
Что такое линейная регрессия в R?
Линейная регрессия является наиболее популярным и широко используемым алгоритмом в области статистики и машинного обучения. Линейная регрессия - это метод моделирования, позволяющий понять взаимосвязь между входными и выходными переменными. Здесь переменные должны быть числовыми. Линейная регрессия происходит из того факта, что выходная переменная является линейной комбинацией входных переменных. Выходные данные обычно представлены «у», тогда как входные данные представлены «х».
Линейная регрессия в R может быть разделена на две категории
-
Сдвоенная линейная регрессия
Это регрессия, в которой выходная переменная является функцией одной входной переменной. Представление простой линейной регрессии:
у = с0 + с1 * х1
-
Множественная линейная регрессия
Это регрессия, где выходная переменная является функцией переменной с несколькими входами.
у = с0 + с1 * х1 + с2 * х2
В обоих вышеупомянутых случаях c0, c1, c2 являются коэффициентами, которые представляют веса регрессии.
Линейная регрессия в R
R - очень мощный статистический инструмент. Итак, давайте посмотрим, как можно выполнить линейную регрессию в R и как можно интерпретировать ее выходные значения.
Давайте подготовим набор данных, чтобы выполнить и понять линейную регрессию сейчас.
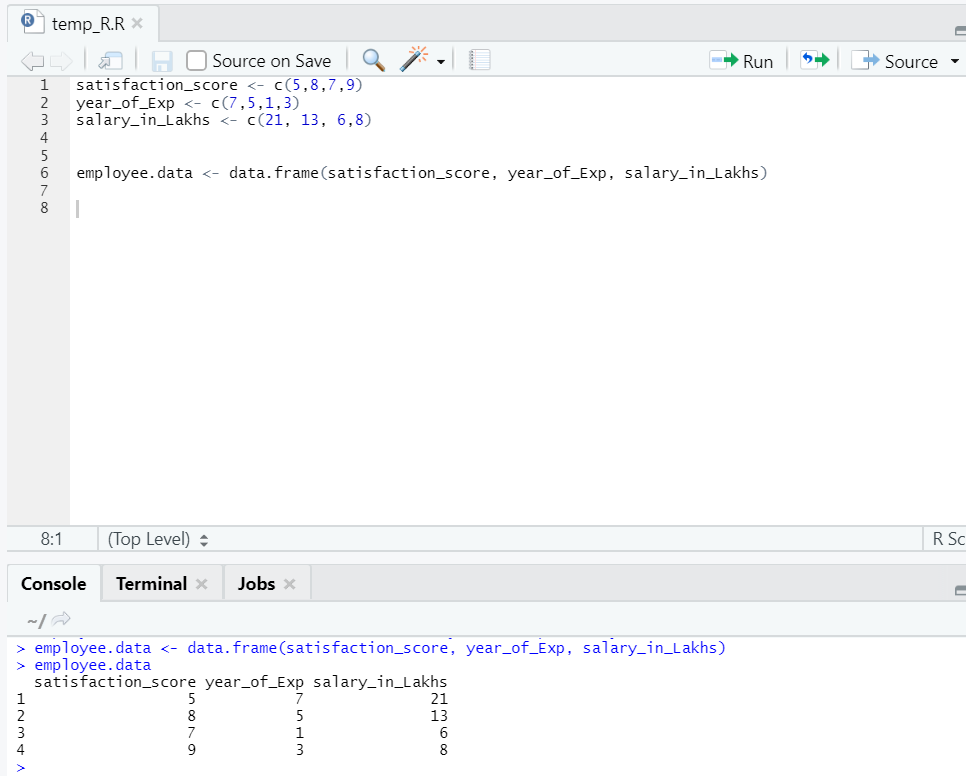
Теперь у нас есть набор данных, где «compatibility_score» и «year_of_Exp» являются независимой переменной. Salary_in_lakhs - выходная переменная.
Ссылаясь на вышеупомянутый набор данных, проблема, которую мы хотим решить здесь с помощью линейной регрессии:
Оценка заработной платы работника, основанная на его годовом опыте и оценке удовлетворенности в его компании.
