

Введение в условное форматирование в Tableau
Много раз в ходе анализа мы сталкивались с ситуациями, когда возникает необходимость в быстрой классификации. Классификация помогает понять важные различия, на основе которых может быть принято решающее решение в контексте проблемы. Среди способов быстрой классификации данных, один широко используемый подход - это условное форматирование. Как следует из названия, это по сути означает форматирование значений данных на основе определенных условий, и цветовое кодирование является наиболее важной частью этого инструмента анализа данных. Tableau благодаря своим универсальным функциям условного форматирования позволяет применять эту концепцию даже к графам, которые делают визуализации достаточно интерактивными и коммуникативными.
Как выполнить условное форматирование в таблице?
Теперь мы изучим пошаговый подход к выполнению условного форматирования в Таблице через три вида иллюстраций:
Иллюстрация 1
Для первой демонстрации мы используем данные объема распределения, которые содержат объем, распределенный по распределенным единицам. Важными измерениями здесь являются регион и единица распределения, а объем распределения - это показатель. Наша цель - классифицировать единицы распределения на основе объема распределения. Мы распределим их по категориям распределения: очень высокий, высокий, средний и низкий объем. Как мы это сделаем, посмотрим:
Шаг 1: Чтобы загрузить источник данных, нажмите «Новый источник данных» в меню «Данные». Или нажмите «Подключиться к данным».
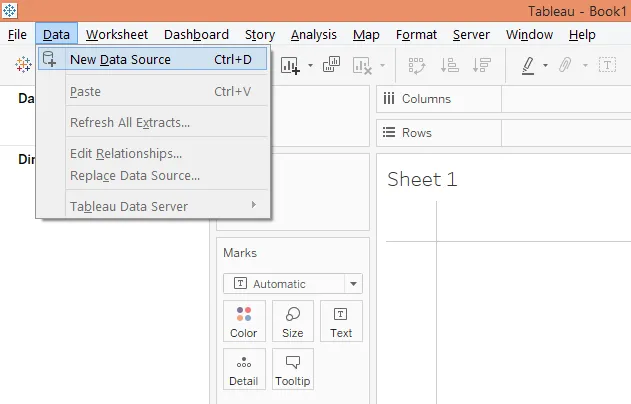
Шаг 2: Теперь в разделе «Подключение» выберите необходимый тип источника данных. В данном случае это «Microsoft Excel». Затем загрузите данные.
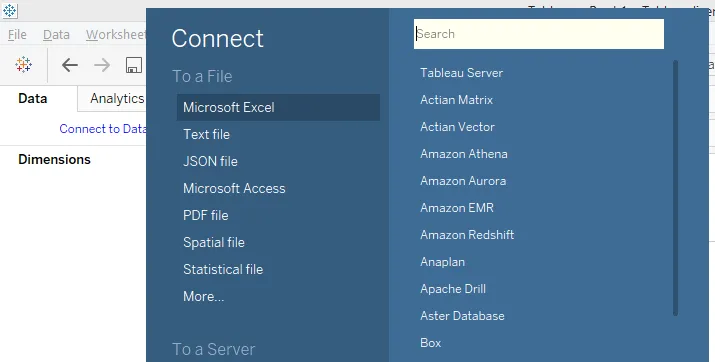
Шаг 3: Загруженные данные можно увидеть на вкладке «Источник данных», как показано на скриншоте ниже.
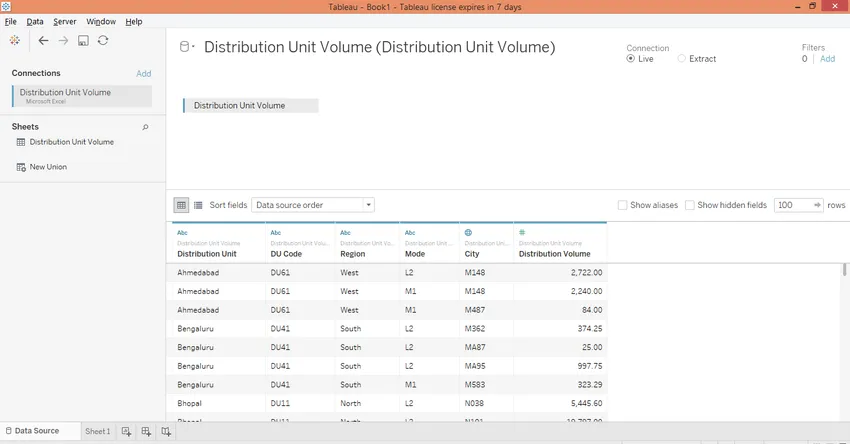
Шаг 4. Перейдя на вкладку листа, мы увидим размеры и меру, присутствующие в наборе данных. Они присутствуют в соответствующих разделах.
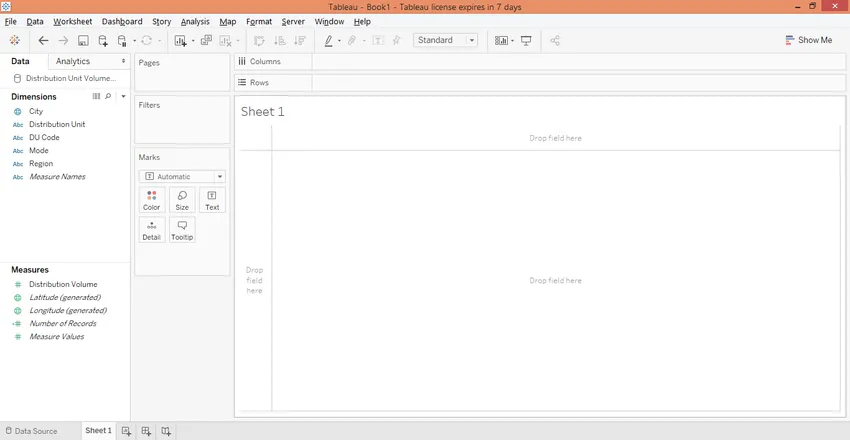
Шаг 5: Для начала перетащите единицу измерения измерения в область строк и измерьте объем распределения в область столбцов. Горизонтальная гистограмма генерируется, как показано ниже. Если тип диаграммы по умолчанию отличается, выберите гистограмму в «Показать меня».
