
Введение в архитектуру улья
Архитектура Hive построена на основе экосистемы Hadoop. Улей часто взаимодействует с Hadoop. Apache Hive отлично справляется как с системой баз данных SQL домена, так и с Map-Reduce. Приложения Hive могут быть написаны на разных языках, таких как Java, Python. Архитектура Hive показывает, как писать язык запросов Hive и как взаимодействие между программистом осуществляется с помощью интерфейса командной строки. Язык запросов Hive выполняет работу по преобразованию всех задач кластера Hadoop с помощью map-Reduce. Как все мы знали, Hadoop обрабатывает большие данные в распределенной среде и создает среду с открытым исходным кодом. Благодаря hive он гибко управляет и выполняет запрос, а также является хорошим помощником для выполнения таких функций, как инкапсуляция, специальные запросы. В этой статье дается краткое введение в архитектуру кустов, которая находится на уровне Hadoop для суммирования больших данных.
Архитектура улья с его компонентами
Hive играет важную роль в анализе данных и интеграции бизнес-аналитики, а также поддерживает такие форматы файлов, как текстовый файл и файл RC. Hive использует распределенную систему для обработки и выполнения запросов, и хранение в конечном итоге осуществляется на диске и, наконец, обрабатывается с использованием структуры сокращения карт. Это решает проблему оптимизации, найденную в картографическом сокращении, и куст выполняет выполнение пакетных заданий, которые четко объяснены в рабочем процессе. Здесь мета-магазин хранит информацию о схеме. Платформа под названием Apache Tez предназначена для выполнения запросов в реальном времени.
Основные компоненты Улья приведены ниже:
- Клиенты улья
- Улей Услуги
- Хранение улья (Мета хранилище)
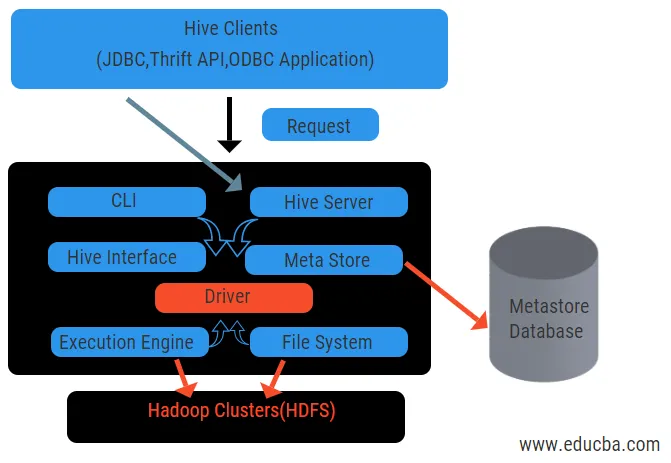
Приведенная выше диаграмма показывает архитектуру Hive и его составных элементов.
Клиенты Hive:
Они включают в себя приложение Thrift для выполнения простых команд куста, которые доступны для python, ruby, C ++ и драйверов. Эти клиентские приложения имеют преимущества для выполнения запросов в улье. Hive имеет три типа классификации клиентов: экономичные клиенты, клиенты JDBC и ODBC.
Услуги улья:
Для обработки всех запросов в улье есть различные сервисы. Все функции легко определяются пользователем в улье. Давайте кратко рассмотрим все эти услуги:
- Интерфейс командной строки (пользовательский интерфейс): он обеспечивает взаимодействие между пользователем и кустом, оболочкой по умолчанию. Он предоставляет графический интерфейс для выполнения командной строки hive и понимания hive. Мы также можем использовать веб-интерфейсы (HWI) для отправки запросов и взаимодействия с веб-браузером.
- Драйвер куста: он получает запросы от различных источников и клиентов, таких как сервер Thrift, и сохраняет и выбирает драйверы ODBC и JDBC, которые автоматически подключаются к кусту. Этот компонент выполняет семантический анализ при просмотре таблиц из метастаза, который анализирует запрос. Драйвер пользуется помощью компилятора и выполняет такие функции, как анализатор, планировщик, выполнение заданий MapReduce и оптимизатор.
- Компилятор: синтаксический и семантический процесс запроса выполняется компилятором. Он преобразует запрос в абстрактное синтаксическое дерево и снова обратно в DAG для совместимости. Оптимизатор, в свою очередь, разделяет доступные задачи. Задача исполнителя - запускать задачи и следить за расписанием конвейера задач.
