
Разница между HBase и Кассандрой
HBase - это база данных, которая использует распределенную файловую систему Hadoop для хранения. HBase является важной частью HDFS и работает поверх кластера Hadoop. HBase не является традиционной реляционной базой данных, она требует другого подхода к моделированию данных. Cassandra работает над моделью репликации данных, поэтому в случае недоступности какого-либо узла потери данных не будет. Cassandra - это распределенная база данных, которая означает, что клиент может получить доступ к данным из любого кластера и с любого узла.
1.1) Кассандра:
Это было начато Facebook, потому что это всегда на требовании приложения. Cassandra была запущена в 2005 году и стала доступна для общественности в 2008 году. Cassandra была разработана для постоянно работающих приложений, таких как социальные сети, такие как Facebook и Twitter.
Cassandra работает на архитектуре «всегда включен » и имеет модель узла Active-Active, поэтому нет SPoF (единой точки отказа). CQL (Cassandra Query Language) - это язык запросов Cassandra, но с синтаксисом, аналогичным SQL. Он поддерживает все основные ОС, такие как Linux, Unix, OSX и Windows.
Всегда включен:
Cassandra - это база данных с моделью распределения, и все узлы в кластере одинаковы. Данные реплицируются на настраиваемых узлах, поэтому в случае сбоя некоторых нет. узлов не приведет к потере данных.
(Всегда на модели)
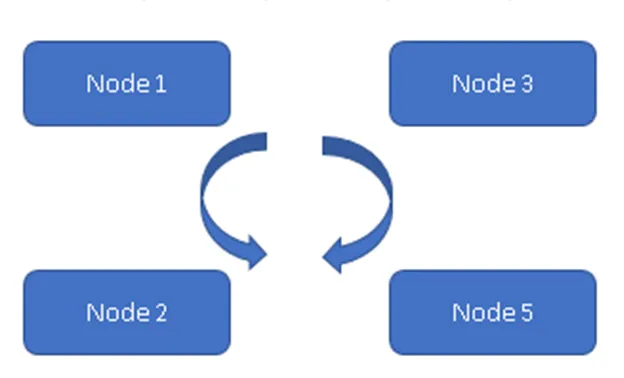
На рисунке 1 все четыре узла синхронизированы друг с другом и реплицируют данные в кластере. Все работают по Active-Active Model, поэтому в случае сбоя любого узла не будет потеря данных. Клиент может считывать данные с остальных доступных узлов / узлов.
1.2) HBase:
HBase - это база данных на основе NoSQL, предназначенная для обработки запросов в больших таблицах, содержащих миллиарды строк с миллионами столбцов и работающих в кластере обычного оборудования. Он предоставляет вам возможности запросов в реальном времени со скоростью « хранилища ключей / значений » .
HBase фактически основан / работает на четырехмерной модели данных.
- ID строки / ключ строки
- Колонна Семейная.
- Пары ключ-значение.
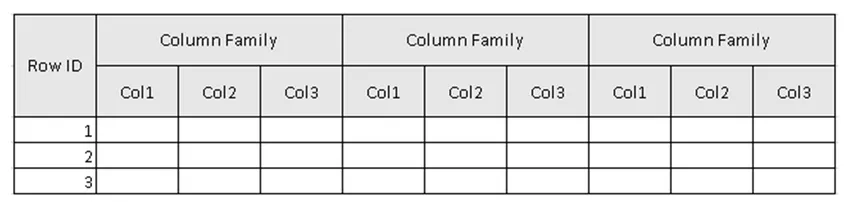
(Рисунок 2, Пример схемы таблицы в HBase.)
На рисунке 2 таблица представляет собой коллекцию семейства столбцов, а семейство столбцов представляет собой коллекцию столбцов. Столбцы представляют собой набор пар ключ-значение
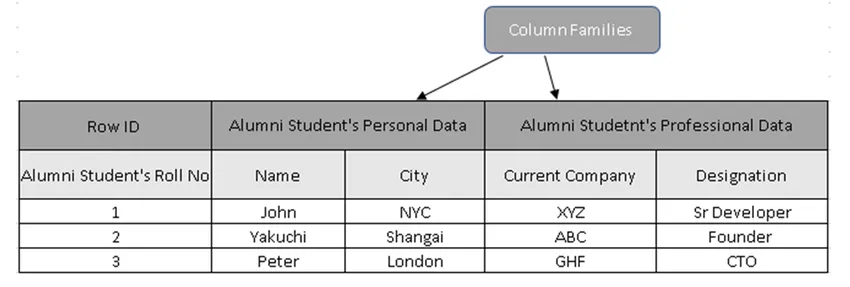
(Рисунок 3, Пример таблицы в HBase)
На рисунке 3 семейства столбцов представляют собой набор данных ученика выпускников, а идентификаторы строк (ключи строк) содержат номер студента.