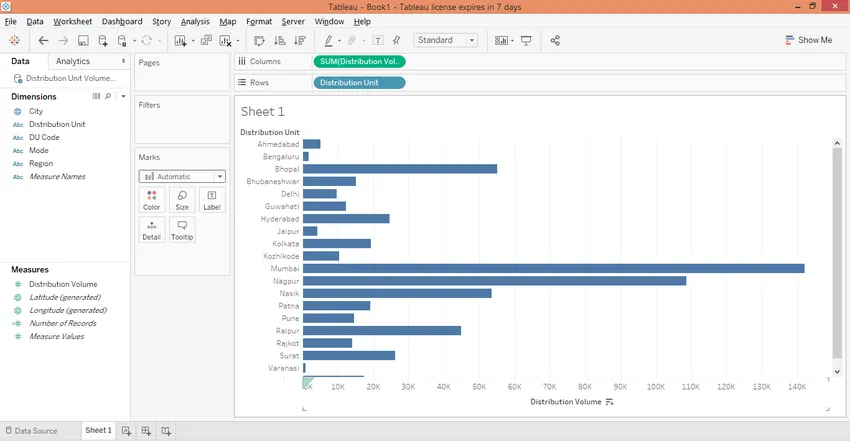
Шаг 6: Сортируйте результат в порядке убывания, щелкая значок сортировки, как показано на снимке экрана ниже.
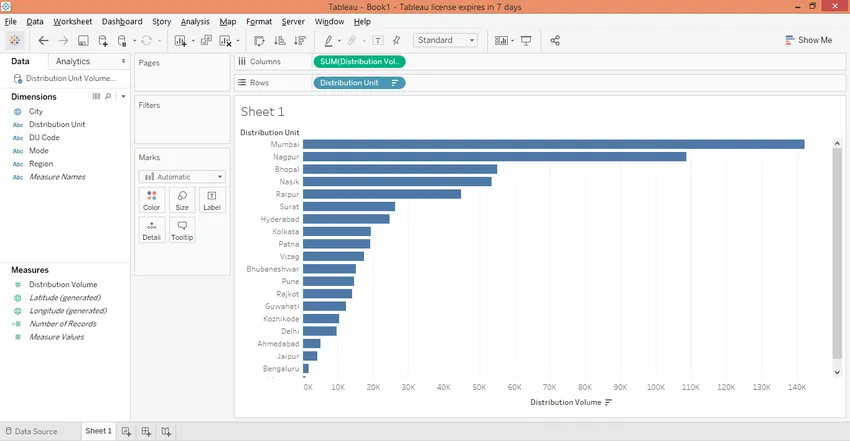
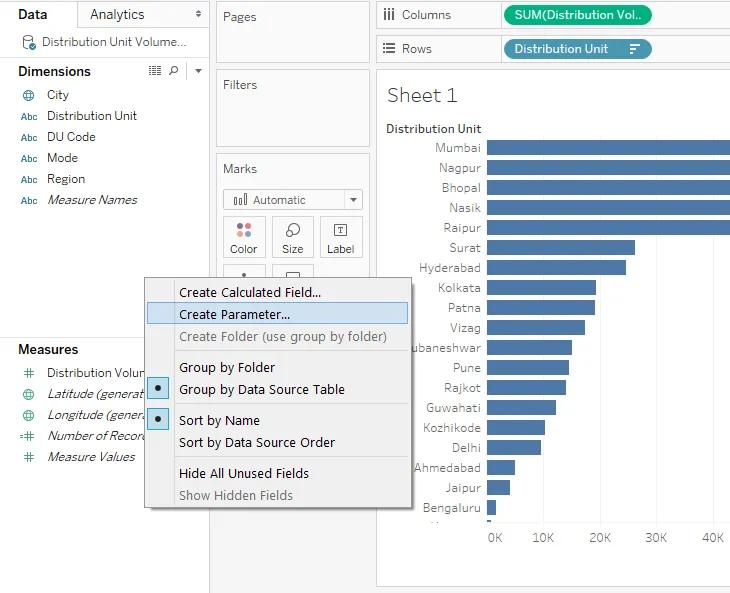
Шаг 7: Далее мы создадим три параметра, которые мы будем использовать для достижения нашей цели. Параметры в основном помогут классифицировать единицы распределения на основе объемов распределения. Чтобы создать первый параметр, щелкните правой кнопкой мыши в любом месте пустого пространства в разделе «Данные» и нажмите «Создать параметр…», как показано на снимке экрана ниже.
Шаг 8: После описанной выше процедуры появляется диалоговое окно «Создать параметр», как показано ниже.
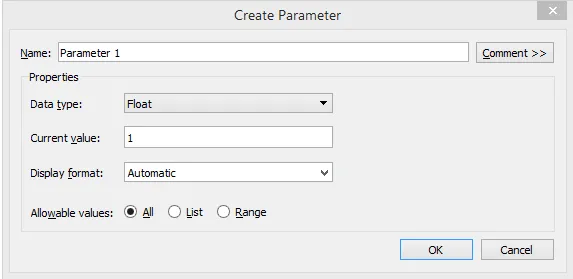
Шаг 9: Выполните следующие изменения в диалоговом окне «Создать параметр». Измените имя на «Threshold_1», сохраните тип данных «Float» и установите текущее значение равным 100 000 с форматом отображения «Автоматически» и «Допустимые значения», установленными на «Все». Наконец, нажмите кнопку ОК, чтобы создать параметр. Это как показано ниже.
