

Введение в команды Spark
Apache Spark - это фреймворк, построенный на основе Hadoop для быстрых вычислений. Он расширяет концепцию MapReduce в кластерном сценарии для эффективного запуска задачи. Команда Spark написана на языке Scala.
Hadoop может использоваться Spark следующими способами (см. Ниже):
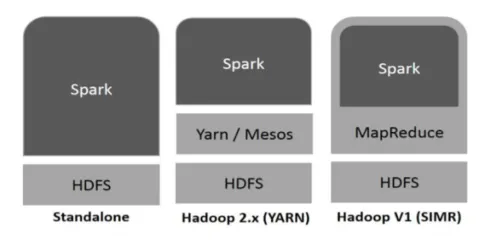
Рисунок 1
https://www.tutorialspoint.com/
- Автономный: Spark, прямо развернутый поверх Hadoop. Задания Spark выполняются параллельно в Hadoop и Spark.
- Hadoop YARN: Spark работает на Yarn без предварительной установки.
- Spark в MapReduce (SIMR): Spark в MapReduce используется для запуска искрового задания в дополнение к автономному развертыванию. С SIMR можно запустить Spark и использовать его оболочку без какого-либо административного доступа.
Компоненты Spark:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLib
- Graphx
Эластичные распределенные наборы данных (RDD) рассматриваются как фундаментальная структура данных команд Spark. СДР является неизменным и доступен только для чтения. Все виды вычислений в командах spark выполняются с помощью преобразований и действий над RDD.
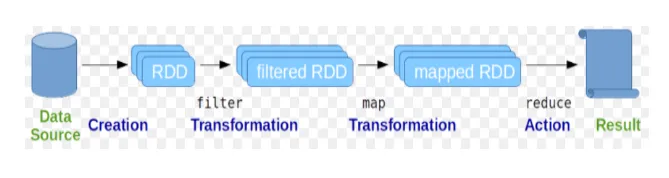
Рис 2
Google Image
Оболочка Spark предоставляет пользователям среду взаимодействия с ее функциональными возможностями. Команды Spark содержат множество различных команд, которые можно использовать для обработки данных в интерактивной оболочке.
Основные искровые команды
Давайте посмотрим на некоторые из основных команд Spark, которые приведены ниже:
-
Чтобы запустить оболочку Spark:

Рис 3
-
Чтение файла из локальной системы:

Здесь «sc» - искровой контекст. Учитывая, что «data.txt» находится в домашнем каталоге, он читается так, иначе нужно указать полный путь.
-
Создать RDD через распараллеливание

NewData сейчас является СДР.
-
Подсчет предметов в СДР

-
Collect
Эта функция возвращает весь контент RDD в программу драйвера. Это полезно при отладке на разных этапах написания программы.
-
Прочитайте первые 3 пункта из RDD

-
Сохранить выходные / обработанные данные в текстовый файл

Здесь папка «output» - это текущий путь.
Промежуточные искровые команды
1. Фильтр на СДР
Давайте создадим новую СДР для предметов, которые содержат «да».

Фильтр преобразования должен быть вызван в существующем СДР для фильтрации по слову «да», что создаст новый СДР с новым списком элементов.
2. Цепная операция

Здесь преобразование фильтра и действие счета действовали вместе. Это называется цепной операцией.
3. Прочитайте первый пункт из RDD

4. Подсчет разделов RDD
Как известно, СДР состоит из нескольких разделов, возникает необходимость подсчета нет. перегородок. Как это помогает в настройке и устранении неполадок при работе с командами Spark.

По умолчанию минимум нет. пф раздел 2.
5. присоединиться
Эта функция объединяет две таблицы (элемент таблицы попарно) на основе общего ключа. В попарно RDD первый элемент является ключом, а второй элемент является значением.
6. Кэшируйте файл
Кэширование - это метод оптимизации. Кэширование RDD означает, что RDD будет находиться в памяти, и все последующие вычисления будут выполняться на этих RDD в памяти. Это экономит время чтения диска и улучшает производительность. Короче говоря, это сокращает время доступа к данным.

