

Введение в архитектуру Hadoop
Hadoop Architecture - это платформа с открытым исходным кодом, которая помогает легко обрабатывать большие наборы данных. Это помогает в создании приложений, которые обрабатывают огромные данные с большей скоростью. Он использует концепции распределенных вычислений, когда данные распределяются по разным узлам кластера. Приложения, созданные с использованием Hadoop, используют обычные компьютеры. Эти компьютеры легко доступны на рынке по низким ценам. Этот результат обеспечивает большую вычислительную мощность при низких затратах. Все данные, присутствующие в Hadoop, хранятся в HDFS, а не в локальной файловой системе. HDFS - это распределенная файловая система Hadoop. Эта модель основана на локальности данных, где вычислительная логика отправляется на узлы, присутствующие в кластере, который содержит данные. Эта логика - не что иное, как логика, которая составляет программу.
Hadoop Architecture
Основная идея этой архитектуры заключается в том, что полное хранение и обработка выполняется в два этапа и двумя способами. Первым этапом является обработка, выполняемая программой Map Reduce, а вторым этапом является сохранение данных, выполненных в HDFS. Он имеет архитектуру master-slave для хранения и обработки данных. Главный узел для хранения данных в Hadoop - это узел имени. Существует также главный узел, который выполняет мониторинг и параллельно обрабатывает данные, используя Hadoop Map Reduce. Подчиненные устройства - это другие машины в кластере Hadoop, которые помогают хранить данные, а также выполняют сложные вычисления. Каждому подчиненному узлу был присвоен трекер задач, а у узла данных есть трекер заданий, который помогает запускать процессы и эффективно их синхронизировать. Этот тип системы может быть установлен как в облаке, так и локально. Узел имени является единственной точкой отказа, когда он не работает в режиме высокой доступности. В архитектуре Hadoop также предусмотрено обеспечение резервного узла Name для защиты системы от сбоев. Ранее существовали вторичные узлы имен, которые выполняли роль резервной копии, когда основной узел имен был недоступен.
FSimage и редактировать журнал
FSimage и Edit Log обеспечивают постоянство метаданных файловой системы в соответствии со всей информацией, а узел имен хранит метаданные в двух файлах. Эти файлы - FSimage и журнал редактирования. Задача FSimage - сохранить полный снимок файловой системы в данный момент времени. Об изменениях, которые постоянно вносятся в систему, необходимо вести учет. Эти дополнительные изменения, такие как переименование или добавление деталей в файл, сохраняются в журнале редактирования. Инфраструктура предоставляет лучшую возможность вместо того, чтобы каждый раз создавать новый FSimage, лучшую возможность сохранять данные во время создания нового файла для FSimage. FSimage создает новый снимок каждый раз, когда вносятся изменения. Если узел Name выходит из строя, он может восстановить свое предыдущее состояние. Вторичный узел имени также может обновлять свою копию всякий раз, когда происходят изменения в FSimage и редактировать журналы. Таким образом, это гарантирует, что, хотя узел имени не работает, при наличии вторичного узла имени не будет никакой потери данных. Имя узла не требует перезагрузки этих изображений на вторичном узле имени.
Репликация данных
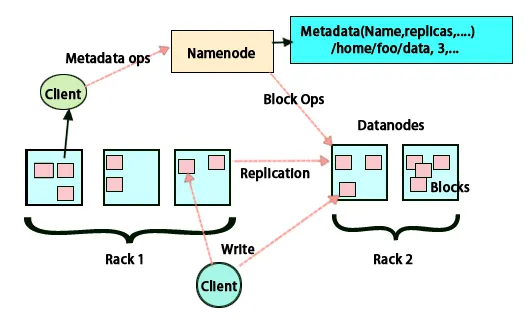
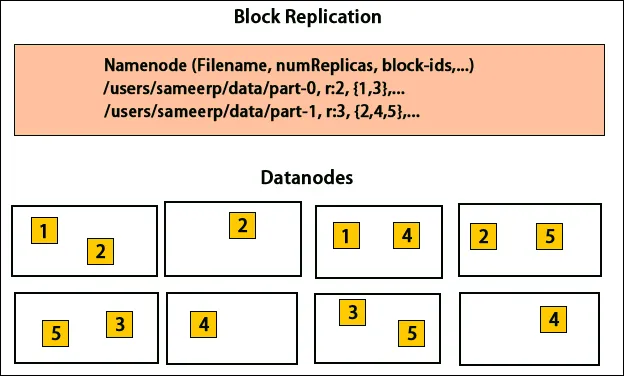
HDFS предназначена для быстрой обработки данных и предоставления надежных данных. Он хранит данные на компьютерах и в больших кластерах. Все файлы хранятся в виде серии блоков. Эти блоки реплицированы для отказоустойчивости. Размер блока и коэффициент репликации могут быть определены пользователями и настроены в соответствии с требованиями пользователя. По умолчанию коэффициент репликации равен 3. Коэффициент репликации может быть указан во время создания файла и может быть изменен позже. Все решения относительно этих реплик принимаются узлом имени. Узел имени продолжает отправлять тактовые импульсы и регулярно блокировать отчет для всех узлов данных в кластере. Получение пульса подразумевает, что узел данных работает правильно. Отчет о блоках определяет список всех блоков, присутствующих в узле данных.
Размещение реплик
Размещение реплик - это очень важная задача в Hadoop для надежности и производительности. Все разные блоки данных размещены на разных стойках. Внедрение размещения реплик может быть выполнено в соответствии с надежностью, доступностью и использованием полосы пропускания сети. Кластер компьютеров можно распределить по разным стойкам. На одной стойке можно разместить не более двух узлов. Третья реплика должна быть размещена на другой стойке для обеспечения большей надежности данных. Два узла в стойке обмениваются данными через разные коммутаторы. Узел имени имеет идентификатор стойки для каждого узла данных. Но размещение всех узлов на разных стойках предотвращает потерю каких-либо данных и позволяет использовать пропускную способность нескольких стоек. Это также сокращает трафик между стойками и повышает производительность. Кроме того, вероятность отказа стойки значительно меньше, чем вероятность отказа узла. Это уменьшает совокупную пропускную способность сети при чтении данных из двух уникальных стоек, а не из трех.
Уменьшение карты
Map Reduce используется для обработки данных, которые хранятся в HDFS. Он записывает распределенные данные в распределенные приложения, что обеспечивает эффективную обработку больших объемов данных. Они обрабатывают на больших кластерах и требуют товара, который является надежным и отказоустойчивым. Ядром Map-Reduce могут быть три операции, такие как отображение, сбор пар и перетасовка результирующих данных.
Вывод - архитектура Hadoop
Hadoop - это платформа с открытым исходным кодом, которая помогает в отказоустойчивой системе. Он может хранить большие объемы данных и помогает хранить надежные данные. Две части хранения данных в HDFS и их обработки с помощью map-Reduce помогают работать правильно и эффективно. Он имеет архитектуру, которая помогает в управлении всеми блоками данных, а также имеет самую последнюю копию, сохраняя ее в FSimage и редактируя журналы. Фактор репликации также помогает иметь копии данных и получать их обратно в случае сбоя. HDFS также перемещает удаленные файлы в каталог корзины для оптимального использования пространства.
Рекомендуемые статьи
Это было руководство по архитектуре Hadoop. Здесь мы обсудили архитектуру, сокращение карты, размещение реплик, репликацию данных. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Стать разработчиком Hadoop
- Введение в Android
- Что такое таблица? | Обзор
- Что такое MapReduce в Hadoop?