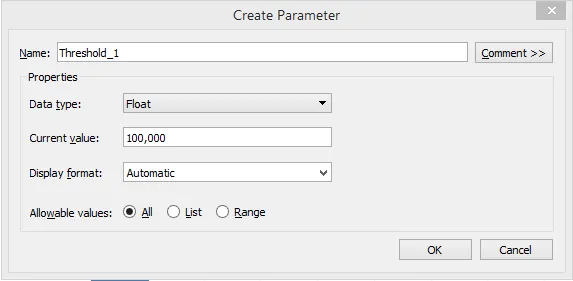
Шаг 10: Аналогично, создайте второй параметр с именем «Threshold_2», с текущим значением, установленным на 50 000, с другими деталями, установленными, как показано ниже.
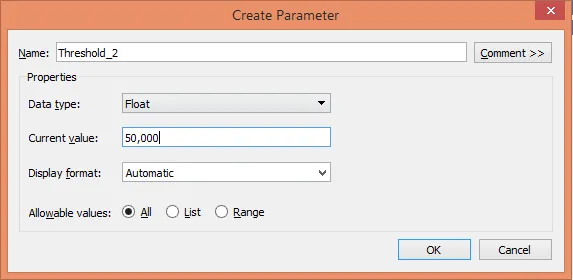
Шаг 11: Наконец, создайте третий параметр. Назовите его «Порог_3». Установите текущее значение для этого параметра на 25 000 с другими деталями, установленными, как показано ниже.
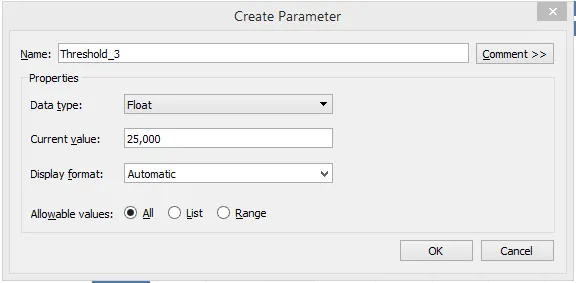
Шаг 12: Три параметра, которые мы создали, можно увидеть, как показано на скриншоте ниже. Теперь мы будем использовать их соответствующим образом для достижения нашей цели.
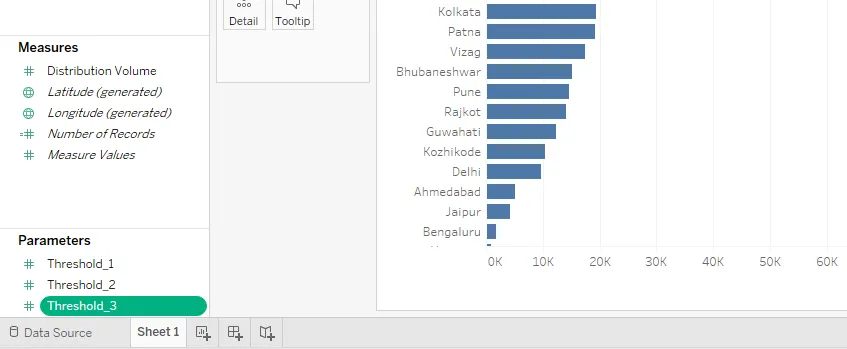
Шаг 13: Созданные нами параметры не будут служить нашей цели, если они не используются в вычисляемом поле для правильной классификации единиц распределения на основе объема распределения. Итак, далее мы создадим вычисляемое поле. Для этого щелкните правой кнопкой мыши в любом месте пустого пространства в разделе «Данные» и выберите «Создать вычисляемое поле…».
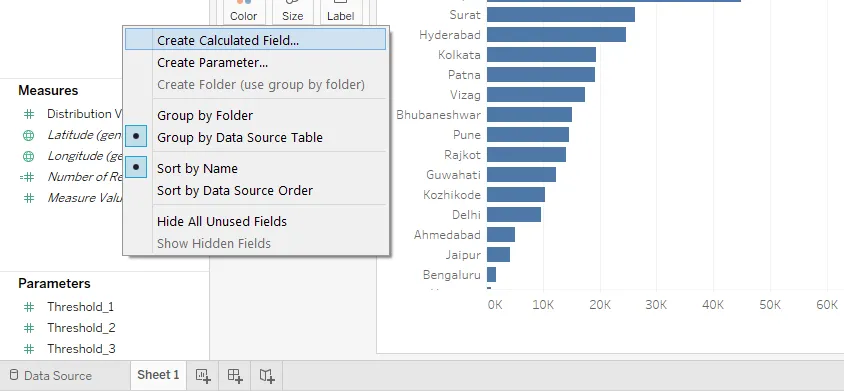
Шаг 14: Поле, которое мы создали, выглядит так, как показано ниже. Мы назвали это «DU Classification». Самый важный момент, мы использовали три параметра, которые мы создали ранее в вычисляемом поле. Что делает код, так это то, что если для какого-либо значения единицы распределения больше, чем Threshold_1, т. Е. 100 000, то он будет классифицироваться как «Очень большой объем DU». Точно так же это сделает другие классификации.
Примечание: мы не жестко кодировали значения в поле, потому что жесткое кодирование может не позволить нам иметь дело с изменениями на основе контекста. Если в нашем распоряжении есть параметры, то при изменении контекста изменяющиеся значения параметров будут соответственно отражаться в вычисляемом поле. Например, если мы намерены классифицировать единицы распределения с объемом распределения более 200 000 как DU очень высокого объема, то мы просто изменим текущее значение для Threshold_1 с 100 000 до 200 000 без фактического изменения значения в коде в вычисляемом поле.
