

Разница между Hadoop и Hive
Hadoop:
Hadoop - это платформа или программное обеспечение, которое было изобретено для управления большими данными или большими данными. Hadoop используется для хранения и обработки больших данных, распределенных по кластеру обычных серверов.
Hadoop хранит данные, используя распределенную файловую систему Hadoop, и обрабатывает / запрашивает их, используя модель программирования Map Reduce.
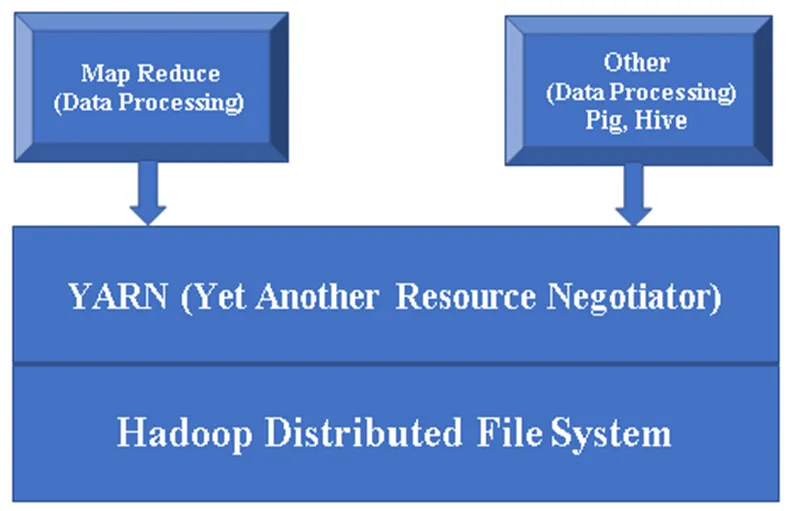
Рисунок 1. Базовая архитектура компонента Hadoop.
Основные компоненты Hadoop:
Hadoop Base / Common: Hadoop common предоставит вам одну платформу для установки всех его компонентов.
HDFS (распределенная файловая система Hadoop): HDFS является основной частью инфраструктуры Hadoop, которая заботится обо всех данных в кластере Hadoop. Он работает на архитектуре Master / Slave и хранит данные с использованием репликации.
Ведущая / ведомая архитектура и репликация:
- Главный узел / узел имени: узел имени хранит метаданные каждого блока / файла, хранящегося в HDFS, HDFS может иметь только один мастер-узел (в случае HA другой мастер-узел будет работать в качестве вторичного мастер-узла).
- Slave Node / Data Node: Узлы данных содержат фактические файлы данных в блоках. HDFS может иметь несколько узлов данных.
- Репликация: HDFS хранит свои данные, разделяя их на блоки. Размер блока по умолчанию составляет 64 МБ. Из-за того, что данные репликации сохраняются в 3 (коэффициент репликации по умолчанию, может быть увеличен в соответствии с требованием) различных узлов данных, следовательно, существует наименьшая вероятность потери данных в случае сбоя любого узла.
YARN (еще один согласователь ресурсов): он в основном используется для управления ресурсами Hadoop, а также играет важную роль в планировании пользовательских приложений.
MR (Map Reduce): это базовая модель программирования Hadoop. Он используется для обработки / запроса данных в рамках Hadoop.
Hive:
Hive - это приложение, которое работает на платформе Hadoop и предоставляет SQL-подобный интерфейс для обработки / запроса данных. Hive спроектирован и разработан Facebook, прежде чем стать частью проекта Apache-Hadoop.
Hive выполняет свой запрос, используя HQL (язык запросов Hive). Hive имеет ту же структуру, что и RDBMS, и в Hive можно использовать почти те же команды.
Hive может хранить данные во внешних таблицах, поэтому использовать HDFS не обязательно, а также он поддерживает форматы файлов, такие как ORC, файлы Avro, файлы последовательностей, текстовые файлы и т. Д.
