

Что такое Кафка?
Чтобы понять Кафку, лучше понять, что такое технология «потоковой обработки». «Потоковая обработка - это технология, с помощью которой пользователь может запрашивать непрерывный поток данных в микро-таймфрейме для лучшего понимания ответственных условий.
Сценарий в реальном времени - представьте, отправляет ли ваш датчик температуры данные, которые вы можете запросить, и получите предупреждение после получения точки замерзания. Этот запрос данных может быть сделан в микросекундах.
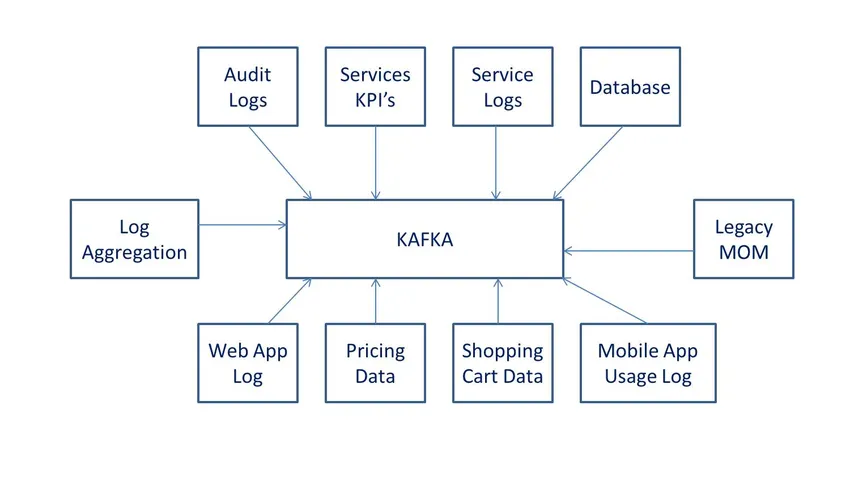
Определения
согласно Wiki, это программное обеспечение для обработки данных с открытым исходным кодом. Он был разработан LinkedIn, а затем передан в дар программному обеспечению Apache.
Понимание Кафки
Его рост растет в геометрической прогрессии. Давайте посмотрим некоторые факты и статистику, чтобы лучше подчеркнуть нашу мысль. Он пользуется первостепенным предпочтением более чем одной трети Fortune 500 по всему миру. Распределение делится между компаниями туристического бизнеса, телекоммуникационными гигантами, банками и несколькими другими. LinkedIn, Microsoft и Netflix обрабатывают сообщения с четырьмя запятыми в день с Kafka (почти равно 1 000 000 000 000).
Он используется для потоков данных в реальном времени, для сбора больших данных или для анализа в реальном времени (или обоих). Kafka используется с микросервисами в памяти для обеспечения долговечности и может использоваться для подачи событий в CEP (сложные системы потоковой передачи событий) и системы автоматизации в стиле IoT / IFTTT.
Как Кафка работает так легко?
На основе простоты было бы правильным способом определить производительность. Легко понять, как Kafka работает с такой легкостью, начиная с настройки и использования. Эта повышенная производительность в поведении посвящена его стабильности, обеспечению надежной долговечности и гибкой встроенной возможности публикации, подписки или обслуживания в очереди. Это очень важно иметь, если вам нужно иметь дело с N - номерами группы клиентов, если вам нужно продемонстрировать надежную репликацию на рынке, чтобы предоставить вашим клиентам согласованный подход (например, тематический раздел Kafka). Одним из важнейших действий Kafka, который отличает его от конкурентов, является его совместимость с системами с потоками данных - его обработка и позволяет этим системам объединять, преобразовывать и загружать другие хранилища для удобства работы. «Все вышеперечисленные факты были бы невозможны, если бы Кафка был медленным». Его исключительная производительность делает это возможным.
С дальнейшим дополнением к простоте работы Kafka нам нужно перейти на «OS Level». Давайте посмотрим, как все работает для Кафки на уровне ОС -
- Он использует ядра ОС для более быстрого перемещения данных и работает по принципу нулевого копирования.
- Он позволяет группировать записи данных в виде фрагментов, которые могут быть видны из файловой системы (так называемый журнал тем Kafka) для потребителей.
- Возможность пакетной обработки данных обеспечивает эффективное сжатие данных с уменьшением задержки ввода-вывода.