Шаг 15: Как видно на скриншоте ниже, вычисленное поле «DU Classification» появляется в разделе «Меры».
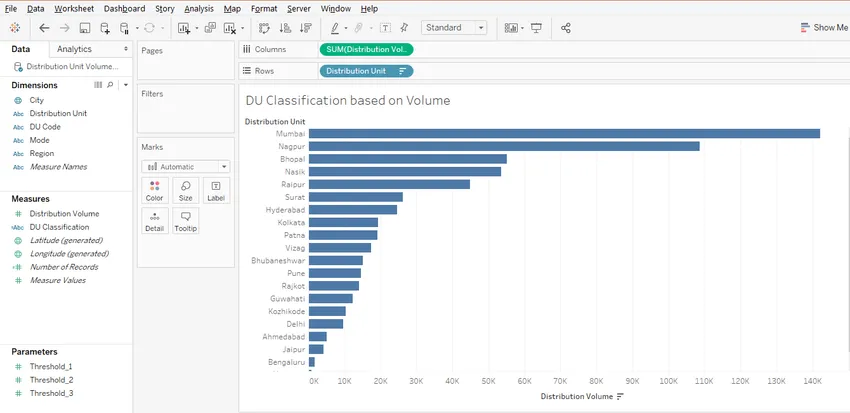
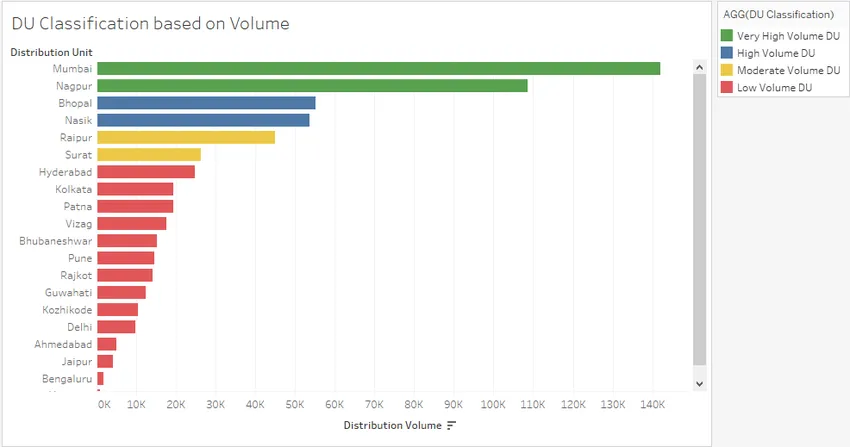
Шаг 16. Просто перетащите вычисляемое поле «Классификация DU» на «Цвет в метках», и, как мы видим на скриншоте ниже, Распределительные единицы делятся на четыре различные категории в зависимости от их объема. Категории можно увидеть на правой стороне скриншота.
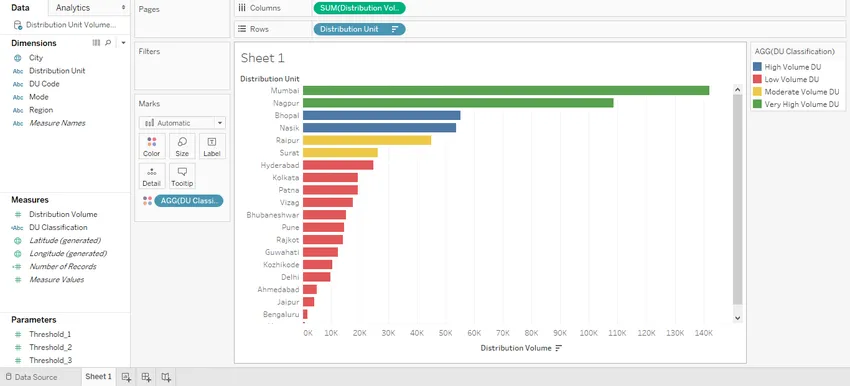
Шаг 17: Давайте ближе посмотрим на визуализацию. Также мы меняем порядок категорий в легенде; это можно сделать, просто перетаскивая категорию вверх или вниз с помощью мыши. Теперь в легенде категории, кажется, находятся в правильном порядке.
Шаг 18: И последнее, но не менее важное: мы можем изменить цвет категории. Для этого просто щелкните «Цвет» на карточке «Метки», затем нажмите «Редактировать цвета», чтобы выбрать нужные цвета.
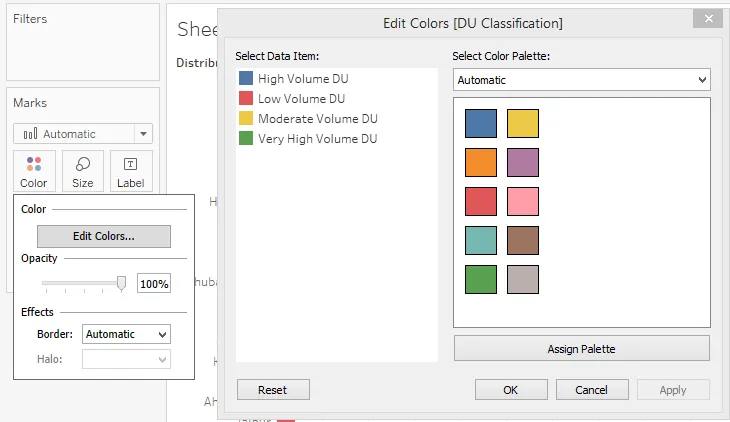
Иллюстрация 2
На этом рисунке мы собираемся выполнить форматирование условия типа Microsoft Excel. В Microsoft Excel у нас есть готовая опция, которая форматирует цвет фона ячеек на основе значений. Здесь степень цвета изменяется в зависимости от величины значения. Однако в Таблице все становится довольно сложно, особенно когда мы намереваемся использовать такого рода условное форматирование в нашем анализе. Чтобы достичь цели, мы немного сойдем с трассы. Давайте посмотрим, как мы можем сделать это в Таблице.
