
Введение в техники ансамбля
Ансамблевое обучение - это техника машинного обучения, которая использует несколько базовых моделей и объединяет их результаты для создания оптимизированной модели. Этот тип алгоритма машинного обучения помогает улучшить общую производительность модели. Здесь базовой моделью, которая наиболее часто используется, является классификатор дерева решений. Дерево решений в основном работает по нескольким правилам и обеспечивает прогнозирующий вывод, где правила являются узлами, а их решения будут их дочерними элементами, а конечные узлы будут представлять собой окончательное решение. Как показано на примере дерева решений.
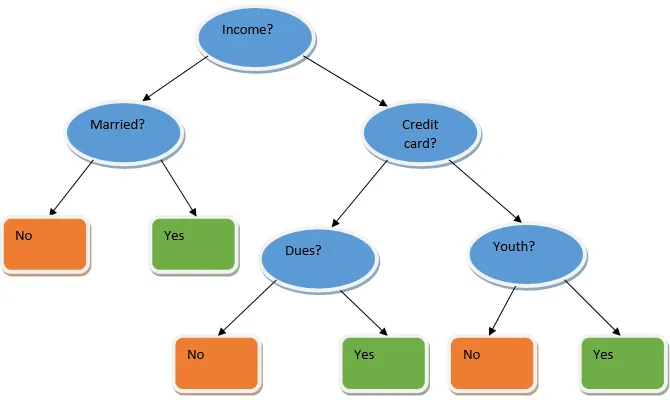
Приведенное выше дерево решений в основном говорит о том, может ли человек / клиент получить кредит или нет. Одно из правил приемлемости ссуды да заключается в том, что если (доход = Да && Женат = Нет), то Ссуда = Да, так работает классификатор дерева решений. Мы будем объединять эти классификаторы как модель с множеством баз и объединяем их результаты для создания одной оптимальной прогностической модели. Рисунок 1.b показывает общую картину алгоритма обучения ансамбля.
Типы Ансамблей Техники
Различные типы ансамблей, но наше основное внимание будет уделено следующим двум типам:
- мешковина
- стимулирование
Эти методы помогают уменьшить дисперсию и смещение в модели машинного обучения. Теперь давайте попробуем понять, что такое предвзятость и дисперсия. Смещение - это ошибка, которая возникает из-за неверных допущений в нашем алгоритме; высокий уклон указывает на то, что наша модель слишком проста / не подходит. Дисперсия - это ошибка, вызванная чувствительностью модели к очень небольшим колебаниям в наборе данных; высокая дисперсия указывает на то, что наша модель очень сложна / не подходит. Идеальная модель ML должна иметь правильный баланс между смещением и дисперсией.
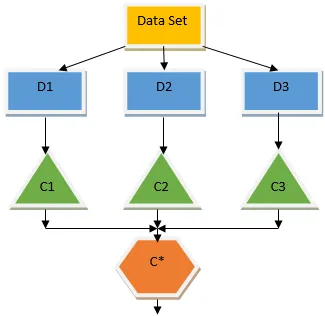
Bootstrap Агрегирование / Упаковка
Пакетирование - это метод ансамбля, который помогает уменьшить дисперсию в нашей модели и, следовательно, позволяет избежать переоснащения. Пакетирование является примером алгоритма параллельного обучения. Работа с мешками основана на двух принципах.
- Начальная загрузка: Исходный набор данных рассматривает различные популяции выборки с заменой.
- Агрегирование: усреднение результатов всех классификаторов и предоставление единого результата, для этого используется большинство голосов в случае классификации и усреднение в случае проблемы регрессии. Один из известных алгоритмов машинного обучения, использующий концепцию пакетирования, - это случайный лес.
Случайный Лес
В случайном лесу из случайной выборки, отобранной из популяции с заменой, и подмножество признаков выбирается из набора всех признаков, которые строится в дереве решений. Из этих подмножеств объектов в зависимости от того, какая функция дает наилучшее разделение, выбирается корень дерева решений. Подмножество функций должно выбираться случайным образом любой ценой, в противном случае мы получим только коррелированное напряжение, и дисперсия модели не будет улучшена.
