

Введение в команды Hive
Команда Hive - это инструмент инфраструктуры хранилища данных, который находится на вершине Hadoop для суммирования больших данных. Обрабатывает структурированные данные. Это облегчает запрос и анализ данных. Команда Hive также называется «схемой на чтение». Hive не проверяет данные при загрузке, проверка происходит только при выдаче запроса. Это свойство Hive делает его быстрым для начальной загрузки. Это как копирование или просто перемещение файла без каких-либо ограничений или проверок. Улей был впервые разработан Facebook. Apache Software Foundation взялся за это позже и развивал его.
Вот компоненты команды Hive:
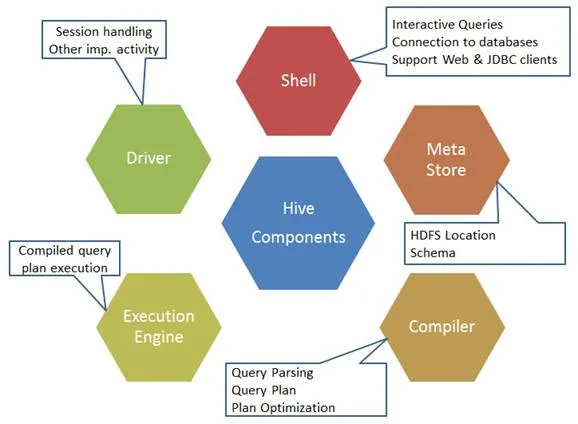
Рис 1. Компоненты улья
https://www.developer.com/
Вот особенности команды Hive, перечисленные ниже:
- Магазины Hive представляют собой набор необработанных и обработанных данных в Hadoop.
- Он предназначен для обработки транзакций OnLine (OLTP). OLTP - это системы, которые обеспечивают большие объемы данных за очень короткое время, не полагаясь на один сервер.
- Это быстро, масштабируемо и надежно.
- Язык запросов типов SQL, представленный здесь, называется HiveQL или HQL. Это облегчает задачи ETL и другой анализ.
Рис 2. Свойства улья
Источники изображений: - Google
Есть также несколько ограничений команды Hive, которые перечислены ниже:
- Hive не поддерживает подзапросы.
- Hive, безусловно, поддерживает перезапись, но, к сожалению, не поддерживает удаление и обновления.
- Улей не предназначен для OLTP, но он используется для него.
Чтобы войти в интерактивную оболочку Hive:
$ HIVE_HOME / бен / улей
Основные команды улья
-
Создайте
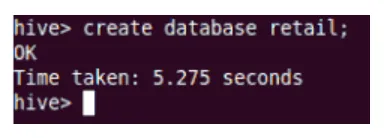
Это создаст новую базу данных в Hive.
-
Капля
Капля удалит стол из Улья
-
Alter
Команда Alter поможет вам переименовать таблицу или столбцы таблицы.
Например:
hive> ALTER TABLE сотрудника RENAME TO employee1;
-
Показать
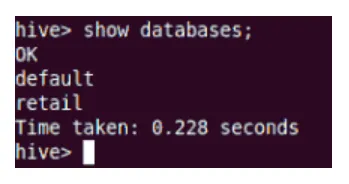
Команда show покажет все базы данных, находящиеся в Hive.
-
описывать
Команда Describe поможет вам с информацией о схеме таблицы.
Промежуточные Команды Улья
Hive делит таблицу на различные связанные разделы на основе столбцов. Используя эти разделы, становится проще запрашивать данные. Эти разделы далее делятся на сегменты для эффективного выполнения запросов к данным.
Другими словами, сегменты распределяют данные в набор кластеров, вычисляя хеш-код ключа, упомянутого в запросе.
-
Добавление раздела
Добавление раздела может быть выполнено путем изменения таблицы. Допустим, у вас есть таблица «EMP» с такими полями, как Id, Имя, Зарплата, Отдел, Назначение и yoj.
улей> ALTER TABLE сотрудник
> ДОБАВИТЬ РАЗДЕЛ (год = '2012')
местоположение '/ 2012 / part2012';
-
Переименование раздела
улей> ALTER TABLE сотрудника PARTITION (год = '1203')
ИЗМЕНИТЬ В РАЗДЕЛ (Yoj = '1203');
-
Отбросить раздел
hive> ALTER TABLE сотрудник DROP (ЕСЛИ СУЩЕСТВУЕТ)
> PARTITION (год = '1203');
-
Реляционные операторы
Реляционные операторы состоят из определенного набора операторов, который помогает в извлечении соответствующей информации.
Например: скажем, ваша таблица «EMP» выглядит следующим образом:
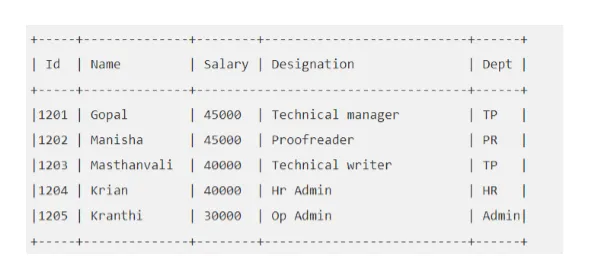
Давайте выполним запрос Hive, который принесет нам сотрудника, чья зарплата больше 30000.