Шаг 1: Наши данные для этой демонстрации содержат показатели прибыли и продаж для двадцати крупных городов Индии. Данные были загружены в таблицу. Переходя к вкладке листа, мы видим единственное измерение City и два показателя Profit и Sales, представленные в соответствующих разделах.
Шаг 2: Чтобы быть с, перетащите измерение City в область Rows, как показано ниже.
Шаг 3: Следующий шаг - создать вычисляемое поле. Это как показано ниже.
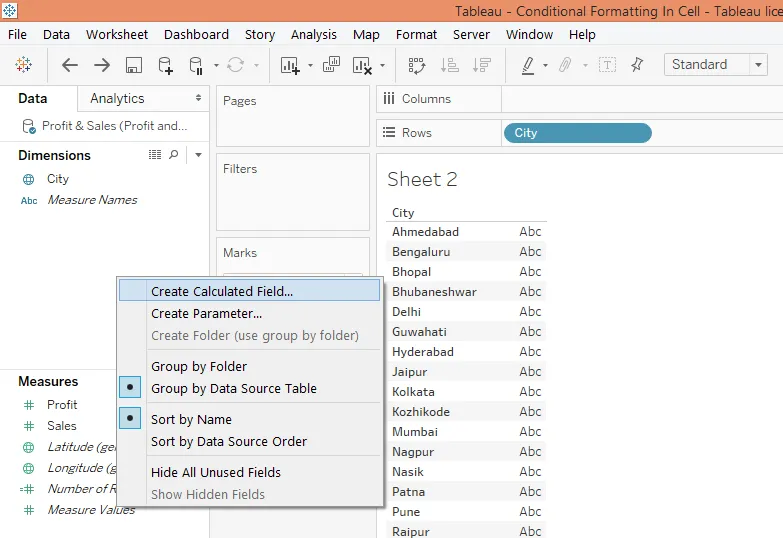
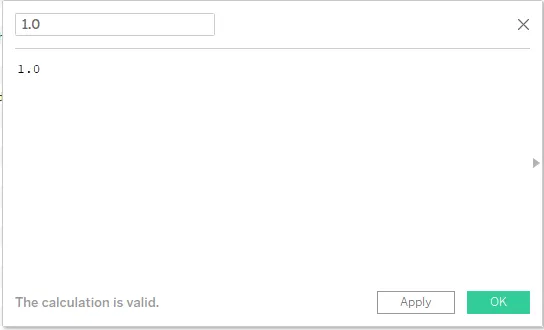
Шаг 4: Создайте вычисляемое поле с именем 1.0, а также напишите 1.0 в разделе кода. После создания это поле можно увидеть в разделе «Меры», как показано на снимке экрана после снимка экрана ниже.
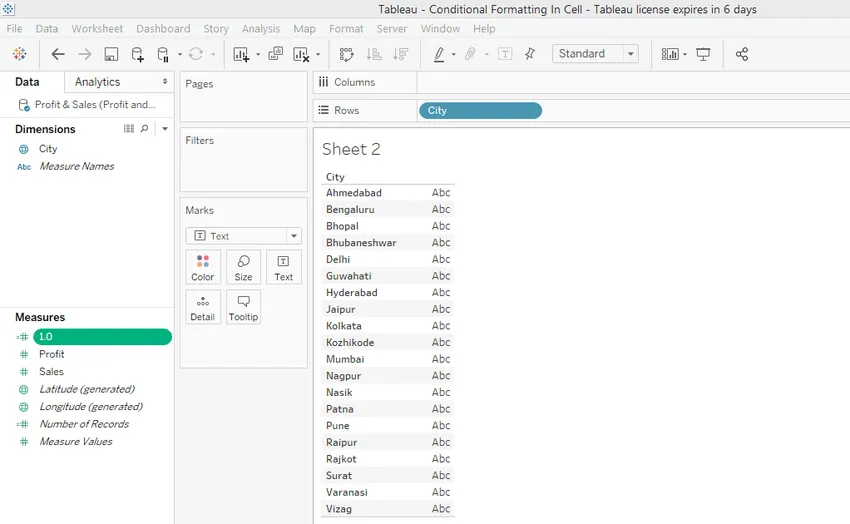
Шаг 5: Перетащите вычисленное поле 1.0 дважды по одному в область Столбцы. Измените тип 1, 0 на AVG (средний). Для этого перейдите в выпадающее меню поля, затем нажмите «Среднее по мере».
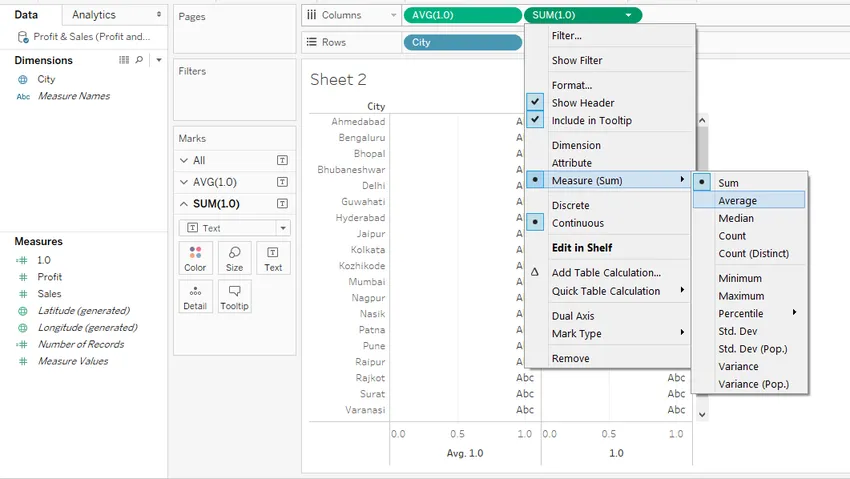
Шаг 6: Далее, в выпадающем меню второго показателя 1.0, нажмите «Двойная ось». Это как показано на скриншоте ниже.
