

Разница между Apache Nifi и Apache Spark
До долгого времени, когда требовалась тяжелая работа, люди полагались на лошадей, чтобы тянуть тяжелые грузы, поддерживать скорость или что-то еще между ними. Однако не все лошади были пригодны для любой задачи. То же самое и в случае с технологиями сегодня. С появлением новых технологий, которые появляются каждый день, становится чрезвычайно важно знать их реальные приложения. Двумя такими технологиями являются Apache Nifi и Apache Spark, и мы собираемся изучить их в этом посте.
Apache Spark - это среда с открытым исходным кодом для кластерных вычислений, целью которой является предоставление интерфейса для программирования всего набора кластеров с неявной отказоустойчивостью и параллелизмом данных. Он использует RDD (устойчивые распределенные наборы данных) и обрабатывает данные в форме дискретизированных потоков, которые затем используются в аналитических целях.
Apache Nifi (сокращение от NiagaraFiles) - это еще один программный проект, целью которого является автоматизация потока данных между программными системами. Проект основан на модели потокового программирования, которая предоставляет функции, которые включают работу с кластерными возможностями. Это простая в использовании, надежная и мощная система для обработки и распространения данных. Он поддерживает масштабируемые ориентированные графы для маршрутизации данных, системного посредничества и логики преобразования. Давайте обсудим сравнения обеих тем.
Личное сравнение между Apache Nifi и Apache Spark (Инфографика)
Ниже приведены 9 лучших сравнений между Apache Nifi и Apache Spark.
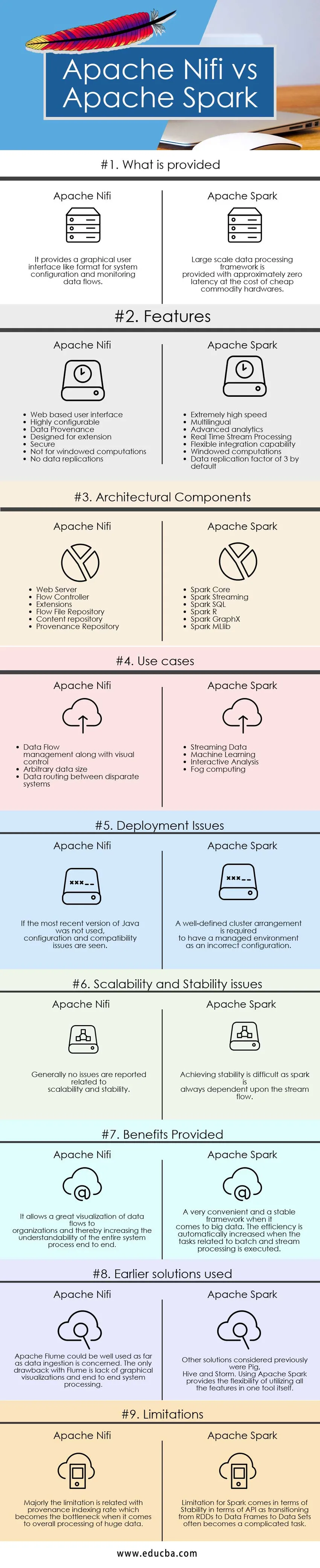
Ключевые различия между Apache Nifi и Apache Spark
Различия между Apache Nifi и Apache Spark объясняются в следующих пунктах:
- Apache Nifi - это инструмент приема данных, который используется для предоставления простой в использовании, мощной и надежной системы, облегчающей обработку и распределение данных по ресурсам, тогда как Apache Spark - это чрезвычайно быстрая технология кластерных вычислений, которая разработана для более быстрых вычислений эффективное использование интерактивных запросов, в управлении памятью и возможности обработки потоков.
- Apache Nifi работает в автономном режиме и режиме кластера, тогда как Apache Spark хорошо работает в локальном или автономном режиме, Mesos, Yarn и других видах кластерных режимов больших данных.
