

Введение в XPath
XPath является основным и основным компонентом стандарта XSLT. XPath может использоваться для обхода элементов, атрибутов, текста, инструкций по обработке, комментариев, пространства имен и документа в документе расширяемого языка разметки (XML). Это рекомендация W3C, которая содержит библиотеку с более чем 200 встроенными функциями. XPath - это синтаксис для определения частей документа XML. XSLT - это язык таблиц стилей для файлов XML. С XSLT вы можете преобразовывать XML-документы в другие форматы, такие как XHTML. XQuery - это запрос данных XML. XQuery предназначен для запроса всего, что может отображаться в формате XML, включая базы данных. Ссылки в XML делятся на две части: XLink и XPointer. XLink и XPointer определяют стандартный способ создания гиперссылок в документах XML.
Выражение XPath
XPath позволяет различным типам выражений извлекать соответствующую информацию из документа XML. XPath обращается к определенной части документа. Он моделирует XML-документ как дерево узлов. Выражение XPath - это метод навигации и выбора узлов в документе.
Выражения XPath могут использоваться в C, C ++, Python, Java, JavaScript, PHP, XML Schema и многих других языках. Выражение XPath относится к шаблону для выбора набора узлов. XPointer использует эти шаблоны для решения задач или для выполнения преобразований с помощью XSLT. Выражение XPath указывает семь типов узлов, которые могут быть результатом выполнения.
1. Root
Корневой элемент документа XML. Используя следующие способы, можно найти корневые элементы.
- Использовать подстановочный знак (/ *): для выбора корневого узла
- Использовать имя (/ класс): чтобы выбрать корневой узел по имени
- Использовать имя с подстановочным знаком (/ class / *): чтобы выбрать все элементы в корневом узле
Код:
2. Элемент
Элемент узла документа XML. Ниже приведены способы найти элемент
- / class / *: используется для выбора всех элементов под корневым узлом.
- / class / library: используется для выбора всех элементов библиотеки из корневого узла.
- // библиотека: используется для выбора всего элемента библиотеки из документа.
Код:
3. Атрибуты
Атрибут узла элемента в документе XML, извлеченный и проверенный с использованием @ attribute-name элемента.
Код:
4. Текст
Текст узла элемента в документе XML, извлеченный и проверенный по имени элемента.
Код:
5. Комментарий
Пример комментария
Код:
Узел или Список узла из XML
Ниже приведен список полезных выражений для выбора узла или списка узлов из документа XML.
- '/': Использование этого выбора начинается с корневого узла.
- '//': использование этого выбора начинается с текущего узла, который соответствует выбору
- '.': Для выбора текущего используется это выражение.
- '..': для выбора родительского узла текущего узла.
- '@': Для выбора атрибутов.
Пример XPath
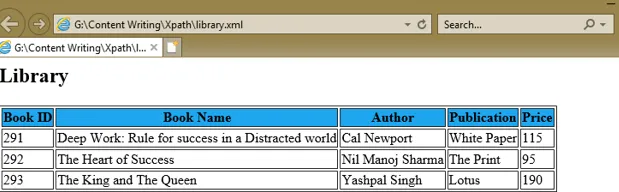
Чтобы понять выражение XPath, мы создали XML-документ library.xml и его документ таблицы стилей library.xsl, который использует выражения XPath в атрибуте select различных тегов XSL для получения значений идентификатора книги, имени книги, автор, публикация и цена каждого книжного узла.
1. library.xml
Код:
Deep Work: Rule for success in a Distracted world
Cal Newport
White Paper
115
The Heart of Success
Nil Manoj Sharma
The Print
95
The King and The Queen
Yashpal Singh
Lotus
190
2. library.xsl
Код:
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
| | | | |
|---|---|---|---|---|
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
Выход:
Преимущества XPath
Ниже приведены преимущества Xpath:
- Запросы XPath просты для ввода и чтения, а также компактны.
- Синтаксис XPath прост в общих и простых случаях.
- Строки запроса легко встраиваются в скрипты, программы и атрибуты HTML или XML.
- Запросы XPath легко анализируются.
- Любой узел может однозначно распознать в XML-документе.
- В XML-документе может быть указано наличие любого пути или любого набора условий для узлов в пути.
- Запросы возвращают любое количество результатов, включая ноль.
- В документе XML условия запроса могут быть рассчитаны на любом уровне и не должны проходить от верхнего узла документа XML.
- Запросы XPath возвращают уникальные узлы, а не повторяющиеся узлы.
- Во многих случаях XPath используется для предоставления ссылок на узлы, для поиска хранилищ и многих других приложений.
- Для программистов запросы XPath не процедурные, а скорее декларативные. Они определяют, как элементы должны быть пройдены. Чтобы получить эффективные результаты, оптимизатор запросов должен бесплатно использовать индексы и другие структуры.
Вывод
XPath - это язык запросов, используемый для прохождения элементов, атрибутов, текста через документ XML. XPath широко используется для поиска определенных элементов или атрибутов с соответствующими шаблонами. Когда запрос определен, эти данные XML могут быть представлены в виде дерева. Иерархическое представление данных XML называется деревом. Вершина дерева является корневым узлом. В дереве каждый атрибут, элементы, текст, комментарии, строка и инструкция обработки соответствуют одному узлу. Отношения между узлами могут быть представлены деревом.
Рекомендуемые статьи
Это руководство Что такое XPath? Здесь мы обсудим выражения, список, примеры и преимущества Xpath. Вы также можете просмотреть другие наши статьи, чтобы узнать больше-
- Что такое XPath в Selenium?
- Что такое XML?
- Новый путь карьеры
- Карьерный путь информационной безопасности
- Примеры встроенных функций Python