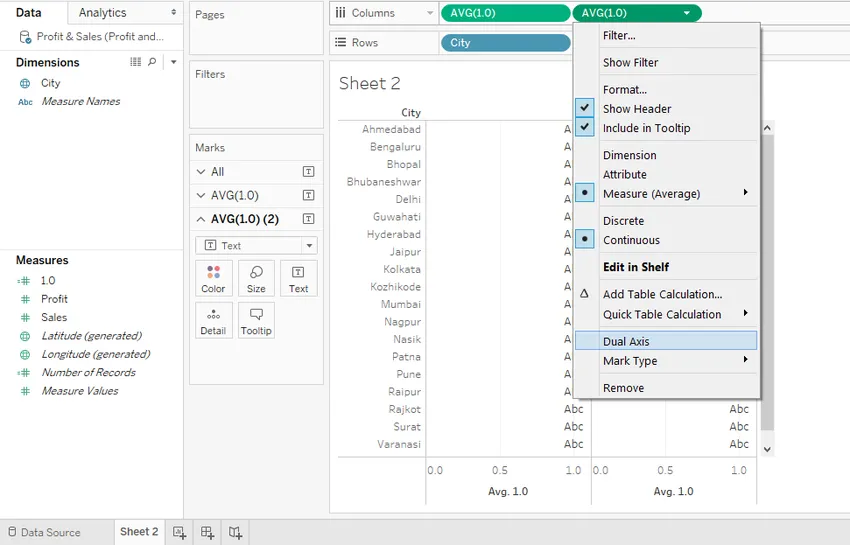
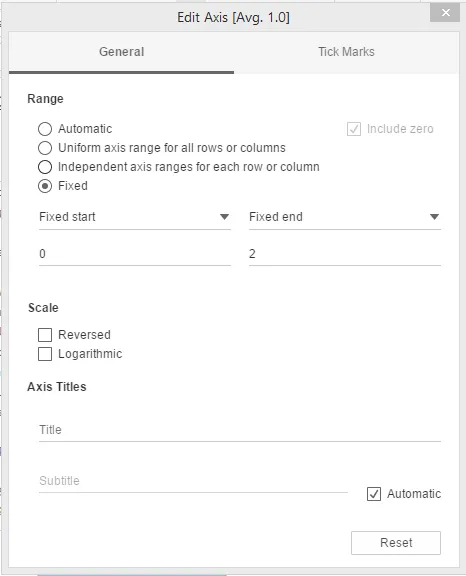
Шаг 7: Теперь мы изменим верхнюю и нижнюю оси. Щелкните правой кнопкой мыши по верхней оси и выберите запись «Редактировать ось», в которой появляется диалоговое окно, как показано на снимке экрана, следующем за снимком экрана ниже.
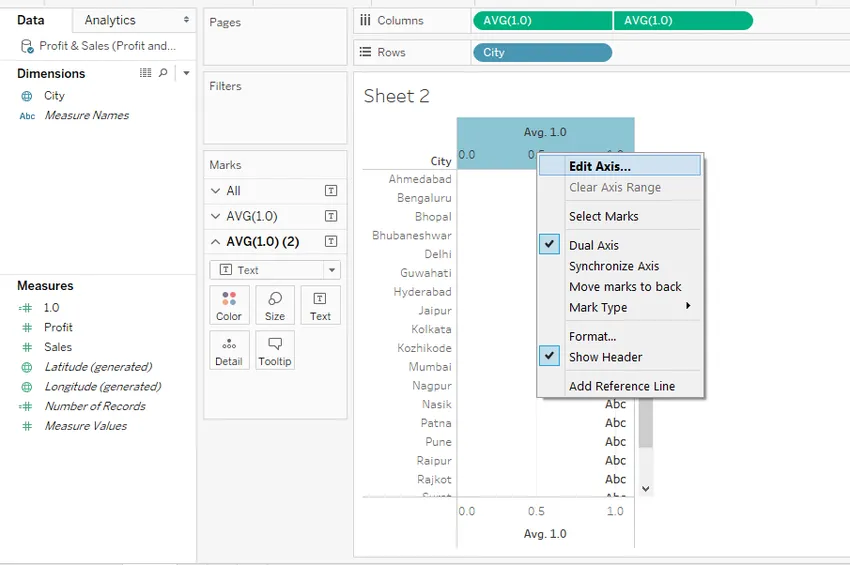
Шаг 8. Выбор и значения по умолчанию в диалоговом окне «Редактировать ось» показаны на снимке экрана ниже.
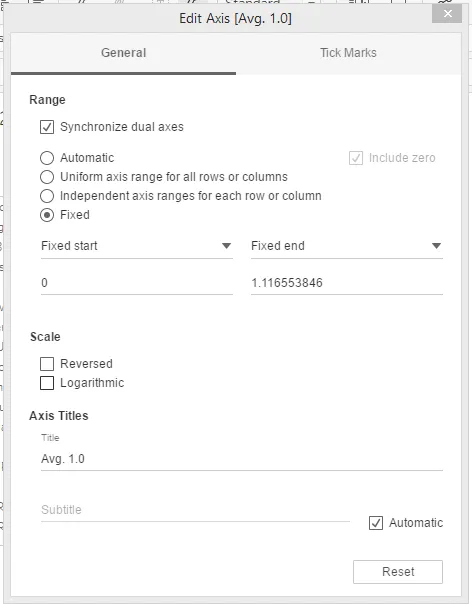
Шаг 9: Убедитесь, что изменения в разделе «Общие» диалогового окна «Редактировать ось» выполнены, как показано ниже.
