

Разница между Apache Hive и Apache HBase -
История Apache Hive начинается в 2007 году, когда не Java-программисту приходится бороться за использование Hadoop MapReduce. Исследователи и разработчики предсказали, что завтра наступит эра больших данных. Уже накапливались различные форматы данных, такие как структурированные, полуструктурированные и неструктурированные. Даже Facebook боролся с большим объемом обработки данных. Исследователи из Facebook представили Apache Hive для обработки данных в кластере Hadoop. Facebook был первой компанией, которая разработала Apache Hive.
История Apache HBase начинается в 2006 году, когда стартап Powerset из Сан-Франциско пытался создать поисковую систему на естественном языке для Интернета. HBase - это реализация Google Bigtable. Осознавали ли мы когда-нибудь, почему возникла необходимость придумать еще одну архитектуру хранения? Система управления реляционными базами данных существует с начала 1970-х годов. Существует много вариантов использования, для которых реляционные базы данных имеют смысл, но для некоторых конкретных проблем реляционная модель не очень подходит.
Позвольте мне подробнее рассказать об Apache Hive и Apache HBase.
Различия между Apache Hive и Apache HBase
Apache Hive - это проект с открытым исходным кодом Apache, созданный на основе Hadoop, для запроса, обобщения и анализа больших наборов данных с использованием SQL-подобного интерфейса. Apache Hive предоставляет язык, похожий на SQL, называемый HiveQL, который прозрачно преобразует запросы в MapReduce для выполнения в больших наборах данных, хранящихся в распределенной файловой системе Hadoop (HDFS). Apache Hive - это кластерный компонент Hadoop, который обычно развертывается аналитиками данных. Улей Apache используется для пакетной обработки больших заданий ETL. Apache Hive также поддерживает пакетные запросы SQL для очень больших наборов данных. Apache Hive повышает гибкость проектирования схемы, а также сериализацию и десериализацию данных. Apache Hive не поддерживает онлайновую обработку транзакций (OLTP), поскольку куст не поддерживает запросы в режиме реального времени и обновления на уровне строк.
Apache HBase - это база данных NoSQL с открытым исходным кодом, которая обеспечивает доступ к большим наборам данных в режиме реального времени, чтение и запись. NoSQL это нереляционная база данных. Apache HBase - это распределенная база данных, ориентированная на столбцы, которая работает поверх распределенной файловой системы Hadoop (HDFS). Таким образом, HBase приносит преимущества NoSQL для Hadoop. Apache HBase обеспечивает возможности произвольного доступа к данным, присутствующим в HDFS. Он использует отказоустойчивость, обеспечиваемую HDFS. Пользователь может хранить данные в HDFS либо напрямую, либо через HBase.
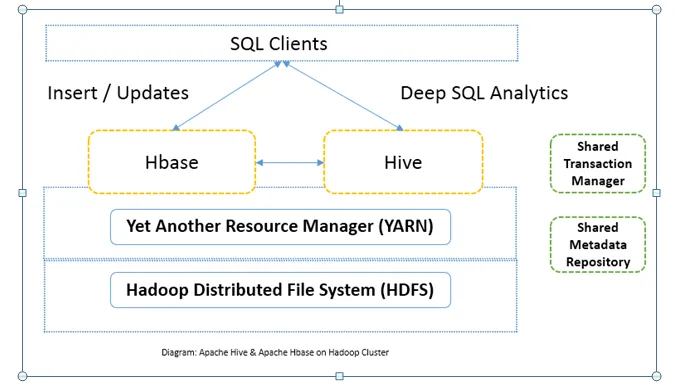
Сравнение лицом к лицу между Apache Hive и Apache HBase (Инфографика)
Ниже приведено 12 главных отличий между Apache Hive и Apache HBase

Ключевые отличия - Apache Hive против Apache HBase
Ниже приведены списки точек, описывающих ключевые различия между Apache Hive и Apache HBase:
- Apache HBase - это база данных, а Apache Hive - это движок базы данных.
- Apache Hive в основном используется для пакетной обработки (OLAP), а Apache HBase в основном используется для транзакционной обработки (OLTP).
- Apache Hive выполняет большинство запросов SQL, в то время как Apache HBase не разрешает запросы SQL напрямую.
- Apache Hive не поддерживает операции на уровне записи, такие как обновление, вставка и удаление, в то время как Apache HBase поддерживает операции на уровне записи, такие как обновление, вставка и удаление.
- Apache Hive работает поверх MapReduce, а Apache HBase работает поверх распределенной файловой системы Hadoop (HDFS).