- Механизм выполнения: все запросы обрабатываются механизмом выполнения. Планы этапов DAG выполняются механизмом и помогают управлять зависимостями между доступными этапами и выполнять их на правильном компоненте.
- Metastore: он выступает в качестве центрального хранилища для хранения всей структурированной информации метаданных, а также является важной аспектной частью улья, поскольку содержит информацию, такую как таблицы и сведения о разделах, а также хранилище файлов HDFS. Другими словами, мы будем говорить, что metastore действует как пространство имен для таблиц. Metastore считается отдельной базой данных, которая также используется другими компонентами. Metastore состоит из двух частей: службы и хранилища невыполненных работ
Модель данных улья структурирована на разделы, сегменты, таблицы. Все это можно отфильтровать, иметь ключи разделов и оценить запрос. Запрос Hive работает на платформе Hadoop, а не на традиционной базе данных. Сервер Hive - это интерфейс между запросами удаленного клиента к улью. Механизм исполнения полностью встроен в сервер улья. Вы можете найти применение улья в машинном обучении, бизнес-аналитике в процессе обнаружения.
Рабочий поток улья:
Улей работает в двух типах режимов: интерактивный режим и неинтерактивный режим. Предыдущий режим позволяет всем командам куста переходить непосредственно в оболочку куста, в то время как последний тип выполняет код в режиме консоли. Данные делятся на разделы, которые далее делятся на сегменты. Планы выполнения основаны на агрегации и перекосе данных. Дополнительным преимуществом использования улья является то, что он легко обрабатывает большие объемы информации и имеет больше пользовательских интерфейсов.
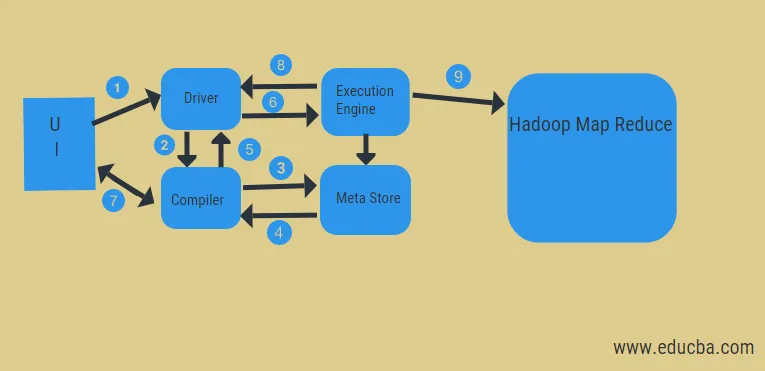
Из приведенной выше диаграммы мы можем получить представление о потоке данных в улье с помощью системы Hadoop.
Шаги включают в себя:
- выполнить запрос из пользовательского интерфейса
- получить план от водителя задач DAG этапов
- получить запрос метаданных из мета-хранилища
- отправить метаданные от компилятора
- отправка плана обратно водителю
- Выполнить план в движке исполнения
- выборка результатов для соответствующего пользовательского запроса
- отправка результатов в двух направлениях
- обработка обработчиком в HDFS с отображением и извлечением результатов из узлов данных, созданных средством отслеживания заданий. он действует как связующее звено между Hive и Hadoop.
Работа механизма выполнения состоит в том, чтобы связываться с узлами для получения информации, хранящейся в таблице. Здесь SQL-операции, такие как create, drop, alter, выполняются для доступа к таблице.
Вывод:
Мы рассмотрели архитектуру Hive и их рабочий процесс. Hive в основном обрабатывает петабайтный объем данных и, следовательно, представляет собой пакет хранилища данных на платформе Hadoop. Поскольку куст - хороший выбор для обработки большого объема данных, он помогает в подготовке данных с руководством по интерфейсу SQL для решения проблем MapReduce. Apache Hive - это инструмент ETL для обработки структурированных данных. Знание работы архитектуры улья помогает корпоративным людям понять принцип работы улья и хорошо начинается с программирования улья.
Рекомендуемые статьи:
Это было руководство по архитектуре улья. Здесь мы обсуждаем архитектуру улья, различные компоненты и рабочий процесс улья. Вы также можете посмотреть следующие статьи, чтобы узнать больше
- Hadoop Architecture
- Использование Рубина
- Что такое C ++
- Что такое база данных MySQL
- Улей Заказать