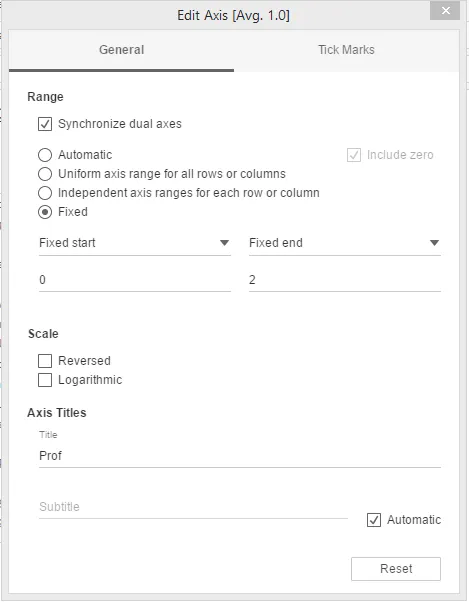
Шаг 10: Теперь, в разделе «Tick Marks» диалогового окна, выберите «None» для Major Tick Marks, а также Minor Tick Marks.
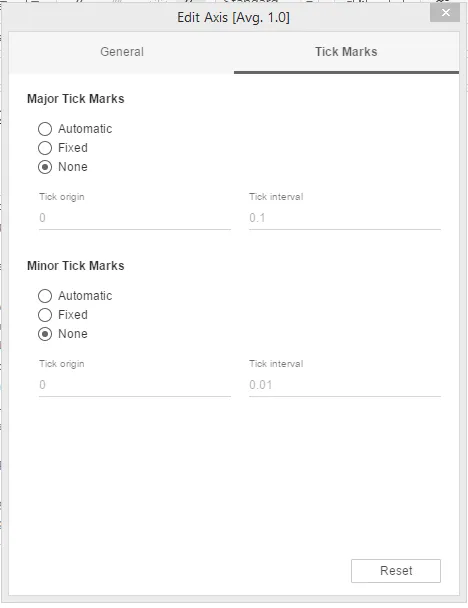
Шаг 11: Для нижней оси также выполните изменения в разделе «Общие» и «Метки», аналогичные тем, которые выполняются в верхней оси, за исключением того, что заголовок остается пустым в разделе «Общие», как показано ниже.
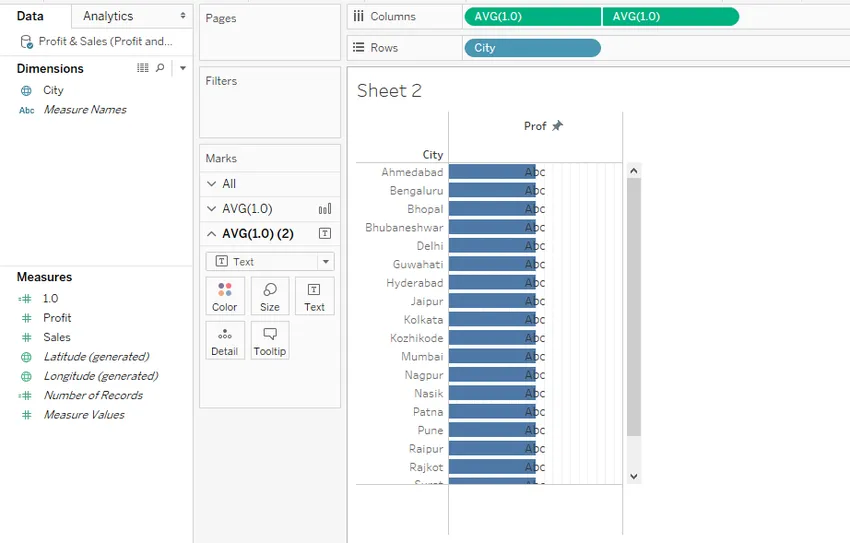
Шаг 12: Выполнение вышеуказанных шагов дает нам следующую визуализацию. Обратите внимание, что синие столбцы - половина размера ячейки, потому что в «Фиксированном конце» в разделе «Общие» диалогового окна «Редактировать ось» у нас есть значение 2, а в поле 1.0 - значение 1.
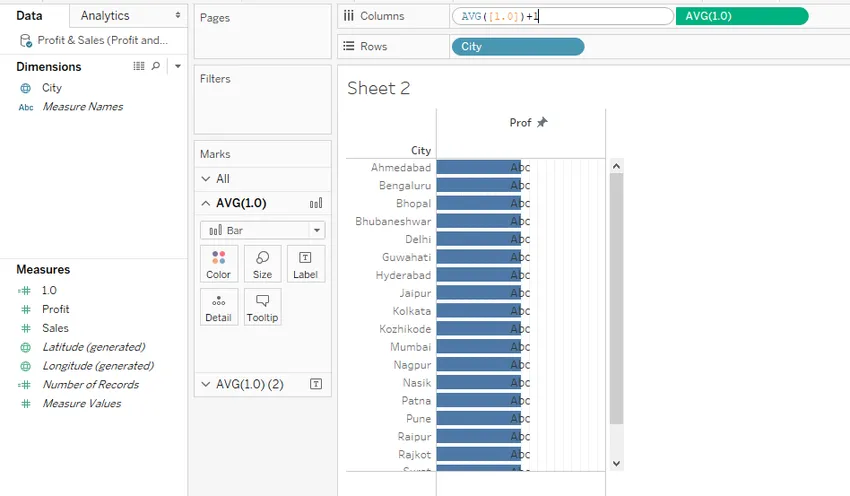
Шаг 13: Чтобы получить полноразмерные бары, дважды щелкните по таблетке первой меры 1.0 и просто добавьте 1, как показано ниже.
