

Что такое наивный байесовский алгоритм?
Наивный байесовский алгоритм - это методика, которая помогает строить классификаторы. Классификаторы - это модели, которые классифицируют проблемные экземпляры и присваивают им метки классов, которые представлены как векторы предикторов или значений признаков. Он основан на теореме Байеса. Он называется наивным байесовским, потому что предполагает, что значение объекта не зависит от другого объекта, т. Е. Изменение значения объекта не повлияет на значение другого объекта. Его также называют идиотом Байеса по той же причине. Этот алгоритм эффективно работает для больших наборов данных, поэтому лучше всего подходит для прогнозов в реальном времени.
Это помогает вычислить апостериорную вероятность P (c | x), используя априорную вероятность класса P (c), априорную вероятность предиктора P (x) и вероятность предиктора данного класса, также называемого вероятностью P (x | c) ).
Формула или уравнение для вычисления апостериорной вероятности:
- P (c | x) = (P (x | c) * P (c)) / P (x)
Как работает наивный байесовский алгоритм?
Давайте разберемся в работе наивного байесовского алгоритма на примере. Мы предполагаем набор данных о погоде и целевую переменную «Ходить по магазинам». Теперь мы будем классифицировать, пойдет ли девушка за покупками по погодным условиям.
Данный набор данных:
| Погода | Идти за покупками |
| Солнечный | нет |
| дождливый | да |
| Пасмурная погода | да |
| Солнечный | да |
| Пасмурная погода | да |
| дождливый | нет |
| Солнечный | да |
| Солнечный | да |
| дождливый | нет |
| дождливый | да |
| Пасмурная погода | да |
| дождливый | нет |
| Пасмурная погода | да |
| Солнечный | нет |
Следующие шаги будут выполнены:
Шаг 1: Составьте таблицы частот, используя наборы данных.
| Погода | да | нет |
| Солнечный | 3 | 2 |
| Пасмурная погода | 4 | 0 |
| дождливый | 2 | 3 |
| Общее количество | 9 | 5 |
Шаг 2: Составьте таблицу вероятности, рассчитав вероятности каждого погодного условия и отправившись за покупками.
| Погода | да | нет | Вероятность |
| Солнечный | 3 | 2 | 5/14 = 0, 36 |
| Пасмурная погода | 4 | 0 | 4/14 = 0, 29 |
| дождливый | 2 | 3 | 5/14 = 0, 36 |
| Общее количество | 9 | 5 | |
| Вероятность | 9/14 = 0, 64 | 5/14 = 0, 36 |
Шаг 3: Теперь нам нужно вычислить апостериорную вероятность, используя наивное уравнение Байеса для каждого класса.
Неполадка: девушка пойдет за покупками, если погода пасмурная. Это утверждение правильно?
Решение:
- P (Да | Облачно) = (P (Облачно | Да) * P (Да)) / P (Облачно)
- P (облачно | да) = 4/9 = 0, 44
- P (Да) = 9/14 = 0, 64
- P (облачно) = 4/14 = 0, 39
Теперь поместите все рассчитанные значения в приведенную выше формулу
- P (Да | Пасмурно) = (0, 44 * 0, 64) / 0, 39
- P (Да | Пасмурно) = 0, 722
Класс с наибольшей вероятностью будет результатом предсказания. С помощью одного и того же подхода можно прогнозировать вероятности разных классов.
Для чего используется наивный байесовский алгоритм?
1. Прогнозирование в реальном времени: Наивный байесовский алгоритм быстр и всегда готов к обучению, поэтому лучше всего подходит для прогнозирования в реальном времени.
2. Предсказание нескольких классов. Вероятность использования нескольких классов любой целевой переменной может быть предсказана с использованием наивного байесовского алгоритма.
3. Система рекомендаций: Наивный байесовский классификатор с помощью совместной фильтрации создает систему рекомендаций. Эта система использует методы интеллектуального анализа данных и машинного обучения, чтобы отфильтровать информацию, которую раньше не видели, а затем предсказать, оценит ли пользователь данный ресурс или нет.
4. Классификация текста / Анализ настроений / Фильтрация спама. Благодаря лучшей производительности при решении проблем с несколькими классами и правилу независимости алгоритм Байеса наивного алгоритма работает лучше или имеет более высокий уровень успеха в классификации текста, поэтому он используется в Анализе настроений и Спам-фильтрация.
Преимущества наивного байесовского алгоритма
- Легко реализовать.
- Быстро
- Если предположение о независимости выполнено, то оно работает более эффективно, чем другие алгоритмы.
- Это требует меньше тренировочных данных.
- Это очень масштабируемый.
- Это может делать вероятностные прогнозы.
- Может обрабатывать как непрерывные, так и дискретные данные.
- Нечувствителен к нерелевантным функциям.
- Это может легко работать с отсутствующими значениями.
- Легко обновлять при поступлении новых данных.
- Лучше всего подходит для задач классификации текста.
Недостатки наивного байесовского алгоритма
- Сильное предположение о том, что функции должны быть независимыми, что вряд ли верно в реальных приложениях.
- Дефицит данных.
- Возможны потери точности.
- Нулевая частота, т. Е. Если категория какой-либо категориальной переменной не видна в наборе обучающих данных, то модель присваивает этой категории нулевую вероятность, и тогда прогноз не может быть сделан.
Как построить базовую модель с использованием наивного байесовского алгоритма
Существует три типа наивных байесовских моделей: гауссовская, полиномиальная и бернуллиева. Давайте кратко обсудим каждый из них.
1. Гауссов: гауссовский наивный байесовский алгоритм предполагает, что непрерывные значения, соответствующие каждому признаку, распределены в соответствии с распределением Гаусса, также называемым нормальным распределением.
Предполагается, что вероятность или предшествующая вероятность предиктора данного класса является гауссовой, поэтому условная вероятность может быть рассчитана как:
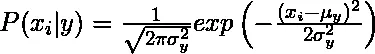
2. Полиномиальный: частоты возникновения определенных событий, представленных векторами признаков, генерируются с использованием полиномиального распределения. Эта модель широко используется для классификации документов.
3. Бернулли: в этой модели входные данные описываются признаками, которые являются независимыми двоичными переменными или логическими значениями. Это также широко используется в классификации документов, как Multinomial Naive Bayes.
Вы можете использовать любую из вышеперечисленных моделей в соответствии с требованиями для обработки и классификации набора данных.
Вы можете построить модель Гаусса, используя Python, понимая пример, приведенный ниже:
Код:
from sklearn.naive_bayes import GaussianNB
import numpy as np
a = np.array((-2, 7), (1, 2), (1, 5), (2, 3), (1, -1), (-2, 0), (-4, 0), (-2, 2), (3, 7), (1, 1), (-4, 1), (-3, 7)))
b = np.array((3, 3, 3, 3, 4, 3, 4, 3, 3, 3, 4, 4, 4))
md = GaussianNB()
md.fit (a, b)
pd = md.predict (((1, 2), (3, 4)))
print (pd)
Выход:
((3, 4))
Вывод
В этой статье мы подробно изучили концепции наивного байесовского алгоритма. В основном используется в текстовой классификации. Это легко реализовать и быстро выполнить. Его основным недостатком является то, что он требует, чтобы функции были независимыми, что не соответствует действительности в реальных приложениях.
Рекомендуемые статьи
Это было руководство к наивному алгоритму Байеса. Здесь мы обсудили базовую концепцию, работу, преимущества и недостатки наивного байесовского алгоритма. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Алгоритм повышения
- Алгоритм в программировании
- Введение в алгоритм