

Введение в алгоритм BFS
Для эффективного доступа к данным и их управления они могут храниться и организовываться в специальном формате, известном как структура данных. Существует много структур данных, таких как стек, массив, связанный список, очереди, деревья, графики и т. Д. В линейных структурах данных, таких как стек, массив, связанный список и очередь, данные организованы в линейном порядке, тогда как в линейные структуры данных, такие как деревья и графики, данные организованы иерархически не в последовательности. График представляет собой нелинейную структуру данных, которая имеет узлы и ребра. Узлы в графе также могут называться вершинами с конечным числом, а ребра являются связующими линиями между любыми двумя узлами.
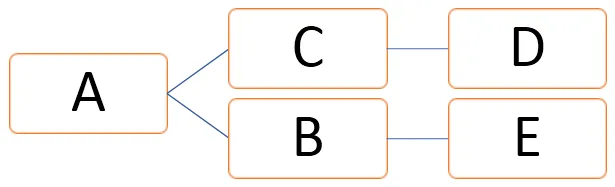
На приведенном выше графике вершины могут быть представлены как V = (A, B, C, D, E), а ребра могут быть определены как
E = (AB, AC, CD, BE)
Что такое алгоритм BFS?
Обычно существует два алгоритма, которые используются для обхода графа. Это алгоритмы BFS (поиск в ширину) и DFS (поиск в глубину). Обход графа - это посещение ровно один раз каждой вершины, узла и ребра в четко определенном порядке. Кроме того, очень важно отслеживать посещенные вершины, чтобы одна и та же вершина не проходила дважды. В алгоритме поиска Breath First поиск начинается с выбранного узла или узла-источника, а обход продолжается через узлы, напрямую связанные с узлом-источником. Проще говоря, в алгоритме BFS нужно сначала перемещать по горизонтали и пересекать текущий слой, после чего следует перейти к следующему слою.
Как работает алгоритм BFS?
Давайте возьмем пример приведенного ниже графика.
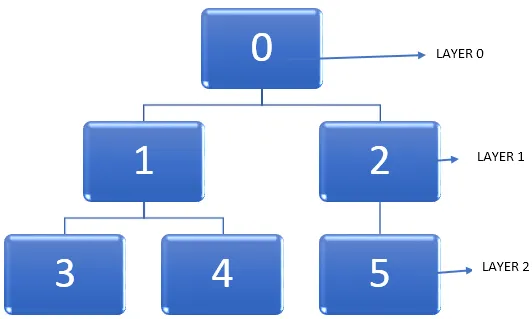
Важная задача под рукой - найти кратчайший путь в графе при обходе узлов. Когда мы проходим через граф, вершина переходит из неоткрытого состояния в обнаруженное состояние и, наконец, становится полностью обнаруженной. Следует отметить, что в какой-то момент можно застрять во время обхода графа, и узел можно посетить дважды. Таким образом, мы можем использовать метод маркировки узлов после того, как он изменяет состояние отсутствия обнаружения на полное обнаружение.
На изображении ниже мы видим, что узлы могут быть отмечены на графиках, поскольку они становятся полностью обнаруженными, отмечая их черным. Мы можем начать с исходного узла и по мере прохождения через каждый узел их можно пометить для идентификации.
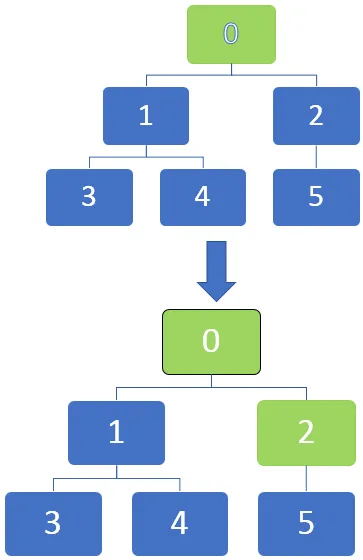
Обход начинается с вершины, а затем перемещается к исходящим ребрам. Когда ребро переходит в неоткрытую вершину, оно помечается как обнаруженное. Но когда ребро переходит в полностью обнаруженную или обнаруженную вершину, оно игнорируется.
Для ориентированного графа каждое ребро посещается один раз, а для неориентированного графа оно посещается дважды, т.е. один раз при посещении каждого узла. Используемый алгоритм определяется на основе того, как хранятся обнаруженные вершины. В алгоритме BFS очередь используется там, где сначала обнаруживается самая старая вершина, а затем она распространяется по слоям от начальной вершины.
Шаги выполняются для алгоритма BFS
Следующие шаги выполняются для алгоритма BFS.
- В данном графе давайте начнем с вершины, то есть на приведенной выше диаграмме это узел 0. Уровень, на котором присутствует эта вершина, можно обозначить как слой 0.
- Следующий шаг - найти все остальные вершины, которые смежны с начальной вершиной, т. Е. Узлом 0, или сразу доступны из нее. Затем мы можем пометить эти смежные вершины для присутствия на уровне 1.
- В одну и ту же вершину можно попасть благодаря петле в графе. Итак, мы должны путешествовать только по тем вершинам, которые должны присутствовать в одном слое.
- Затем отмечается родительская вершина текущей вершины, в которой мы находимся. То же самое должно быть выполнено для всех вершин на уровне 1.
- Затем следующий шаг - найти все эти вершины, которые находятся на одном ребре от всех вершин на уровне 1. Этот новый набор вершин будет на уровне 2.
- Вышеупомянутый процесс повторяется, пока все узлы не пройдены.
Пример:
Давайте возьмем пример приведенного ниже графика и поймем, как работает алгоритм BFS. Как правило, в алгоритме BFS очередь используется для постановки в очередь узлов при обходе узлов.
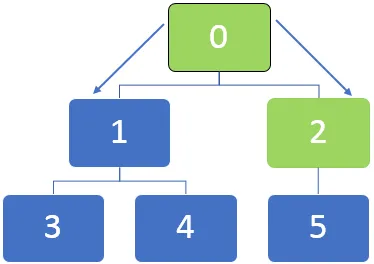
На приведенном выше графике сначала необходимо посетить узел 0, и этот узел ставится в очередь в следующей очереди:

После посещения узла 0 соседние узлы 0, 1 и 2 ставятся в очередь. Очередь может быть представлена следующим образом: 
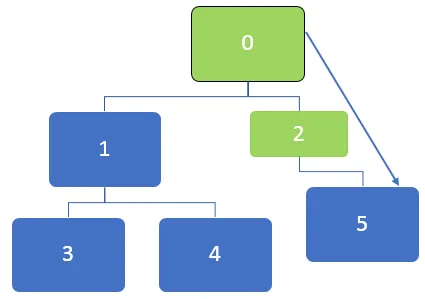
Затем первый узел в очереди, который равен 2, будет посещен. После посещения узла 2 очередь может быть представлена следующим образом:

После посещения узла 2, 5 будет поставлен в очередь, и, поскольку нет никаких не посещенных соседних узлов для узла 5, все же, хотя 5 находится в очереди, но он не будет посещен дважды.
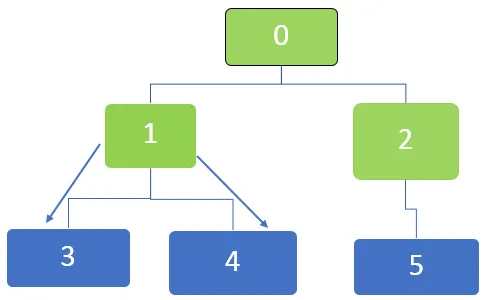
Далее, первый узел в очереди - 1, который будет посещен. Соседние узлы 3 и 4 поставлены в очередь. Очередь представлена ниже

Затем, первый узел в очереди равен 5, и для этого узла больше нет не посещенных соседних узлов. То же самое относится к узлам 3 и 4, для которых также нет больше не посещенных соседних узлов.
Таким образом, все узлы пройдены и, наконец, очередь становится пустой.

Вывод
Алгоритм поиска по ширине обладает некоторыми преимуществами, чтобы рекомендовать его. Одним из многих применений алгоритма BFS является вычисление кратчайшего пути. Кроме того, он используется в сети для поиска соседних узлов и может быть найден на сайтах социальных сетей, сетевого вещания и сбора мусора. Пользователи должны понимать требования и структуру данных, чтобы использовать их для повышения производительности.
Рекомендуемые статьи
Это было руководство к алгоритму BFS. Здесь мы обсуждаем концепцию, работу, шаги и пример производительности в алгоритме BFS. Вы также можете просмотреть наши другие Предлагаемые статьи, чтобы узнать больше -
- Что такое жадный алгоритм?
- Алгоритм трассировки лучей
- Алгоритм цифровой подписи
- Что такое Java Hibernate?
- Криптография с цифровой подписью
- BFS VS DFS | Топ 6 отличий с инфографикой