R код линейной регрессии:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
Вывод приведенного выше кода будет:
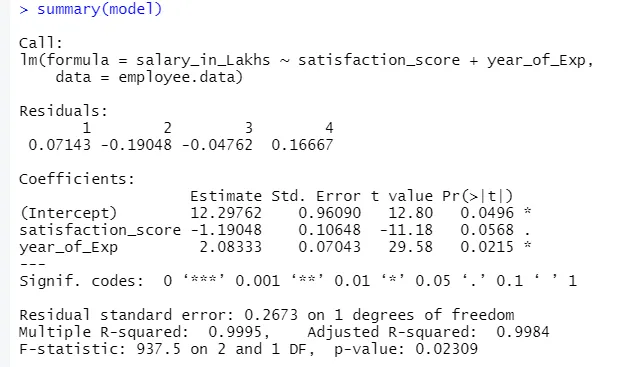
Формула регрессии становится
Y = 12, 29-1, 19 * оценка удовлетворенности + 2, 08 × 2 * year_of_Exp
В случае, если есть несколько входов в модель.
Тогда код R может быть:
модель <- lm (salary_in_Lakhs ~., data = employee.data)
Однако, если кто-то хочет выбрать переменную из нескольких входных переменных, есть несколько методов, таких как «Обратное исключение», «Прямой выбор» и т. Д., Чтобы сделать это также.
Интерпретация линейной регрессии в R
Ниже приведены некоторые интерпретации линейной регрессии в r:
1.Residuals
Это относится к разнице между фактическим откликом и прогнозируемым откликом модели. Таким образом, для каждой точки будет один фактический ответ и один прогнозируемый ответ. Следовательно, остатков будет столько же, сколько наблюдений. В нашем случае у нас есть четыре наблюдения, следовательно, четыре остатка.

2.Coefficients
В дальнейшем мы найдем секцию коэффициентов, которая изображает точку пересечения и наклон. Если кто-то хочет прогнозировать зарплату сотрудника на основе его опыта и оценки удовлетворенности, необходимо разработать формулу формулы, основанную на уклоне и перехвате. Эта формула поможет вам в прогнозировании заработной платы. Перехват и наклон помогают аналитику найти лучшую модель, которая подходит точным точкам данных.
Наклон: изображает крутизну линии.
Перехват: место, где линия пересекает ось.
Давайте разберемся, как формируется формула на основе наклона и пересечения.
Скажем, перехват 3 и наклон 5.
Итак, формула у = 3 + 5х . Это означает, что если x увеличивается на единицу, y увеличивается на 5.
коэффициент - оценка
При этом перехват обозначает среднее значение выходной переменной, когда все входные данные становятся равными нулю. Таким образом, в нашем случае зарплата в лакхах составит 12, 29 лакхов, так как средний показатель с учетом степени удовлетворенности и опыта равен нулю. Здесь наклон представляет собой изменение выходной переменной с единичным изменением входной переменной.
Коэффициент эффективности - стандартная ошибка
Стандартная ошибка - это оценка ошибки, которую мы можем получить при расчете разницы между фактическим и прогнозируемым значением нашей переменной отклика. В свою очередь, это говорит о достоверности взаимосвязи входных и выходных переменных.
c.Cofficient - значение t
Это значение дает уверенность, чтобы отклонить нулевую гипотезу. Чем больше значение от нуля, тем больше уверенность, чтобы отвергнуть нулевую гипотезу и установить связь между выходной и входной переменной. В нашем случае значение также далеко от нуля.
д. Коэффициент - Pr (> t)
Эта аббревиатура в основном изображает значение р. Чем ближе он к нулю, тем легче мы можем отвергнуть нулевую гипотезу. Линия, которую мы видим в нашем случае, это значение близко к нулю, мы можем сказать, что существует связь между пакетом заработной платы, оценкой удовлетворенности и годом опыта.

Остаточная стандартная ошибка
Это изображает ошибку в прогнозировании переменной ответа. Чем оно ниже, тем выше точность модели.
Несколько R-квадрат, скорректированный R-квадрат
R-квадрат является очень важной статистической мерой для понимания того, насколько близко данные вписываются в модель. Следовательно, в нашем случае, насколько хорошо наша модель, которая является линейной регрессией, представляет собой набор данных.
