

Введение в Apache Flume
Apache Flume - это Data Ingestion Framework, который записывает данные на основе событий в распределенную файловую систему Hadoop. Известно, что Hadoop обрабатывает большие данные. Возникает вопрос, как данные, полученные с разных веб-серверов, передаются в файловую систему Hadoop? Ответ Apache Flume. Flume предназначен для приема больших объемов данных в Hadoop данных на основе событий.
Рассмотрим сценарий, в котором число веб-серверов генерирует файлы журналов, и эти файлы журналов необходимо передавать в файловую систему Hadoop. Flume собирает эти файлы как события и принимает их в Hadoop. Хотя Flume используется для передачи в Hadoop, нет строгого правила, согласно которому пункт назначения должен быть Hadoop. Flume способен писать в другие фреймворки, такие как Hbase или Solr.
Flume Architecture
В целом архитектура Apache Flume состоит из следующих компонентов:
- Источник дыма
- Flume Channel
- Раковина
- Flume Agent
- Flume Event
Давайте кратко рассмотрим каждый компонент Flume.
1. Источник дыма
Источник Flume присутствует в Генераторах данных, таких как Face book или Twitter. Источник собирает данные от генератора и передает эти данные в канал Flume в виде событий Flume. Flume поддерживает различные типы источников, такие как Avro Flume Source - подключается к порту Avro и получает события от внешнего клиента Avro, Thrift Flume Source - подключается к порту Thrift и получает события от внешних потоков клиентов Thrift, Spooling Directory Source и Kafka Flume Source.
2. Канал Flume
Промежуточное хранилище, которое буферизует события, отправляемые источником потока, пока они не будут поглощены приемником, называется каналом потока. Канал действует как промежуточный мост между Источником и Раковиной. Каналы Flume имеют транзакционный характер.
Flume обеспечивает поддержку файлового канала и канала памяти. Файловый канал имеет длительный характер, что означает, что после записи данных в канал они не будут потеряны, хотя при перезапуске агента. В памяти события канала хранятся в памяти, поэтому они не долговечны, но имеют очень быстрый характер.
3. Раковина
Flume Sink присутствует в репозиториях данных, таких как HDFS, HBase. Поток Flume получает события из Channel и сохраняет их в хранилищах назначения, таких как HDFS. Не существует правила, согласно которому приемник должен доставлять события в Store, вместо этого мы можем настроить его таким образом, чтобы приемник мог доставлять события другому агенту. Flume поддерживает различные приемники, такие как HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
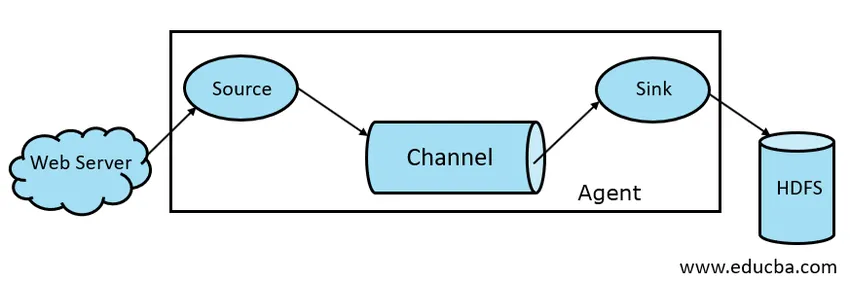
Рис 1.1 Базовая архитектура Flume
4. Flume Agent
Агент Flume - это длительный Java-процесс, который работает по принципу «комбинация источник - канал - приемник». Flume может иметь более одного агента. Мы можем рассматривать Flume как совокупность связанных агентов Flume, которые распространены в природе.
5. Flume Event
Событие - это единица данных, передаваемых в Flume . Общее представление объекта данных в Flume называется Event. Событие состоит из полезной нагрузки байтового массива с необязательными заголовками.
Рабочая Flume
Flume agent - это Java-процесс, который состоит из Source - Channel - Sink в его самой простой форме. Источник собирает данные из генератора данных в виде событий и доставляет их в канал. Источник может доставлять на несколько каналов в соответствии с требованием. Разветвление - это процесс, при котором один источник записывает данные на несколько каналов, чтобы их можно было доставлять нескольким приемникам.
Событие - это основная единица данных, передаваемых в Flume. Канал буферизует данные, пока они не будут приняты Sink. Sink собирает данные из Channel и доставляет их в централизованное хранилище данных, такое как HDFS, или Sink может пересылать эти события другому агенту Flume в соответствии с требованиями.
Flume поддерживает транзакции. Для достижения надежности Flume использует отдельные транзакции от источника к каналу и от канала к приемнику. Если события не доставляются, то транзакция откатывается и позже доставляется.
Чтобы понять, как работает Flume, давайте рассмотрим пример конфигурации Flume, где источником является папка спулинга, а источником - Hdfs. В этом примере агент Flume имеет простейшую форму, т.е. топологию с одним источником - каналом-приемником, которая настроена с использованием файла свойств Java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
В приведенном выше примере конфигурации агент - это база, с помощью которой мы определяем другие свойства. source1 и sink1 и channel1 являются названиями источника, приемника и канала соответственно, и их типы и местоположения также упоминаются соответственно.
Преимущества Apache Flume
- Flume является масштабируемым, надежным и отказоустойчивым по своей природе. Эти свойства подробно обсуждаются ниже
- Масштабируемость - Flume масштабируется по горизонтали, т.е. мы можем добавлять новые узлы согласно нашему требованию
- Надежный - Apache Flume поддерживает транзакции и гарантирует, что никакие данные не будут потеряны в процессе передачи данных. Он имеет различные транзакции от источника к каналу и от канала к источнику.
- Flume настраивается и обеспечивает поддержку различных источников и приемников, таких как Kafka, Avro, каталог спулинга, Thrift и т. Д.
- В Flume один источник может передавать данные в несколько каналов, и эти каналы, в свою очередь, будут передавать данные в несколько приемников, поэтому один источник может передавать данные в несколько приемников. Этот механизм называется Fan out. Flume также поддерживает Fan out.
- Flume обеспечивает стабильный поток передачи данных, т.е. если скорость чтения данных увеличивается, а затем скорость записи данных также увеличивается.
- Хотя Flume обычно записывает данные в централизованное хранилище, такое как HDFS или Hbase, мы можем настроить Flume в соответствии с нашим требованием, чтобы Sink мог записывать данные в другой агент. Это показывает гибкость Flume
- Apache Flume является открытым исходным кодом.
Вывод
В этой статье Flume подробно рассматриваются компоненты Flume и работа Flume. Flume - это гибкая, надежная и масштабируемая платформа для передачи данных в централизованное хранилище, такое как HDFS. Его способность интегрироваться с различными приложениями, такими как Kafka, Hdfs, Thrift, делает его жизнеспособным вариантом для приема данных.
Рекомендуемые статьи
Это было руководство по Apache Flume. Здесь мы обсудим архитектуру, работу и преимущества Apache Flume. Вы также можете взглянуть на следующие статьи, чтобы узнать больше -
- Что такое Apache Flink?
- Разница между Apache Kafka и Flume
- Архитектура больших данных
- Инструменты Hadoop
- Узнайте о различных событиях JavaScript