Apache Hive запрашивает файлы путем определения виртуальной таблицы и выполнения HQL-запросов поверх нее. Это процесс, в котором файлы фактически связаны с таблицей, подобной структуре, и пользователь может выполнять язык запросов Hive (HQL), и эти запросы преобразуются в MapReduce Job с помощью Hive. Пользователю не нужно писать задание MapReduce, HQL-запросы внутренне преобразуются в файлы JAR, и эти файлы JAR будут реализованы в наборах данных.
В то время как в Apache HBase таблицы разбиты на регионы и обслуживаются серверами регионов. Дальнейшие регионы по семействам столбцов вертикально разделены на хранилища, и хранилища сохраняются в виде файлов в HDFS.
Когда использовать Apache Hive:
- Требования к хранилищу данных
- Аналитические Запросы
- Анализ данных, которые знакомы с SQL
Когда использовать Apache HBase:
- Быстрая и интерактивная обработка данных
- Запросы в реальном времени
- Быстрый поиск
- Серверная обработка
- Случайный доступ для чтения / записи больших данных
- Масштабируемость приложений
Apache Hive можно использовать для расчета трендов и журналов веб-сайта электронной коммерции для определенной продолжительности, региона или часового пояса. Он может использоваться для обработки пакетных запросов по историческим данным, в то время как Apache HBase может использоваться Facebook или LinkedIn для обмена сообщениями и анализа в реальном времени. Он также может быть использован для подсчета лайков.
Apache Hive против Apache HBase Сравнительная таблица
Я обсуждаю основные артефакты и различаю Apache Hive и Apache HBase.
| Apache Hive | Apache HBase | |
| Обработка данных | Apache Hive используется для
пакетная обработка, то есть интерактивная аналитическая обработка (OLAP) | Apache HBase используется для транзакционной обработки, то есть оперативной транзакционной обработки (OLTP) |
| Скорость обработки | Apache Hive имеет большую задержку из-за выполнения задания MapReduce в фоновом режиме | Apache HBase работает в режиме реального времени и намного быстрее, чем Apache Hive |
| Совместимость с Hadoop | Apache Hive работает поверх MapReduce | Apache HBase работает поверх HDFS |
| Определение | Apache Hive с открытым исходным кодом и похож на SQL, используемый для аналитических запросов | Apache HBase - база данных NoSQL с открытым исходным кодом, используемая для запросов в реальном времени. |
| Общие метаданные | Данные, созданные в Apache Hive, автоматически видны Apache HBase | Данные, созданные в Apache HBase, автоматически отображаются в Apache Hive. |
| схема | Улей Apache поддерживает схему для вставки данных в таблицы | Apache HBase - это база данных без схемы. |
| Обновить функцию | Функция обновления сложна в Apache Hive | Пользователь может очень легко обновить данные в Apache HBase |
| операции | Операции в Apache Hive не выполняются в режиме реального времени | Операции в Apache HBase выполняются в режиме реального времени |
| Типы данных | Apache Hive предназначен для структурированных и полуструктурированных данных | Apache HBase для неструктурированных данных. |
| Уровень согласованности | Улей Apache поддерживает согласованность | Apache HBase поддерживает немедленную согласованность |
| Методы разделов | Apache Hive поддерживает функции шардинга | Apache HBase также поддерживает функции шардинга |
| Хранилище данных | Дата хранится в Hive Metastore, разделах и корзинах в Apache Hive. | Данные хранятся в столбцах и рядах таблиц в Apache HBase |
Вывод - Apache Hive против Apache HBase
Обычно Apache Hive против Apache HBase используется вместе в одном кластере. Оба могут использоваться вместе для повышения вычислительной мощности. Поскольку улей улучшает аналитические аспекты HDFS, а HBase улучшает транзакции в режиме реального времени. Пользователь может использовать Hive в качестве инструмента ETL для пакетной вставки с данными в HBase, а затем для выполнения запросов, которые могут дополнительно объединить данные, представленные в таблицах HBase, с данными, которые уже присутствуют в HDFS. Данные можно читать и записывать из Apache Hive в HBase и обратно. Интерфейс между Apache Hive и Apache HBase все еще находится на стадии становления. Это еще не все. Тем не менее, я могу сказать, что оба Apache Hive против Apache HBase делают кластер Hadoop более надежным и мощным.
Статьи по Теме:
Это было руководство по Apache Hive против Apache HBase, их значению, сравнению «голова к голове», ключевым различиям, сравнительной таблице и выводам. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Топ 5 больших данных
- 5 проблем аналитики больших данных
- Как взломать интервью с разработчиком Hadoop?
- 5 проблем аналитики больших данных