

Введение в методы интеллектуального анализа данных
Данные ежедневно увеличиваются в огромных масштабах. Но все собранные или собранные данные бесполезны. Значимые данные должны быть отделены от зашумленных данных (бессмысленные данные). Этот процесс разделения осуществляется с помощью интеллектуального анализа данных.
Что такое Data Mining?
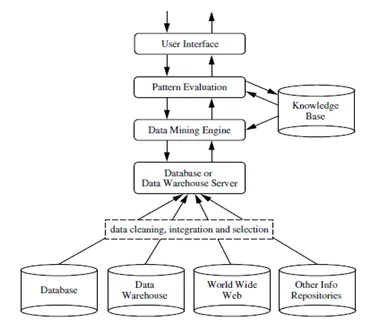
Интеллектуальный анализ данных - это процесс извлечения полезной информации или знаний из огромного количества данных (или больших данных). Разрыв между данными и информацией был уменьшен благодаря использованию различных инструментов интеллектуального анализа данных. Интеллектуальный анализ данных также может называться обнаружением знаний из данных или KDD .
Источники: - www.ques10.com
Интеллектуальный анализ данных может выполняться в различных типах баз данных и информационных хранилищах, таких как реляционные базы данных, хранилища данных, транзакционные базы данных, потоки данных и многое другое.
Различные методы сбора данных:
Существует много методов, используемых для интеллектуального анализа данных, но критически важным шагом является выбор подходящего метода из них в соответствии с бизнесом или формулировкой проблемы. Эти методы анализа данных помогают предсказывать будущее и затем принимать соответствующие решения. Они также помогают анализировать рыночные тенденции и увеличивать доходы компании.
Некоторые методы сбора данных:
- ассоциация
- классификация
- Кластерный анализ
- прогнозирование
- Последовательные паттерны или отслеживание паттернов
- Деревья решений
- Анализ выбросов или анализ аномалий
- Нейронная сеть
Давайте разберемся во всех методах интеллектуального анализа данных один за другим.
1. Ассоциация:
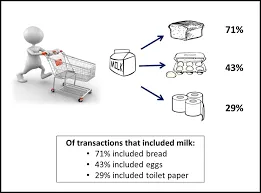
Это метод, используемый для нахождения корреляции между двумя или более элементами путем определения скрытого шаблона в наборе данных и, следовательно, также называемый анализом отношений . Этот метод используется в анализе рыночной корзины для прогнозирования поведения клиента.
Предположим, менеджер по маркетингу супермаркета хочет определить, какие продукты часто покупаются вместе.
В качестве примера,
Покупки (х, «пиво») -> покупки (х, «фишки») (поддержка = 1%, доверие = 50%)
- Здесь х представляет клиента, покупающего пиво и чипсы вместе.
- Уверенность показывает уверенность в том, что если покупатель покупает пиво, то вероятность того, что он / она купит чипсы, составляет 50%.
- Поддержка означает, что 1% всех анализируемых транзакций показал, что пиво и чипсы были куплены вместе.
Можно рассмотреть много подобных примеров, таких как хлеб с маслом, компьютер и программное обеспечение.
Существует два типа правил ассоциации:
- Правило одномерной ассоциации: эти правила содержат один атрибут, который повторяется.
- Правило многомерной ассоциации: эти правила содержат несколько повторяющихся атрибутов.
https://bit.ly/2N61gzR
2. Классификация:
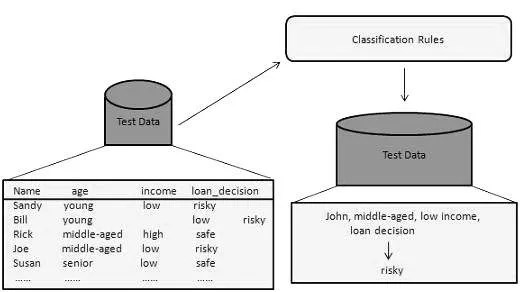
Этот метод анализа данных используется для разделения элементов в наборах данных на классы или группы. Это помогает точно предсказать поведение предметов в группе. Это двухэтапный процесс:
- Этап обучения (этап обучения). В этом случае алгоритм классификации строит классификатор путем анализа обучающего набора.
- Шаг классификации: данные испытаний используются для оценки точности или точности правил классификации.
Например, банковская компания использует для выявления претендентов на получение кредита низкий, средний или высокий кредитный риск. Точно так же медицинский исследователь анализирует данные рака, чтобы предсказать, какое лекарство назначить пациенту.
Источники: - www.tutorialspoint.com
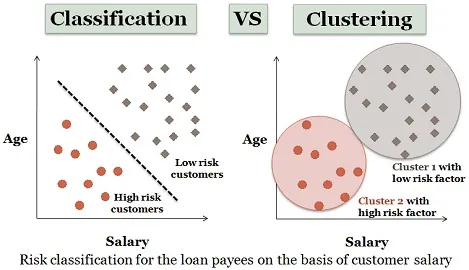
3. Кластерный анализ:
Кластеризация почти аналогична классификации, но в этой кластеры делаются в зависимости от сходства элементов данных. Различные кластеры имеют разные или не связанные объекты. Это также называется сегментацией данных, поскольку разделяет огромные наборы данных на кластеры в соответствии с общими чертами.