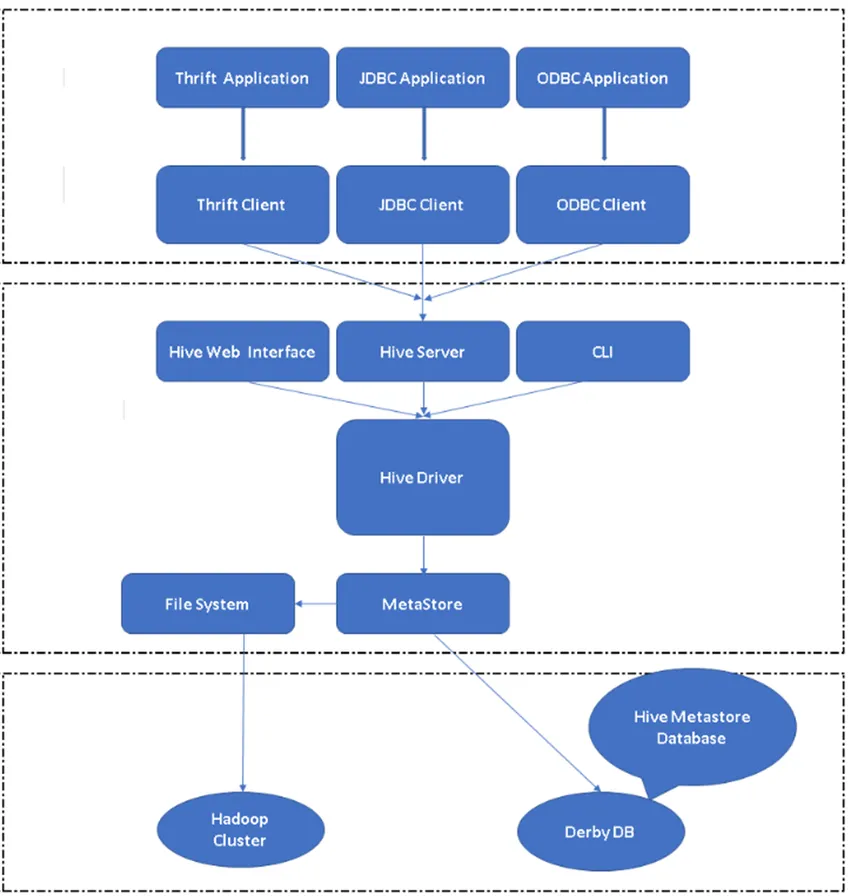
Рисунок 2, Архитектура Hive и его основные компоненты.
Основной компонент улья:
Клиенты Hive. Hive также поддерживает языки программирования, такие как Java, C, Python, с использованием различных драйверов, таких как ODBC, JDBC и Thrift. Можно написать любое клиентское приложение Hive на других языках и запустить в Hive с помощью этих Клиентов.
Службы Hive. В службах Hive выполняются команды и запросы. У веб-интерфейса Hive есть пять подкомпонентов.
- CLI: интерфейс командной строки по умолчанию, предоставляемый Hive для выполнения запросов / команд Hive.
- Веб-интерфейсы Hive: это простой графический интерфейс пользователя. Это альтернатива командной строке Hive и используется для запуска запросов и команд в приложении Hive.
- Сервер Hive: он также называется Apache Thrift. Он отвечает за получение команд из разных интерфейсов командной строки и отправку всех команд / запросов в Hive, а также для получения окончательного результата.
- Драйвер Apache Hive: он отвечает за получение клиентом входных данных от интерфейсов командной строки, веб-интерфейса пользователя, ODBC, JDBC или Thrift и передает эту информацию в metastore, где хранится вся информация о файле.
- Metastore: Metastore - это хранилище для хранения всей информации метаданных Hive. Метаданные Hive хранят такую информацию, как структура таблиц, разделов, типов столбцов и т. Д.
Хранилище Hive. Это место, где выполняется фактическая задача. Все запросы, выполняемые из Hive, выполняли действие внутри хранилища Hive.
Сравнение лицом к лицу между Hadoop и Hive (Инфографика)
Ниже представлено 8 лучших отличий Hadoop от Hive.
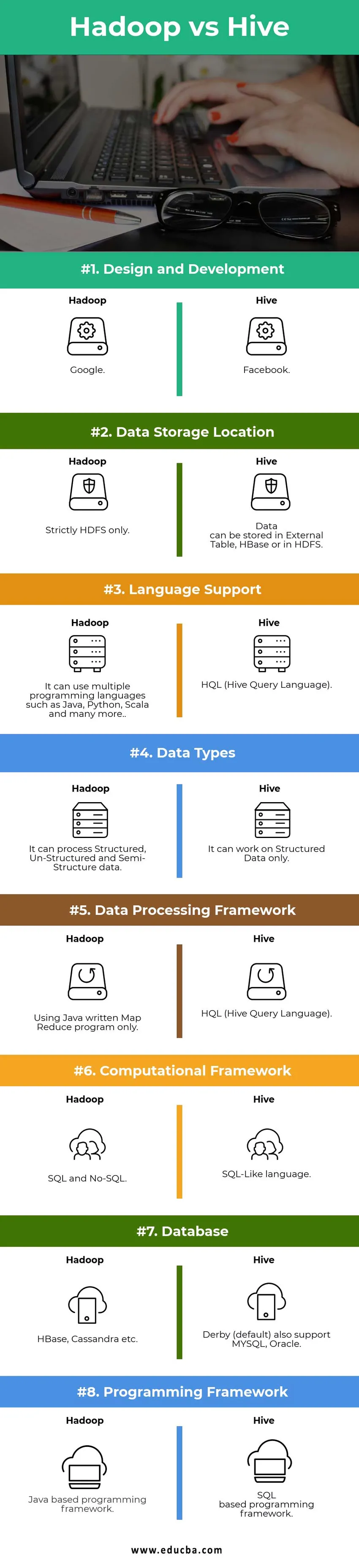
Ключевые различия между Hadoop и Hive:
Ниже приведены списки точек, описывающих ключевые различия между Hadoop и Hive:
1) Hadoop - это среда для обработки / запроса больших данных, в то время как Hive - это инструмент на основе SQL, основанный на Hadoop для обработки данных.