Фактически, ключи строк содержат уникальное значение для данных семейства столбцов. Используя ключ строки, можно извлечь все детали, причины, по которым ориентированные на столбцы базы данных намного быстрее, чем традиционные базы данных.
Apache HBase может использоваться для произвольного доступа на чтение / запись, и он обеспечивает поддержку при сбоях. Он также поддерживает репликацию и работу над моделью распространения базы данных.
Личное сравнение HBase против Кассандры (Инфографика)
Ниже приводится топ-9 различий между HBase против Кассандры
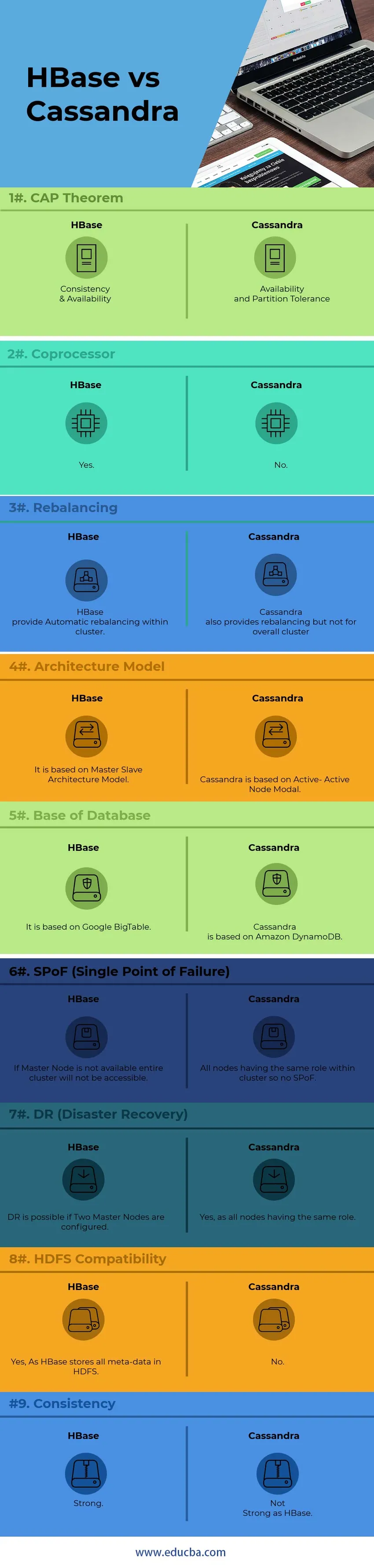 Ключевые отличия HBase от Cassandra
Ключевые отличия HBase от Cassandra
Ниже приведены списки точек, описывающих ключевые различия между HBase и Cassandra:
1) Для связи между внутренними узлами Cassandra использует протокол GOSSIP, в то время как HBase основан на Zookeeper. Сервисы GOSSIP Protocol интегрированы с Cassandra, с другой стороны Zookeeper - это совершенно отдельное приложение для распространения.
2) В архитектуре Cassandra все узлы работают как активный узел, в то время как HBase-архитектор следует модели Master-Slave Node. В модели Active-Active Node отсутствует SPoF (единичная точка отказа). В HBase, если мастер-узел выйдет из строя, весь кластер будет недоступен.
3) HBase поддерживает модель поиска бинарного дерева, в то время как Cassandra не поддерживает модель B-дерева. Без B-Tree вы не можете искать семейство столбцов пользователя для всех с годовщиной в апреле, в то время как вы можете искать всех, кто живет в Пекине с Юбилей в апреле.
4) HBase, поддержка языков сценариев C, C ++, Java, Python, Scala, а Cassandra также поддерживает JavaScript и Ruby.