Теперь мы построили нашу модель с выборками, взятыми у населения, вопрос в том, как мы проверяем модель? Так как мы рассматриваем образцы с заменой, следовательно, все образцы не будут рассматриваться, и некоторые из них не будут включены в какую-либо сумку, они называются пробными образцами. Мы можем проверить нашу модель с помощью этих образцов OOB (из пакета). Важными параметрами, которые необходимо учитывать в случайном лесу, является количество выборок и количество деревьев. Давайте рассмотрим «m» как подмножество функций, а «p» - полный набор функций, теперь, как правило, всегда лучше выбирать
- m as√ и минимальный размер узла 1 для задачи классификации.
- m как P / 3 и минимальный размер узла 5 для проблемы регрессии.
М и р должны рассматриваться как параметры настройки, когда мы имеем дело с практической проблемой. Обучение может быть прекращено после стабилизации ошибки OOB. Одним из недостатков случайного леса является то, что, когда в нашем наборе данных имеется 100 объектов и важна только пара функций, этот алгоритм будет работать плохо.
стимулирование
Повышение - это алгоритм последовательного обучения, который помогает уменьшить смещение в нашей модели и дисперсию в некоторых случаях контролируемого обучения. Это также помогает превратить слабых учеников в сильных учеников. Повышение работает по принципу последовательного размещения слабых учеников и присваивает вес каждой точке данных после каждого раунда; больший вес приписан ошибочно классифицированной точке данных в предыдущем раунде. Этот последовательный взвешенный метод обучения нашего набора данных является ключевым отличием от метода пакетирования.
На рисунке 3.a показан общий подход к повышению
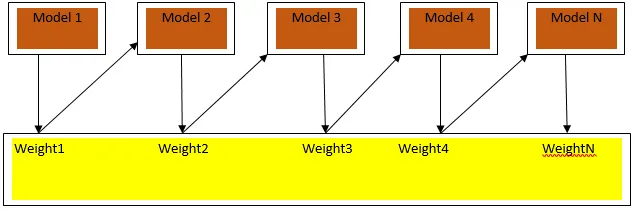
Окончательные прогнозы объединяются на основе взвешенного большинства голосов в случае классификации и взвешенной суммы в случае регрессии. Наиболее широко используемый алгоритм повышения - это адаптивное повышение (Adaboost).
Адаптивное Повышение
Шаги, включенные в алгоритм Adaboost, следующие:
- Для заданных n точек данных мы определяем целевой класс и инициализируем все веса 1 / n.
- Мы подгоняем классификаторы к набору данных и выбираем классификацию с наименьшей взвешенной ошибкой классификации
- Мы назначаем веса для классификатора по правилу большого пальца, основываясь на точности, если точность больше 50%, то вес положительный и наоборот.
- Мы обновляем вес классификаторов в конце итерации; мы обновляем больший вес для ошибочно классифицированной точки, чтобы на следующей итерации мы правильно ее классифицировали.
- После всех итераций мы получаем окончательный результат прогноза, основанный на мажоритарном / средневзвешенном голосовании
Adaboosting эффективно работает со слабыми (менее сложными) учениками и с классификаторами с большим смещением. Основными преимуществами Adaboosting является то, что он быстрый, здесь нет параметров настройки, аналогичных случаю пакетирования, и мы не делаем никаких предположений для слабых учеников. Этот метод не дает точного результата, когда
- В наших данных больше выбросов.
- Набор данных недостаточен.
- Слабые ученики очень сложны.
Они также чувствительны к шуму. Деревья решений, которые создаются в результате повышения, будут иметь ограниченную глубину и высокую точность.
Вывод
Методы обучения ансамбля широко используются для повышения точности модели; мы должны решить, какую технику использовать, основываясь на нашем наборе данных. Но эти методы не являются предпочтительными в некоторых случаях, когда интерпретируемость имеет важное значение, так как мы теряем интерпретируемость за счет повышения производительности. Они имеют огромное значение в отрасли здравоохранения, где небольшое улучшение производительности очень ценно.
Рекомендуемые статьи
Это руководство по технике ансамбля. Здесь мы обсуждаем введение и два основных типа ансамблевой техники. Вы также можете просмотреть другие наши статьи, чтобы узнать больше-
- Методы стеганографии
- Методы машинного обучения
- Техника построения команды
- Алгоритмы Науки Данных
- Наиболее используемые техники ансамблевого обучения