

Различия между Sqoop и Flume
Sqoop является продуктом программного обеспечения Apache. Sqoop извлекает полезную информацию из Hadoop и затем передает во внешние хранилища данных. С помощью Sqoop мы можем импортировать данные из РСУБД или мэйнфрейма в HDFS. Flume также из программного обеспечения Apache. Он собирает и перемещает сгенерированные рекурсивные данные. Apache Flume не только ограничивается агрегацией данных журнала, но и настраивает источники данных, поэтому Flume можно использовать для транспортировки огромных объемов данных. Лучший способ сбора, агрегирования и перемещения больших объемов данных между распределенной файловой системой Hadoop и RDBMS - это использование таких инструментов, как Sqoop или Flume.
Давайте обсудим эти два наиболее часто используемых инструмента для вышеуказанной цели.
Что такое Sqoop
Чтобы использовать Sqoop, пользователь должен указать инструмент, который пользователь хочет использовать, и аргументы, управляющие конкретным инструментом. Затем вы также можете экспортировать данные обратно в RDBMS, используя Sqoop. Функциональность экспорта Sqoop используется для извлечения полезной информации из Hadoop и экспорта ее во внешние структурированные хранилища данных. Он работает с различными базами данных, такими как Teradata, MySQL, Oracle, HSQLDB.
- Sqoop Architecture: -
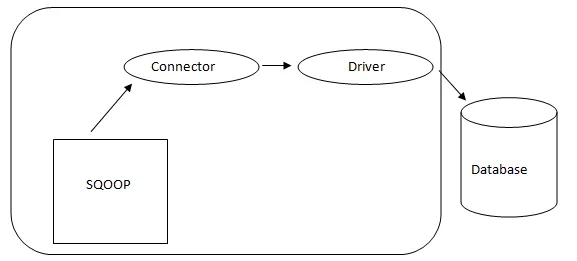
Архитектура Sqoop
Соединитель в Sqoop является плагином для определенного источника базы данных, поэтому важно, чтобы он был частью создания Sqoop. Несмотря на то, что драйверы являются частями базы данных и распространяются различными поставщиками баз данных, сам Sqoop поставляется в комплекте с различными типами соединителей, используемых для распространенной базы данных и системы хранения информации. Таким образом, Sqoop поставляется с различными разъемами из коробки. Sqoop предоставляет подключаемый компонент для идеальной сети и внешней системы. API Sqoop предоставляет полезную структуру для сборки новых коннекторов, и поэтому любые коннекторы базы данных можно перенести в установку Sqoop, чтобы обеспечить подключение к различным системам данных.
Что такое Флюм
Apache Flume не только ограничивается агрегацией данных журнала, но и настраивает источники данных, поэтому Flume можно использовать для транспортировки огромных объемов данных, включая, помимо прочего, сообщения электронной почты, данные, созданные в социальных сетях, данные сетевого трафика и практически любые данные. источник данных возможен.
Архитектура Flume: - Архитектура Flume основана на многоядерных концепциях:
- Flume Event - оно представляется как единица потока данных, которая имеет полезную нагрузку байта и набор строк с необязательными заголовками строк. Flume считает событие просто общим байтом.
- Flume Agent - это процесс JVM, в котором размещаются такие компоненты, как каналы, приемник и источники. Он может принимать, хранить и пересылать события из внешнего источника на следующий уровень.
- Поток потока - это момент времени, когда генерируется событие.
- Flume Client - это интерфейс, на котором клиент работает в исходной точке события и доставляет его агенту Flume.
- Источник - источник, который потребляет события, имеющие определенный формат, и доставляет его через определенный механизм.
- Канал - это пассивное хранилище, где события проводятся до тех пор, пока приемник не удалит его для дальнейшей транспортировки.
- Sink - удаляет событие из канала и помещает его во внешний репозиторий, такой как HDFS. В настоящее время он поддерживает создание текстовых и последовательных файлов и поддерживает сжатие обоих типов файлов.
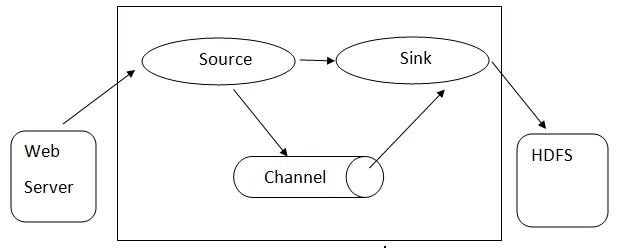
Архитектура Flume
Сравнение лицом к лицу между Sqoop и Flume (Инфографика)
Ниже приведено 7 лучших сравнений между Sqoop и Flume.