Существуют различные методы кластеризации:
- Иерархические агломерационные методы
- Методы на основе сетки
- Методы разбиения
- Основанные на модели методы
- Методы, основанные на плотности
Подобный пример соискателей может быть рассмотрен и здесь. Есть некоторые отличия, которые изображены на рисунке ниже.
https://bit.ly/2N6aZpP
4. Прогноз:
Этот метод используется для прогнозирования будущего на основе прошлых и настоящих тенденций или набора данных. Прогнозирование в основном используется в сочетании с другими методами анализа данных, такими как классификация, сопоставление с образцом, анализ тенденций и взаимосвязь.
Например, если менеджер по продажам супермаркета хотел бы предсказать сумму дохода, которую получит каждый товар, на основе прошлых данных о продажах. Он моделирует непрерывную функцию, которая предсказывает пропущенные числовые значения данных.

Источники: - data-mining.philippe-fournier
Регрессионный анализ - лучший выбор для прогнозирования. Его можно использовать для установки взаимосвязи между независимыми переменными и зависимыми переменными.
5. Последовательные шаблоны или отслеживание шаблонов:
Этот метод анализа данных используется для выявления закономерностей, которые часто встречаются в течение определенного периода времени.
Например, менеджер по продажам швейной компании видит, что продажи курток, кажется, увеличиваются как раз перед зимним сезоном, или продажи в пекарне увеличиваются в канун Рождества или Нового года.
Давайте посмотрим на пример с графиком
Источники: - data-mining.philippe-fournier-viger
6. Деревья решений:
Дерево решений - это древовидная структура (как следует из ее названия), где
- Каждый внутренний узел представляет тест на атрибут.
- Ветвь обозначает результат теста.
- Конечные узлы содержат метку класса.
- Самый верхний узел - это корневой узел, у которого есть простой вопрос с двумя или более ответами. Соответственно, дерево растет, и создается структура, подобная блок-схеме.
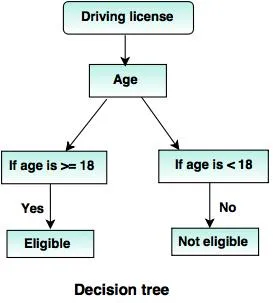
Источники: - www.tutorialride.com
В этом решении древовидное правительство классифицирует граждан в возрасте до 18 лет или старше 18 лет. Это поможет им решить, должна ли лицензия быть выдана конкретному гражданину или нет.
7. Внешний анализ или анализ аномалий:
Этот метод анализа данных используется для определения элементов данных, которые не соответствуют ожидаемому шаблону или ожидаемому поведению. Эти неожиданные элементы данных рассматриваются как выбросы или шум. Они полезны во многих областях, таких как обнаружение мошенничества с кредитными картами, обнаружение вторжений, обнаружение неисправностей и т. Д. Это также называется Outlier Mining .
Например, предположим, что приведенный ниже график построен с использованием некоторых наборов данных в нашей базе данных.
Таким образом, лучше всего подходит линия. Точки, лежащие рядом с линией, показывают ожидаемое поведение, в то время как точка, удаленная от линии, является выбросом.
Это поможет обнаружить аномалии и принять соответствующие меры.
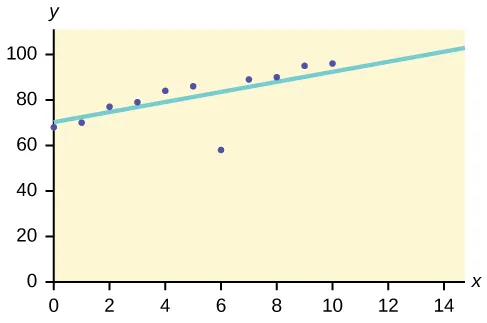
https://bit.ly/2GrgjDP
8. Нейронная сеть:
Этот метод или модель интеллектуального анализа данных основана на биологических нейронных сетях. Это набор нейронов, таких как процессоры, с взвешенными связями между ними. Они используются для моделирования отношений между входами и выходами. Он используется для классификации, регрессионного анализа, обработки данных и т. Д. Этот метод работает на трех основных
- модель
- Алгоритм обучения (под надзором или без присмотра)
- Функция активации
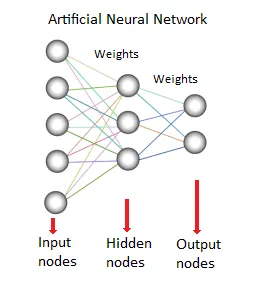
Источники: - www.saedsayad.com
Рекомендуемые статьи
Это было руководство по методам интеллектуального анализа данных. Здесь мы обсудили, что такое интеллектуальный анализ данных и различные типы метода интеллектуального анализа данных с примером. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Big Data Analytics Software
- Вопросы интервью по структуре данных
- Важные методы добычи данных
- Архитектура интеллектуального анализа данных