Значение R-квадрата всегда лежит между 0 и 1. Формула:

Чем ближе значение к 1, тем лучше модель описывает наборы данных и их дисперсию.
Однако, когда в изображение входит более одной входной переменной, скорректированное значение R в квадрате является предпочтительным.
F-статистика
Это сильная мера для определения взаимосвязи между входной и ответной переменной. Чем больше значение, чем 1, тем выше достоверность взаимосвязи между входной и выходной переменными.
В нашем случае это «937, 5», что относительно больше, учитывая объем данных. Следовательно, отклонение нулевой гипотезы становится легче.
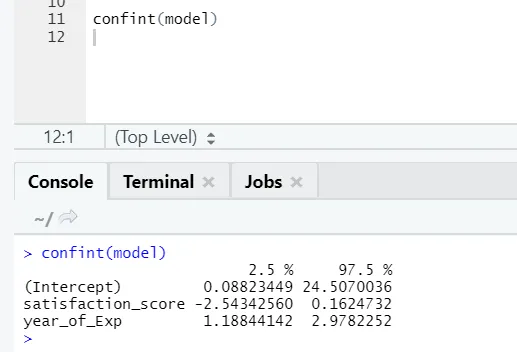
Если кто-то хочет увидеть доверительный интервал для коэффициентов модели, вот способ сделать это:
Визуализация регрессии
Код R:
сюжет (salary_in_Lakhs ~ удовлетворение_score + year_of_Exp, data = employee.data)
abline (модель)
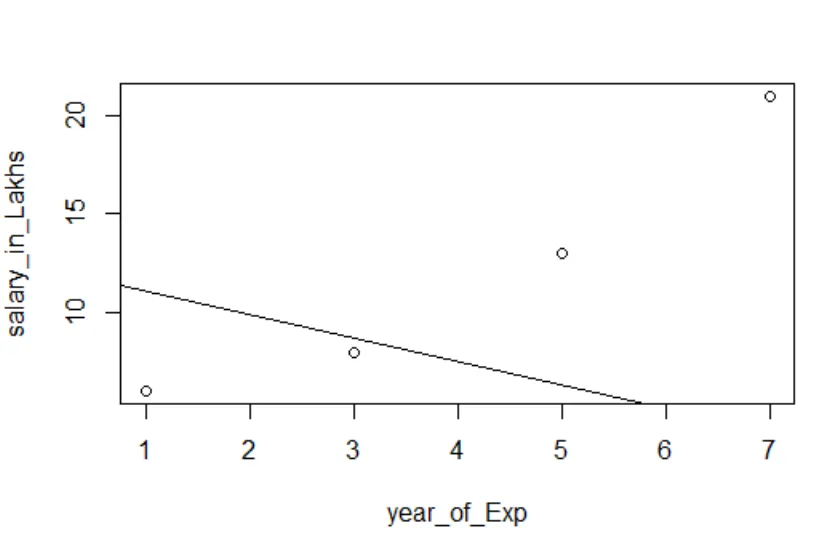
Всегда лучше собирать все больше и больше очков, прежде чем подходить к модели.
Вывод - линейная регрессия в R
Линейная регрессия - это простая, простая в использовании, простая для понимания, но очень мощная модель. Мы увидели, как можно выполнить линейную регрессию на R. Мы также попытались интерпретировать результаты, которые могут помочь вам в оптимизации модели. Как только вы освоитесь с простой линейной регрессией, вы должны попробовать множественную линейную регрессию. Наряду с этим, поскольку линейная регрессия чувствительна к выбросам, необходимо изучить ее, прежде чем перейти непосредственно к подгонке к линейной регрессии.
Рекомендуемые статьи
Это руководство по линейной регрессии в R. Здесь мы обсудим, что такое линейная регрессия в R? категоризация, визуализация и интерпретация R. Вы также можете просмотреть другие наши предлагаемые статьи, чтобы узнать больше -
- Прогнозирующее моделирование
- Логистическая регрессия в R
- Дерево решений в R
- R Интервью Вопросы
- Основные отличия регрессии от классификации
- Руководство по дереву решений в машинном обучении
- Линейная регрессия против логистической регрессии | Основные отличия