и 2, обучение с подкреплением, в принципе, делает то же самое, за исключением того, что это не человек, а вместо этого выполняется в вычислительном отношении.
Пошаговое усиление
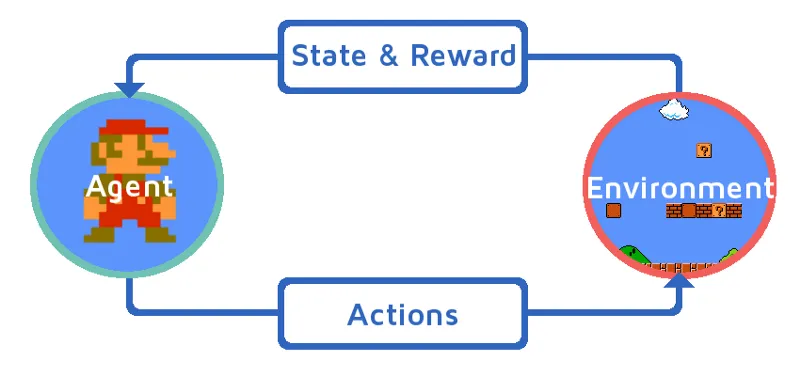
Давайте разберемся в обучении подкреплению, постепенно привлекая агента подкрепления. В этом примере нашим агентом по обучению подкреплению является Марио, который научится играть самостоятельно:
Источник: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Текущее состояние игровой среды Марио - S_0. Потому что игра еще не началась и Марио на своем месте.
- Затем игра запускается, и Марио движется, агент Марио, т.е. RL, предпринимает действия, скажем, A_0.
- Сейчас состояние игровой среды стало S_1.
- Кроме того, агенту RL, то есть Марио, теперь назначен некоторый положительный бонус, R_1, вероятно, потому, что Марио все еще жив и не было никакой опасности.
Теперь вышеприведенный цикл будет продолжаться до тех пор, пока Марио, наконец, не умрет или Марио не достигнет своего пункта назначения. Эта модель будет постоянно выводить действие, награду и состояние.
Максимизация Награды
Цель обучающего обучения - максимизировать вознаграждение, принимая во внимание некоторые другие факторы, такие как скидка за вознаграждение; мы вскоре объясним, что подразумевается под скидкой, с помощью иллюстрации.
Накопительная формула для дисконтированных вознаграждений:
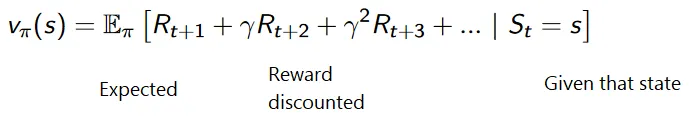
Скидки
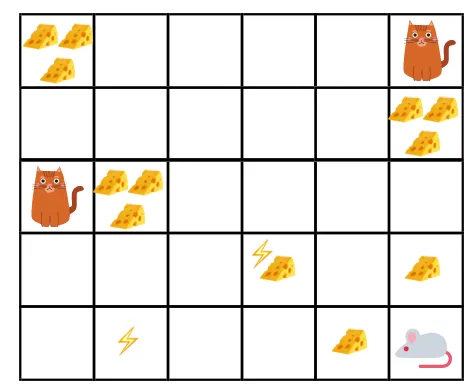
Позвольте нам понять это на примере:
- На данном рисунке цель в том, чтобы мышь в игре съела столько же сыра, сколько съела кошка или не подверглась электрошоку.
- Теперь мы можем предположить, что чем ближе мы к кошке или электрической ловушке, тем больше вероятность того, что мышь съест или шокирует.
- Это означает, что даже если у нас есть полный сыр рядом с блоком удара током или рядом с кошкой, чем опаснее идти туда, тем лучше есть находящийся поблизости сыр, чтобы избежать какого-либо риска.
- Поэтому, несмотря на то, что у нас есть один «блок1» сыра, который полон и находится далеко от кота и блока электрошока, а другой - «блок2», который также полон, но находится рядом с котом или блоком электрошока более поздний сырный блок, то есть «block2», будет более дисконтирован в наградах, чем предыдущий.
Источник: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Источник: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Типы Усиления обучения
Ниже приведены два вида обучения с подкреплением с их преимуществами и недостатками:
1. Положительный
Когда сила и частота поведения увеличиваются из-за возникновения определенного поведения, оно называется «Обучение позитивному подкреплению».
Преимущества: производительность максимальна, а изменения сохраняются в течение более длительного времени.
Недостатки: результаты могут быть уменьшены, если у нас слишком много подкрепления.
2. Отрицательный
Это усиление поведения, в основном из-за того, что отрицательный термин исчезает.