- Он имеет возможность масштабировать горизонтально с помощью шардинга. Это может разделить журнал заголовков на сотни разделов и тысяч. Это позволяет легко справляться с огромной рабочей нагрузкой.
Что вы можете сделать с Кафкой?
Если ваша компания регулярно использует огромные массивы данных, вам нужен Kafka. Существует длинный список компаний, использующих его.
- LinkedIn использует для отслеживания данных и оперативных показателей.
- Twitter, чтобы обеспечить инфраструктуру потоковой обработки.
Существует длинный список компаний от Uber до Spotify и Goldman Sachs до Cisco.
преимущества
- Высокая пропускная способность: он может легко обрабатывать большой объем данных, когда генерация на высокой скорости является исключительным преимуществом в пользу Kafka. Это приложение испытывает недостаток в огромном аппаратном обеспечении. Способность поддерживать пропускную способность сообщений с частотой тысяч сообщений в секунду.
- Низкая задержка : низкая задержка при обработке этого сообщения большого объема.
- Отказоустойчивость: эта функция очень полезна, она имеет встроенную возможность ограничения узлом, встроенным в кластер.
- Прочный: он очень долговечен в работе и поэтому многие MNC предпочитают использовать Kafka. Говоря о долговечности операций, сообщения не могут потеряться в долгосрочной перспективе.
Требуемые навыки
Для того, чтобы быть профессионалом Кафки, не существует особых требований. Но мы подчеркнули некоторые потоки и профессионалы -
- Разработчики, которые охотно хотят сделать карьеру в потоке больших данных и хотят ускорить карьеру там.
- Специалисты по тестированию имеют хорошие возможности в Кафке с точки зрения систем массового обслуживания и обмена сообщениями.
- Архитекторы - так как все нуждается в некоторой структуре, и эта структура может время от времени обновляться. Архитекторы больших данных считают Кафку хорошей инвестицией в карьеру.
- Менеджер проекта необходим, если вышеупомянутый профессионал существует для лучшего управления ресурсами. Таким образом, более высокие позиции также доступны для специалистов по управлению в области Кафка.
Зачем использовать Кафку?
В целях отслеживания данных и манипулирования ими в соответствии с потребностями бизнеса, Kafka предпочитают во всем мире. Это дает возможность потоковой передачи данных в режиме реального времени с аналитикой в реальном времени. Это быстро, масштабируемо, долговечно и разработано как отказоустойчивое. В Интернете есть несколько вариантов использования, в которых вы можете увидеть, почему JMS, RabbitMQ и AMQP даже не рассматриваются как работающие, так как необходимо управлять огромным объемом и быстродействием.
Он имеет высокую пропускную способность, надежную настройку с характеристиками репликации, что делает его предпочтительным выбором для работы с датчиками IoT.
Совместимость - это еще одна причина для ее использования, которая сделала ее приемлемой во всем мире Его можно легко настроить для работы с перечисленным ниже приложением. Это сочетание очень важно для многих компаний, чтобы развивать бизнес и выживать (так как это экономит время и деньги).
- акведук
- Spark Streaming
- HBase
- Искра для приема, обработки и анализа данных в режиме реального времени.
- Используется для кормления Hadoop BigData
Сфера
Это здорово по всему миру. Ну, мы не говорим, это скорее статистика. Давайте посмотрим -
Статистика заработной платы для профессионалов Kafka - PayScale
- Инженер-программист - $ 109 825
- Инженер данных - $ 109 580
- Разработчики - $ 81 182
- Старший инженер данных - $ 127 836
Вывод
В настоящее время Kafka стала стандартом де-факто, когда дело доходит до анализа данных в реальном времени с высочайшей точностью в микросекундах. Мы представили наши идеи с точки зрения данных и деталей в поддержку технологий Kafka. Есть несколько крупных компаний, которые ежедневно используют данные, для этого им нужны профессионалы, чтобы использовать эти огромные наборы данных. С Kafka можно быть уверенным вести свою карьеру в аналитике BigData
Рекомендуемые статьи
Это было руководство к тому, что такое Кафка. Здесь мы обсудили работу, масштаб, карьерный рост и преимущества Kafka. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Что такое Apache?
- Что такое большие данные и Hadoop?
- Что такое лазурь?
- Что такое технология больших данных?
- Кафка против Спарк | 5 главных отличий
- Обзор и основные области применения Kafka
- Кафка против Кинезис | 5 отличий от инфографики