

Введение в дерево решений в Data Mining
В современном мире «больших данных» термин «интеллектуальный анализ данных» означает, что нам необходимо изучить большие наборы данных и выполнить «интеллектуальный анализ» данных и выявить важный смысл или суть того, что данные хотят сказать. Очень похожая ситуация - это добыча угля, когда для добычи угля, закопанного глубоко под землей, требуются разные инструменты. Из инструментов в Data mining «Decision Tree» является одним из них. Таким образом, интеллектуальный анализ данных сам по себе является обширной областью, в которой в следующих нескольких параграфах мы углубимся в «инструмент» дерева решений в Data Mining.
Алгоритм дерева решений в Data Mining
Дерево решений - это контролируемый подход к обучению, в котором мы обучаем представленные данные, уже зная, что на самом деле является целевой переменной. Как следует из названия, этот алгоритм имеет древовидную структуру. Давайте сначала рассмотрим теоретический аспект дерева решений, а затем рассмотрим его в графическом подходе. В Дереве решений алгоритм разбивает набор данных на подмножества на основе наиболее важного или значимого атрибута. Наиболее значимый атрибут обозначен в корневом узле, и именно здесь происходит разделение всего набора данных, присутствующего в корневом узле. Такое разделение известно как узлы принятия решений. Если разделение больше невозможно, этот узел называется конечным узлом.
Чтобы остановить алгоритм, чтобы достигнуть подавляющей стадии, используется критерий остановки. Одним из критериев остановки является минимальное количество наблюдений в узле до разделения. Применяя дерево решений для разделения набора данных, нужно быть осторожным, так как многие узлы могут просто содержать зашумленные данные. Чтобы решить проблемы с выбросами или шумом данных, мы используем методы, известные как сокращение данных. Сокращение данных - это не что иное, как алгоритм для классификации данных из подмножества, что затрудняет изучение из данной модели.
Алгоритм дерева решений был выпущен как ID3 (итеративный дихотомайзер) исследователем машины Дж. Россом Куинланом. Позже C4.5 был выпущен как преемник ID3. И ID3, и C4.5 - это жадный подход. Теперь давайте посмотрим на блок-схему алгоритма дерева решений.
Для понимания псевдокода мы бы взяли «n» точек данных, каждая из которых имеет атрибуты «k». Ниже приведена блок-схема с учетом «получения информации» как условия разделения.
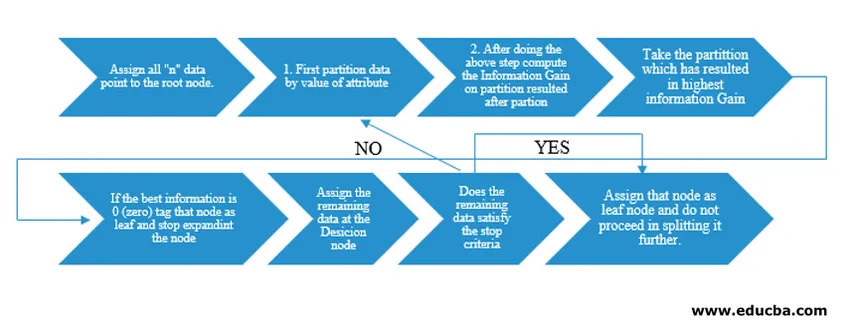
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Вместо получения информации (IG) мы также можем использовать индекс Джини в качестве критерия разделения. Чтобы понять разницу между этими двумя критериями в терминах непрофессионала, мы можем рассматривать этот выигрыш в информации как разницу энтропии до разделения и после разделения (разделение на основе всех доступных функций).
Энтропия подобна случайности, и мы бы достигли точки после разделения, чтобы иметь состояние наименьшей случайности. Следовательно, информационный прирост должен быть максимальным для функции, которую мы хотим разделить. Иначе, если мы хотим выбрать деление на основе индекса Джини, мы найдем индекс Джини для различных атрибутов и, используя его, находим взвешенный индекс Джини для другого разделения и используем индекс с более высоким индексом Джини для разделения набора данных.
Важные условия принятия решений в Data Mining
Ниже приведены некоторые важные термины дерева решений в области интеллектуального анализа данных:
- Корневой узел: это первый узел, где происходит разделение.
- Конечный узел: это узел, после которого больше нет ветвления.
- Узел принятия решения. Узел, образованный после разделения данных из предыдущего узла, называется узлом принятия решения.
- Ветвь: подраздел дерева, содержащий информацию о последствиях разделения в узле принятия решения.
- Сокращение: когда происходит удаление подузлов узла принятия решения для обслуживания выбросов или шумных данных, называется сокращением. Также считается противоположностью расщепления.
Применение дерева решений в Data Mining
Дерево решений имеет вид архитектуры потоковой диаграммы, встроенной в тип алгоритма. По сути, он имеет вид паттерна «Если X, то Y еще Z» во время разделения. Этот тип паттерна используется для понимания человеческой интуиции в программной области. Следовательно, можно широко использовать это в различных проблемах категоризации.
- Этот алгоритм может широко использоваться в области, где целевая функция связана с проведенным анализом.
- Когда есть множество доступных курсов действий.
- Анализ выбросов.
- Понимание значительного набора функций для всего набора данных и «мое» несколько функций из списка сотен функций в больших данных.
- Выбор лучшего рейса для поездки в пункт назначения.
- Процесс принятия решений на основе различных обстоятельств.
- Анализ оттока.
- Анализ настроений.
Преимущества дерева решений
Вот некоторые преимущества дерева решений, объясненного ниже:
- Простота понимания: то, как дерево решений изображается в графических формах, облегчает понимание для человека с неаналитическим фоном. Особенно для людей в руководстве, которые хотят взглянуть на то, какие особенности важны, просто взглянув на дерево решений, можно высказать свою гипотезу.
- Исследование данных. Как уже говорилось, получение значимых переменных является основной функциональностью дерева решений, и с помощью того же самого можно во время исследования данных определить, какая переменная потребует особого внимания на этапе анализа данных и моделирования.
- На этапе подготовки данных вмешательство человека очень незначительное, и в результате этого времени, затрачиваемого на данные, очистка уменьшается.
- Дерево решений способно обрабатывать как категориальные, так и числовые переменные, а также обслуживать многоклассовые проблемы классификации.
- Как часть предположения, деревья решений не имеют предположения о пространственном распределении и структуре классификатора.
Вывод
Наконец, чтобы сделать вывод, деревья решений привносят совершенно другой класс нелинейности и обслуживают решение проблем нелинейности. Этот алгоритм - лучший выбор для имитации мышления людей на уровне принятия решений и представления его в математически-графической форме. Он использует нисходящий подход при определении результатов по новым невидимым данным и следует принципу «разделяй и властвуй».
Рекомендуемые статьи
Это руководство по дереву решений в Data Mining. Здесь мы обсудим алгоритм, важность и применение дерева решений в интеллектуальном анализе данных, а также его преимущества. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Машинное обучение данным науки
- Типы методов анализа данных
- Дерево решений в R
- Что такое интеллектуальный анализ данных?
- Руководство по различным методологиям анализа данных