Однако данные не будут кешироваться, если вы запустите функцию выше. Это можно доказать, посетив веб-страницу:
HTTP: // локальный: 4040 / хранения
СДР будет кэшироваться, как только действие будет выполнено. Например:

Еще одна функция, которая работает подобно cache (), это persist (). Persist дает пользователям гибкость в предоставлении аргумента, который может помочь кэшировать данные в памяти, на диске или вне динамической памяти. Persist без аргументов работает так же, как cache ().
Расширенные команды зажигания
Давайте посмотрим на некоторые из продвинутых команд Spark, которые приведены ниже:
-
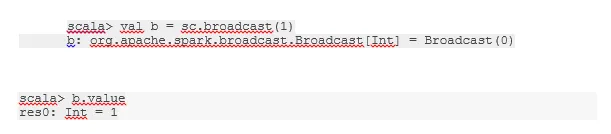
Трансляция переменной
Широковещательная переменная помогает программисту хранить в памяти единственную переменную, кэшированную на каждой машине в кластере, а не отправлять копию этой переменной вместе с задачами. Это помогает в снижении затрат на связь.
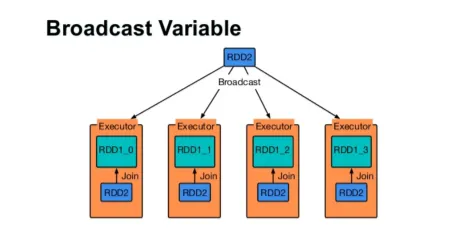
Рис 4
Google Image
Короче говоря, есть три основных свойства переменной Broadcastted:
- Неизменный
- Вписаться в память
- Распределено по кластеру
-
Аккумуляторы
Аккумуляторы - это переменные, которые добавляются к связанным операциям. Существует много вариантов использования аккумуляторов, таких как счетчики, суммы и т. Д.

Имя аккумулятора в коде также можно увидеть в Spark UI.
-
карта
Функция карты помогает перебирать каждую строку в RDD. Функция, используемая в карте, применяется к каждому элементу в СДР.
Например, в СДР (1, 2, 3, 4, 6), если мы применим «rdd.map (x => x + 2)», мы получим результат как (3, 4, 5, 6, 8).
-
Flatmap
Flatmap работает аналогично карте, но карта возвращает только один элемент, тогда как flatmap может возвращать список элементов. Следовательно, для разбиения предложений на слова потребуется плоская карта.
-
Coalesce
Эта функция помогает избежать перемешивания данных. Это применяется в существующем разделе, чтобы меньше данных перемешивалось. Таким образом, мы можем ограничить использование узлов в кластере.
Советы и рекомендации по использованию искровых команд
Ниже приведены различные советы и хитрости команд Spark: -
- Новички Spark могут использовать Spark-shell. Как команды Spark построены на Scala, так что использование scala spark определенно прекрасно. Тем не менее, Python Spark Shell также доступен, так что даже это то, что можно использовать, кто хорошо разбирается в Python.
- Оболочка Spark имеет множество опций для управления ресурсами кластера. Ниже команда может помочь вам в этом:

- В Spark работа с длинными наборами данных - обычное дело. Но дела идут плохо, когда принимаются плохие данные. Всегда полезно отбрасывать плохие строки, используя функцию фильтра Spark. Хороший набор входных данных будет отличным выбором.
- Spark самостоятельно выбирает хороший раздел для ваших данных. Но всегда полезно следить за разделами, прежде чем приступить к работе. Испытание различных разделов поможет вам с параллелизмом вашей работы.
Вывод - Spark Commands:
Команда Spark - это революционный и универсальный механизм обработки больших данных, который может работать с пакетной обработкой, обработкой в реальном времени, кэшированием данных и т. Д. В Spark имеется богатый набор библиотек машинного обучения, которые позволяют ученым и аналитическим организациям создавать надежные, интерактивные и быстрые приложения.
Рекомендуемые статьи
Это было руководство к командам Spark. Здесь мы обсудили как базовые, так и расширенные команды Spark и некоторые непосредственные команды Spark. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Adobe Photoshop Commands
- Важные команды VBA
- Табличные команды
- Шпаргалка SQL (команды, бесплатные советы и хитрости)
- Типы объединений в Spark SQL (примеры)
- Spark Компоненты | Обзор и 6 основных компонентов