5) HBase имеет одну функцию, называемую сопроцессором, в то время как Cassandra не имеет такой функции на данный момент. Сопроцессоры предоставляют библиотеку и среду выполнения для выполнения пользовательского кода на сервере региона HBase и в основных процессах.
6) HBase разработан для поддержки хранилища данных, в то время как Cassandra идеально подходит для постоянно работающих приложений, таких как веб-приложения и мобильные приложения.
7) Язык запросов HBase - это пользовательский язык, который необходимо изучать, в то время как Cassandra использует собственный разработанный CQL (Cassandra Query Language), который похож на язык SQL.
8) Управлять Cassandra намного проще, чем HBase. В Cassandra для каждого узла требуется запуск одного Java-процесса, в то время как для HBase требуются полностью работающие HDFS, несколько процессов HBase и система Zookeeper.
9) HBase завершает контрольные суммы и автоматически перебалансирует, в то время как Cassandra не поддерживает перебалансировку кластера в целом.
10) На основе « теоремы CAP» Кассандра работает над моделью AP, а HBase - моделью CP.
CAP Теорема
Эта теорема используется для распределенных систем. C означает согласованность, A означает доступность, а P - допуск раздела. Теорема CAP объяснена ниже:
C (Согласованность): Согласованность означает, что если кто-то записал значение в базу данных, другие могут немедленно прочитать то же значение.
A (Доступность) : Доступность означает, что если некоторые узлы недоступны в вашем кластере (узлы, которые были отключены / не живут в кластере из-за какой-либо проблемы), не повлияют на весь кластер, и распределенная система / база данных будут доступны для доступа к данным. Кластер будет доступен для всех видов задач.
P (Допуск раздела): Допуск раздела означает, что если один центр обработки данных не работает, это не должно влиять на данные, представленные на узлах, и все данные должны быть доступны в любое время. Значит, допуск раздела позволяет лучше реплицировать данные в другой центр обработки данных, а также в кластерной среде.
HBase vs Cassandra Сравнительная таблица
| Точки | HBase | Cassandra |
| CAP Теорема | Согласованность и доступность | Наличие и допуск раздела |
| сопроцессор | да | нет |
| восстановление равновесия | HBase обеспечивает автоматическую перебалансировку в кластере. | Кассандра также обеспечивает ребалансировку, но не для всего кластера |
| Архитектурная модель | Он основан на модели Master-Slave Architecture. | Кассандра основана на Active-Active Node Modal |
| База Базы Данных | Он основан на Google BigTable | Кассандра основана на Amazon DynamoDB |
| SPoF (единая точка отказа) | Если мастер-узел недоступен, весь кластер не будет доступен | Все узлы имеют одинаковую роль в кластере, поэтому нет SPoF |
| DR (аварийное восстановление) | DR возможен, если настроены два мастер-узла. | Да, так как все узлы имеют одинаковую роль |
| HDFS Совместимость | Да, поскольку HBase хранит все метаданные в HDFS | нет |
| консистенция | сильный | Не Сильный как HBase |
Вывод - HBase против Кассандры
Facebook и другая социальная сеть предпочли бы HBase (ранее оба использовали Cassandra, см. Пост в Facebook), поскольку другой сектор банковского домена ищет безопасность для каждой своей финансовой транзакции, поэтому они выбирают Cassandra вместо HBase.
Ключевые характеристики Cassandra включают в себя высокую доступность, минимальное администрирование и отсутствие SPoF (единой точки отказа). Другая сторона HBase хороша для более быстрого чтения и записи данных с линейной масштабируемостью.
Такие компании, как Verizon, Bloomberg, Bank of America и многие другие, используют HBase, а Cassandra используется крупными социальными сетями, такими как Twitter, Facebook и т. Д.
Мы не можем сделать вывод, какой из них лучший, у HBase и Cassandra есть свои преимущества и недостатки. Фактическую производительность баз данных HBase и Cassandra можно увидеть в производственной среде.
Рекомендуемые статьи:
Это было руководство по HBase vs Cassandra, их значению, сравнению лицом к лицу, ключевым различиям, сравнительной таблице и выводам. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Hadoop vs Apache Spark - Интересные вещи, которые нужно знать
- Как взломать интервью с разработчиком Hadoop?
- Топ 5 больших данных
- 5 проблем аналитики больших данных