- Возможности Apache Nifi включают гарантированную доставку данных, эффективную буферизацию данных, приоритезированную организацию очередей, QoS для конкретного потока, Provenance данных, восстановление буферного буфера, визуальные команды и управление, шаблоны потоков, безопасность, возможности параллельной потоковой передачи, в то время как функции apache spark включают Lightning fast возможность быстрой обработки, многоязычность, вычисления в памяти, эффективное использование стандартных аппаратных систем, расширенная аналитика, эффективная интеграция.
- Apache Nifi обеспечивает лучшую читаемость и общее понимание системы, предоставляя возможности визуализации и функции перетаскивания. Потоком данных можно легко управлять и управлять с помощью традиционных методов и процессов, тогда как в случае Apache Spark для просмотра этих видов визуализации необходима система управления кластером, такая как Ambari. Apache Spark сам по себе не предоставляет возможностей визуализации и хорош только в том, что касается программирования. На сегодняшний день это очень удобная и стабильная система для обработки огромных объемов данных.
- Ограничение с Apache Nifi связано с тем, что является его преимуществом. Единственная функция перетаскивания обеспечивает ограничение невозможности масштабирования и обеспечения надежности, когда речь идет об интеграции его с другими компонентами и инструментами, тогда как в случае Apache Spark основным ограничением является использование обширного стандартного оборудования и управление им. иногда становится утомительной задачей. Другое известное ограничение связано с его возможностями потоковой передачи, относящимися к дискретизированному потоку и оконному или пакетному потоку, где преобразование СДР во фрейм данных и наборы данных иногда вызывает причину нестабильности.
Apache Nifi и Apache Spark Сравнительная таблица
| Основа сравнения | Apache Nifi | Apache Spark |
| Что предоставляется | Он предоставляет графический интерфейс пользователя, такой как формат для конфигурации системы и мониторинга потоков данных. | Среда крупномасштабной обработки данных обеспечивается с нулевой задержкой за счет дешевого аппаратного обеспечения. |
| Характеристики |
|
|
| Архитектурные компоненты |
|
|
| Случаи использования |
|
|
| Проблемы развертывания | Если последняя версия Java не использовалась, возникают проблемы с конфигурацией и совместимостью | Четко определенная структура кластера должна иметь управляемую среду в качестве неверной конфигурации |
| Проблемы масштабируемости и стабильности | Обычно не сообщается о проблемах, связанных с масштабируемостью и стабильностью. | Достижение стабильности затруднено, поскольку искра всегда зависит от потока потока. |
| Предоставленные преимущества | Это обеспечивает отличную визуализацию потоков данных для организаций и тем самым повышает понятность всего процесса системы от начала до конца | Очень удобная и стабильная структура для больших данных. Эффективность автоматически увеличивается, когда выполняются задачи, связанные с пакетной и потоковой обработкой. |
| Использованные ранее решения | Apache Flume может быть хорошо использован в том, что касается приема данных. Единственный недостаток Flume - отсутствие графической визуализации и сквозная обработка системы. | Другими решениями, рассмотренными ранее, были Pig, Hive и Storm. Использование Apache Spark обеспечивает гибкость использования всех функций в одном инструменте. |
| Ограничения | В основном это ограничение связано со скоростью индексации происхождения, которая становится узким местом, когда дело доходит до общей обработки огромных данных. | Ограничение Spark касается стабильности с точки зрения API, поскольку переход от СДР к фреймам данных к наборам данных часто становится сложной задачей. |
Вывод - Apache Nifi против Apache Spark
В заключение можно сказать, что Apache Spark - тяжелый боевой конь, а Apache Nifi - шустрый скакун. Оба имеют свои преимущества и ограничения для использования в своих областях. Вам нужно выбрать правильный инструмент для вашего бизнеса. Следите за новостями в нашем блоге, чтобы узнать больше о новых технологиях больших данных.
Рекомендуемая статья
Это было руководство по Apache Nifi против Apache Spark, их значению, сравнению «голова к голове», ключевым отличиям, сравнительной таблице и выводам. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Apache Hadoop против Apache Spark | 10 лучших сравнений, которые вы должны знать!
- Apache Storm против Apache Spark - узнайте 15 полезных отличий
- 7 важных вещей о Apache Spark (Руководство)
- Лучшие 15 вещей, которые нужно знать о MapReduce vs Spark