Ключевые различия между Sqoop и Flume
Теперь мы знаем, что есть много различий между Sqoop и Flume, вот самые важные различия между ними, приведенные ниже:
1. Sqoop предназначен для обмена массовой информацией между Hadoop и реляционной базой данных.
Принимая во внимание, что Flume используется для сбора данных из разных источников, которые генерируют данные, относящиеся к конкретному случаю использования, а затем переносят этот большой объем данных из распределенных ресурсов в один централизованный репозиторий.
2. Sqoop также включает в себя набор команд, который позволяет вам проверять базу данных, с которой вы работаете. Таким образом, мы можем рассматривать Sqoop как набор связанных инструментов.
При сборе даты Flume масштабирует данные по горизонтали, и можно использовать несколько агентов Flume для сбора даты и их агрегирования. После этого журналы данных перемещаются в централизованное хранилище данных, т.е. в распределенную файловую систему Hadoop (HDFS).
3. Ключевым фактором использования Flume является то, что данные должны генерироваться непрерывно и в потоковом режиме. Точно так же Sqoop лучше всего подходит в ситуациях, когда ваши данные хранятся в таких системах баз данных, как MySQL, Oracle, Teradata, PostgreSQL.
Sqoop vs Flume (Сравнительная таблица)
| Основа для сравнения | SQOOP | акведук |
|
Основная природа | Sqoop хорошо работает с любыми СУБД, имеющими JDBC (Java Database Connectivity), такими как Oracle, MySQL, Teradata и т. Д. | Flume хорошо работает для потокового источника данных, который постоянно генерирует такие, как журналы, JMS, каталог, отчеты о сбоях и т. Д. |
| Поток данных | Sqoop специально используется для параллельной передачи данных. По этой причине вывод может быть в нескольких файлах | Flume используется для сбора и агрегирования данных из-за своей распределенной природы. |
| Управляемые события | Sqoop не управляется событиями. | Flume полностью управляется событиями. |
| Архитектура | Sqoop следует архитектуре на основе соединителей, что означает, что соединители знают, как подключаться к другому источнику данных. | Flume следует архитектуре на основе агентов, где написанный в ней код известен как агент, отвечающий за выборку данных. |
| Где использовать | В основном используется для более быстрого копирования данных, а затем используется для получения аналитических результатов. | Обычно используется для получения данных, когда компании хотят анализировать шаблоны, коренные причины или анализ настроений с использованием журналов и социальных сетей. |
| Производительность | Это уменьшает чрезмерные нагрузки при хранении и обработке, передавая их другим системам, и обеспечивает высокую производительность. | Flume отличается отказоустойчивостью, надежностью и надежным механизмом восстановления после сбоя и восстановления. |
| История выпуска | Первая версия Apache Sqoop была выпущена в марте 2012 года. Текущий стабильный выпуск - 1.4.7. | Первая стабильная версия Apache Flume 1.2.0 была выпущена в июне 2012 года. Текущий стабильный выпуск - Apache Flume Version 1.8.0. |
Вывод - Sqoop против Flume
Как вы узнали выше из Sqoop и Flume, в первую очередь используются два инструмента Data Ingestion - мир больших данных. Если вам нужно вставить данные текстового журнала в Hadoop / HDFS, то Flume - правильный выбор для этого. Если ваши данные не генерируются регулярно, Flume все равно будет работать, но это будет излишним для этой ситуации. Точно так же Sqoop не подходит для обработки данных на основе событий.
Рекомендуемые статьи
Это было руководство по различиям между Sqoop и Flume, их значению, сравнению лицом к лицу, ключевым различиям, сравнительной таблице и заключению. Эта статья состоит из всех полезных различий между Sqoop и Flume. Вы также можете посмотреть следующие статьи, чтобы узнать больше
- Hadoop vs Teradata - полезные различия для изучения
- 5 самых важных различий между Apache Kafka и Flume
- Большие данные против Apache Hadoop - сравнение 4-х лучших, которые вы должны изучить
- 5 самых важных различий между Apache Kafka и Flume
- Важный текстовый майнинг против обработки естественного языка - 5 лучших сравнений