
Обзор нейросетевых алгоритмов
- Давайте сначала узнаем, что означает нейронная сеть? Нейронные сети вдохновлены биологическими нейронными сетями в мозге или, можно сказать, нервной системой. Это вызвало много волнений, и исследования в этой области машинного обучения в промышленности все еще продолжаются.
- Основной вычислительной единицей нейронной сети является нейрон или узел. Он получает значения от других нейронов и вычисляет результат. Каждый узел / нейрон связан с весом (w). Этот вес дан согласно относительной важности этого конкретного нейрона или узла.
- Итак, если мы возьмем f в качестве функции узла, то функция узла f предоставит вывод, как показано ниже:
Выход нейрона (Y) = f (w1.X1 + w2.X2 + b)
- Где w1 и w2 - вес, X1 и X2 - числовые входы, тогда как b - смещение.
- Вышеупомянутая функция f является нелинейной функцией, также называемой функцией активации. Его основная цель состоит в том, чтобы ввести нелинейность, поскольку почти все данные реального мира являются нелинейными, и мы хотим, чтобы нейроны изучали эти представления.
Различные алгоритмы нейронной сети
Давайте теперь рассмотрим четыре различных алгоритма нейронной сети.
1. Градиентный спуск
Это один из самых популярных алгоритмов оптимизации в области машинного обучения. Используется при обучении модели машинного обучения. Проще говоря, он в основном используется для нахождения значений коэффициентов, которые просто максимально уменьшают функцию стоимости. Прежде всего, мы начинаем с определения значений некоторых параметров, а затем, используя исчисление, начинаем итеративно корректировать значения так, чтобы потерянная функция уменьшается.
Теперь давайте перейдем к части, что такое градиент? Таким образом, градиент означает, что выход любой функции изменится, если мы немного уменьшим вход, или, другими словами, мы можем вызвать его на склоне. Если наклон крутой, модель будет учиться быстрее, аналогично, модель прекращает обучение, когда наклон равен нулю. Это потому, что это алгоритм минимизации, который минимизирует данный алгоритм.
Ниже приведена формула для нахождения следующей позиции в случае градиентного спуска.
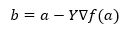
Где b - следующая позиция
а - текущая позиция, гамма - функция ожидания.
Итак, как вы можете видеть, градиентный спуск является очень надежной техникой, но есть много областей, где градиентный спуск не работает должным образом. Ниже приведены некоторые из них:
- Если алгоритм не выполняется должным образом, мы можем столкнуться с чем-то вроде проблемы исчезновения градиента. Это происходит, когда градиент слишком мал или слишком велик.
- Проблемы возникают, когда расположение данных создает невыпуклую задачу оптимизации. Градиент прилично работает только с задачами, которые являются выпуклой оптимизированной задачей.
- Одним из очень важных факторов, которые необходимо учитывать при применении этого алгоритма, являются ресурсы. Если для приложения выделено меньше памяти, следует избегать алгоритма градиентного спуска.
2. Метод Ньютона
Это алгоритм оптимизации второго порядка. Он называется вторым порядком, потому что в нем используется матрица Гессе. Таким образом, матрица Гессе является не чем иным, как матрицей квадрата частных производных второго порядка скалярной функции. В алгоритме оптимизации метода Ньютона она применяется к первой производной двойной дифференцируемой функции f, чтобы она могла найти корни / стационарные пункты. Давайте теперь перейдем к шагам, необходимым для оптимизации методом Ньютона.
Сначала оценивается индекс потерь. Затем он проверяет, является ли критерий остановки истинным или ложным. Если false, то он вычисляет направление обучения Ньютона и скорость обучения, а затем улучшает параметры или веса нейрона, и снова тот же цикл продолжается. Итак, теперь вы можете сказать, что требуется меньше шагов по сравнению с градиентным спуском, чтобы получить минимум значение функции. Хотя он требует меньше шагов по сравнению с алгоритмом градиентного спуска, он все еще не используется широко, так как точное вычисление гессиана и его обратного вычисления вычислительно очень дорого.
3. Сопряженный градиент
Это метод, который можно рассматривать как нечто среднее между градиентным спуском и методом Ньютона. Основное отличие состоит в том, что он ускоряет медленную сходимость, которую мы обычно связываем с градиентным спуском. Другим важным фактом является то, что его можно использовать как для линейных, так и для нелинейных систем, и это итерационный алгоритм.
Он был разработан Магнусом Хестенесом и Эдуардом Штифелем. Как уже упоминалось выше, он обеспечивает более быструю сходимость, чем градиентный спуск. Причина, по которой он может это сделать, заключается в том, что в алгоритме сопряженного градиента поиск выполняется вместе с сопряженными направлениями, благодаря чему он сходится быстрее, чем алгоритмы градиентного спуска. Важно отметить, что γ называется сопряженным параметром.
Направление тренировки периодически сбрасывается на отрицательное значение градиента. Этот метод более эффективен, чем градиентный спуск, при обучении нейронной сети, поскольку для него не требуется матрица Гессе, которая увеличивает вычислительную нагрузку, и он также сходится быстрее, чем градиентный спуск. Уместно использовать в крупных нейронных сетях.
4. Квазиньютоновский метод
Это альтернативный подход к методу Ньютона, так как теперь мы знаем, что метод Ньютона является вычислительно дорогим. Этот метод устраняет эти недостатки до такой степени, что вместо вычисления матрицы Гессиана и последующего прямого вычисления обратного, этот метод создает приближение к обратному гессиану на каждой итерации этого алгоритма.
Теперь это приближение вычисляется с использованием информации из первой производной функции потерь. Таким образом, мы можем сказать, что это, вероятно, наиболее подходящий метод для работы с большими сетями, поскольку он экономит время вычислений, а также он намного быстрее, чем метод градиентного спуска или сопряженного градиента.
Вывод
Прежде чем мы закончим эту статью, давайте сравним скорость вычислений и объем памяти для вышеупомянутых алгоритмов. В соответствии с требованиями к памяти, градиентный спуск требует наименьшего количества памяти, и это также самый медленный. В противоположность этому метод Ньютона требует большей вычислительной мощности. Таким образом, принимая во внимание все это, метод Квазиньютона является наиболее подходящим.
Рекомендуемые статьи
Это было руководство по алгоритмам нейронной сети. Здесь мы также обсудим обзор алгоритма нейронной сети вместе с четырьмя различными алгоритмами соответственно. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Машинное обучение против нейронной сети
- Механизм машинного обучения
- Нейронные сети против глубокого обучения
- Алгоритм кластеризации K-средних
- Руководство по классификации нейронных сетей