2) Hive обрабатывает / запрашивает все данные, используя HQL (Hive Query Language), это SQL-подобный язык, в то время как Hadoop может понимать только Map Reduce.
3) Map Reduce является неотъемлемой частью Hadoop. Сначала запрос Hive преобразуется в Map Reduce, а не обрабатывается Hadoop для запроса данных.
4) Hive работает с запросом SQL Like, в то время как Hadoop понимает его, используя только Map Reduce на основе Java.
5) В Hive ранее использовавшиеся традиционные команды «Реляционной базы данных» также можно использовать для запроса больших данных, в то время как в Hadoop приходится писать сложные программы Map Reduce с использованием Java, что не похоже на традиционную Java.
6) Hive может обрабатывать / запрашивать только структурированные данные, тогда как Hadoop предназначен для всех типов данных, будь то структурированные, неструктурированные или полуструктурированные.
7) Используя Hive, можно обрабатывать / запрашивать данные без сложного программирования, в то время как в экосистеме Simple Hadoop необходимо написать сложную Java-программу для тех же данных.
8) Односторонним структурам Hadoop требуется строка 100 с для подготовки MR-программы на Java, с другой стороны Hadoop с Hive может запрашивать те же данные, используя от 8 до 10 строк HQL.
9) В Hive очень сложно вставить выходные данные одного запроса в качестве входных данных другого запроса, в то время как тот же запрос можно легко выполнить с помощью Hadoop с MR.
10) Наличие Metastore в кластере Hadoop не обязательно, в то время как Hadoop хранит все свои метаданные в HDFS (распределенная файловая система Hadoop).
Сравнительная таблица Hadoop и Hive
| Точки сравнения | улей | Hadoop |
|
Дизайн и развитие | ||
| Место хранения данных |
Данные могут храниться в External Таблица, HBase или в HDFS. | Только HDFS. |
| Языковая поддержка | HQL (Hive Query Language) |
Он может использовать несколько языков программирования, таких как Java, Python, Scala и многие другие. |
| Типы данных | Он может работать только на структурированных данных. |
Он может обрабатывать структурированные, неструктурированные и полуструктурные данные. |
| Структура обработки данных |
HQL (Hive Query Language) | Использование только написанной на Java программы Map Reduce. |
|
Вычислительная структура | SQL-подобный язык. | SQL и No-SQL. |
| База данных |
Derby (по умолчанию) также поддерживает MYSQL, Oracle… | HBase, Кассандра и т. Д. |
| Рамки программирования |
Основы программирования на основе SQL. | Основы программирования на основе Java. |
Вывод - Hadoop против Hive
Hadoop и Hive используются для обработки больших данных. Hadoop - это платформа, которая предоставляет платформу для других приложений для запроса / обработки больших данных, в то время как Hive - это просто приложение на основе SQL, которое обрабатывает данные с использованием HQL (Hive Query Language)
Hadoop можно использовать без Hive для обработки больших данных, в то время как Hive без Hadoop нелегко.
В заключение, мы не можем сравнивать Hadoop и Hive в любом случае и в любом аспекте. И Hadoop, и Hive совершенно разные. Совместное использование обеих технологий может сделать процесс запроса больших данных намного проще и удобнее для пользователей больших данных.
Рекомендуемые статьи:
Это было руководство по Hadoop vs Hive, их значению, сравнению «голова к голове», ключевым различиям, сравнительной таблице и выводам. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Hadoop vs Apache Spark - Интересные вещи, которые нужно знать
- HADOOP vs RDBMS | Знай 12 полезных отличий
- Как большие данные меняют лицо здравоохранения
- 12 лучших сравнений Apache Hive и Apache HBase (Инфографика)
- Удивительный гид по Hadoop vs Spark