улей> ВЫБРАТЬ * ИЗ ЭМИРА, ГДЕ Зарплата> = 40000;
-
Арифметические Операторы
Это операторы, которые помогают в выполнении арифметических операций над операндами и, в свою очередь, всегда возвращают числовые типы.
Например: добавить два числа, такие как 22 и 33
hive> SELECT 22 + 33 ADD FROM temp;
-
Логический оператор
Эти операторы должны выполнять логические операции, которые в свою очередь всегда возвращают True / False.
улей> ВЫБРАТЬ * ИЗ ПУТЬ ГДЕ Зарплата> 40000 && Dept = TP;
Расширенные команды Hive
-
Посмотреть
Концепция представления в Hive похожа на SQL. Представление может быть создано во время выполнения инструкции SELECT.
Пример:
куст> CREATE VIEW EMP_30000 AS
ВЫБРАТЬ * ИЗ EMP
ГДЕ зарплата> 30000;
-
Загрузка данных в таблицу
Hive> Загружать локальный путь к данным /home/hduser/Desktop/AllStates.csv в таблицу состояний;
Здесь «States» - это уже созданная таблица в Hive.
https://www.tutorialspoint.com/hive/
В Hive есть несколько встроенных функций, которые помогут вам получить лучший результат.
Как круглый, напольный, BIGINT и т. Д.
-
Присоединиться
Предложение объединения может помочь в объединении двух таблиц на основе одного и того же имени столбца.
Пример:
улей> ВЫБЕРИТЕ c.ID, c.NAME, c.AGE, o.AMOUNT
ОТ КЛИЕНТОВ c СОВМЕСТНЫЕ ЗАКАЗЫ o
ON (c.ID = o.CUSTOMER_ID);
Hive поддерживает все виды соединений: левое внешнее соединение, правое внешнее соединение, полное внешнее соединение.
Советы и рекомендации по использованию команд улья
Hive делает обработку данных настолько простой, понятной и расширяемой, что пользователь уделяет меньше внимания оптимизации запросов Hive. Но уделение внимания нескольким вещам при написании запросов Hive, несомненно, принесет большой успех в управлении рабочей нагрузкой и экономии денег. Ниже приведены несколько советов относительно этого:
- Разделы и корзины: Hive - это инструмент для работы с большими данными, который может запрашивать большие наборы данных. Однако написание запроса без понимания предметной области может привести к большим разделам в Hive.
Если пользователь знает о наборе данных, соответствующие и часто используемые столбцы могут быть сгруппированы в один и тот же раздел. Это поможет выполнить запрос быстрее и неэффективно.
В конечном итоге нет. операций преобразования и ввода-вывода также будут сокращены.
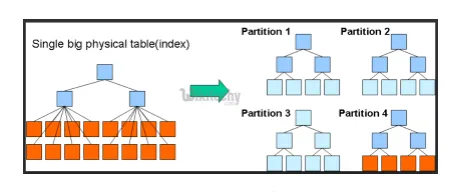
Рис 3. Разделение
Источники изображений: изображение Google
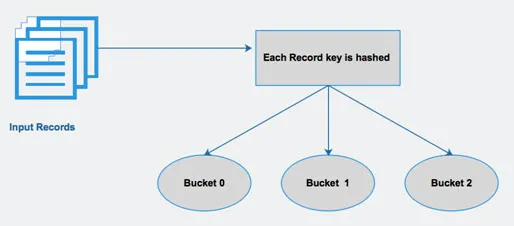
Рис 4
Источники изображений: - изображение Google
- Параллельное выполнение: Hive выполняет запрос в несколько этапов. В некоторых случаях эти этапы могут зависеть от других этапов и, следовательно, не могут быть начаты после завершения предыдущего этапа. Однако независимые задачи могут выполняться параллельно для экономии общего времени выполнения. Чтобы включить параллельный запуск в Hive:
set hive.exec.parallel = true;
Следовательно, это улучшит использование кластера.
- Выборка блоков: выборка данных из таблицы позволит исследовать запросы данных.
Несмотря на раскряжевку, мы скорее хотим выбирать набор данных более случайным образом. Блочная выборка имеет различный мощный синтаксис, который помогает в выборке данных различными способами.
Отбор проб можно использовать для нахождения ок. информация из набора данных, как среднее расстояние между пунктом отправления и пунктом назначения.
Запрос 1% больших данных даст почти идеальный ответ. Исследование становится намного проще и эффективнее.
Вывод - Улей команды
Hive - это абстракция более высокого уровня поверх HDFS, которая обеспечивает гибкий язык запросов. Это помогает в запросе и обработке данных более простым способом.
Hive можно объединить с другими элементами Big data, чтобы в полной мере использовать его функциональность.
Рекомендуемые статьи
Это было руководство к командам Hive. Здесь мы обсудили как базовые, так и расширенные команды Hive и некоторые непосредственные команды Hive. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Hive Интервью Вопросы
- Hive VS Hue - Топ 6 полезных сравнений
- Табличные команды
- Adobe Photoshop Commands
- Использование функции ORDER BY в Hive
- Скачайте и установите Hive Step by Step