Преимущества: Поведение увеличивается.
Недостатки: только минимальное поведение модели может быть достигнуто с помощью обучения с отрицательным подкреплением.
Где следует использовать обучение по усилению?
Вещи, которые могут быть сделаны с Укреплением Изучения / Примерами. Следующее - области, где обучение Подкреплению используется в эти дни:
- Здравоохранение
- образование
- Игры
- Компьютерное зрение
- Управление бизнесом
- робототехника
- финансов
- НЛП (обработка естественного языка)
- Транспорт
- энергии
Карьера в обучении укреплению
Действительно, есть отчет с места работы, поскольку RL - это ветвь машинного обучения. Согласно отчету, машинное обучение - лучшая работа 2019 года. Ниже приведен снимок отчета. В соответствии с текущими тенденциями инженеры машинного обучения получают колоссальную среднюю зарплату в 146 085 долл. США и темпы роста в 344 процента.
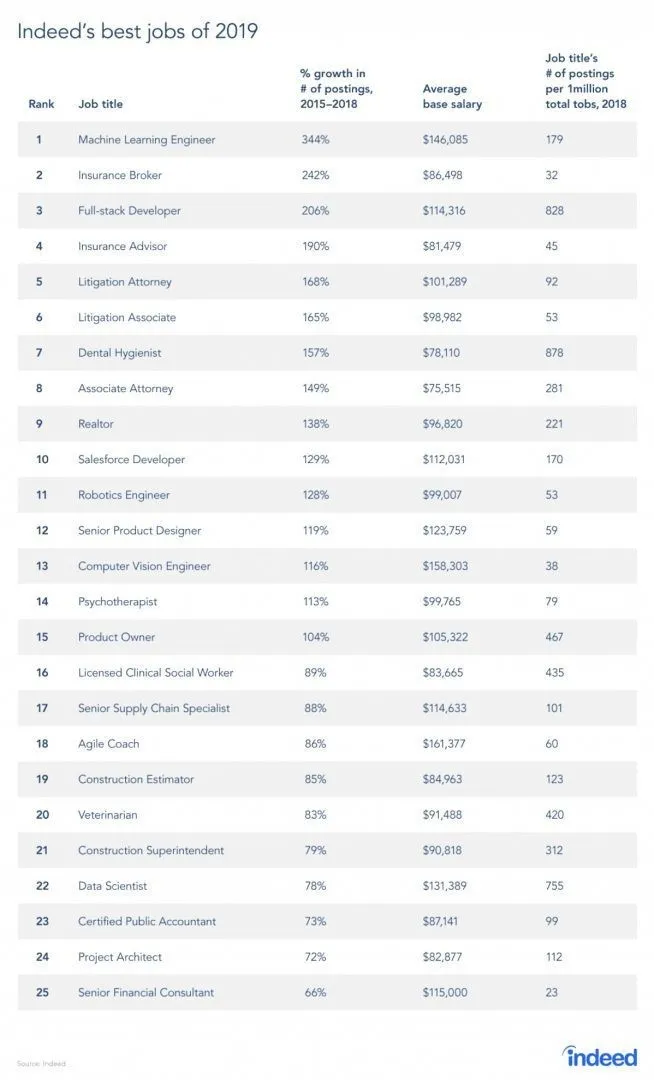
Источник: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1.
Навыки для Укрепления Изучения
Ниже приведены навыки, необходимые для обучения подкреплению:
1. Основные навыки
- Вероятность
- Статистика
- Моделирование данных
2. Навыки программирования
- Основы программирования и информатики
- Разработка программного обеспечения
- Умеет применять библиотеки и алгоритмы машинного обучения.
3. Языки программирования машинного обучения
- питон
- р
- Хотя есть и другие языки, где могут быть разработаны модели машинного обучения, такие как Java, C / C ++, но Python и R являются наиболее популярными используемыми языками.
Вывод
В этой статье мы начали с краткого введения об обучении с подкреплением, а затем глубоко погрузились в работу с RL и различные факторы, которые влияют на работу моделей RL. Затем мы привели несколько реальных примеров, чтобы еще лучше понять эту тему. К концу этой статьи, у вас должно быть хорошее понимание работы обучения подкреплению.
Рекомендуемые статьи
Это руководство к тому, что такое обучение усилению? Здесь мы обсудим функции и различные факторы, участвующие в разработке моделей обучения подкреплению, с примерами. Вы также можете просмотреть другие наши статьи, чтобы узнать больше -
- Типы алгоритмов машинного обучения
- Введение в искусственный интеллект
- Инструменты искусственного интеллекта
- IoT Платформа
- Топ 6 языков программирования машинного обучения