Шаг 14: Вышеуказанные шаги дают нам полноразмерные столбцы в ячейках, как видно на скриншоте ниже.
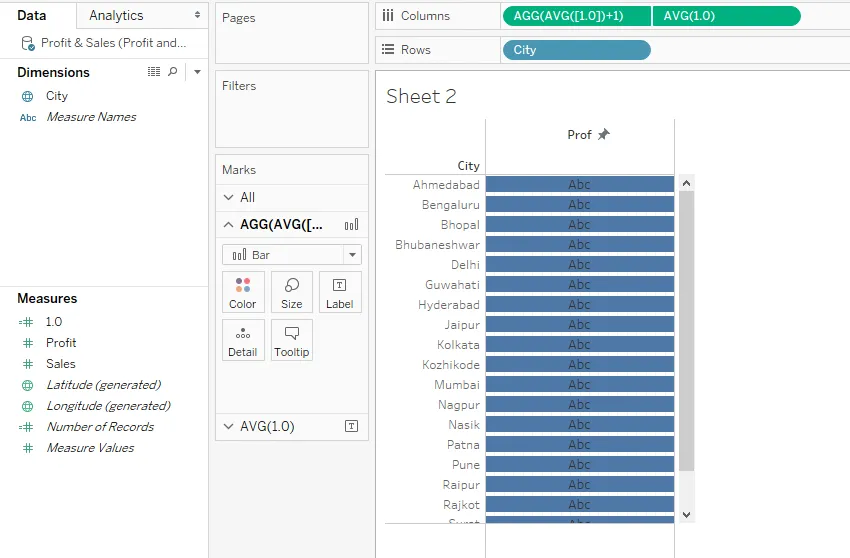
Шаг 15: Теперь, для первого поля 1.0 в Карте Знаков, перетащите Прибыль на Цвет. Это дает разные цветные полосы. Обратите внимание, что разноцветные столбцы обусловлены разными значениями прибыли.
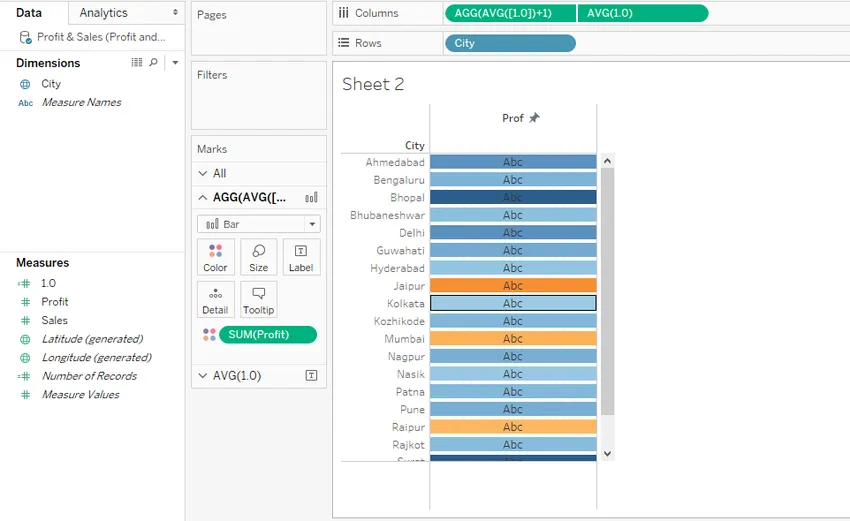
Шаг 16. Теперь, во втором показателе 1.0, перетащите Прибыль поверх карты «Текст в метках», это отобразит значения в ячейках, как показано ниже.
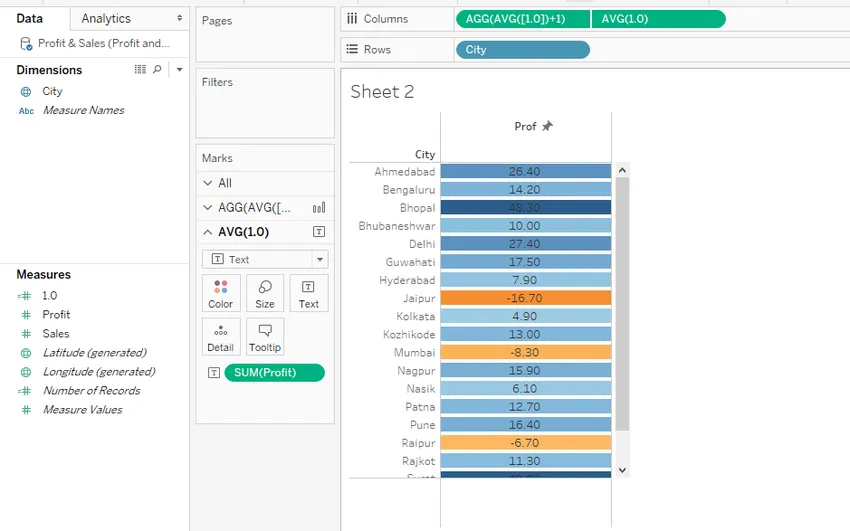
Шаг 17: На скриншоте выше мы видим, что цвета не заполнили всю ячейку. Чтобы полностью заполнить ячейку цветом, выберите самый большой размер, перетаскивая ползунок размера в крайнюю правую сторону для первого поля 1.0. Это показано ниже. И, как мы видим, теперь клетки полностью закрашены.
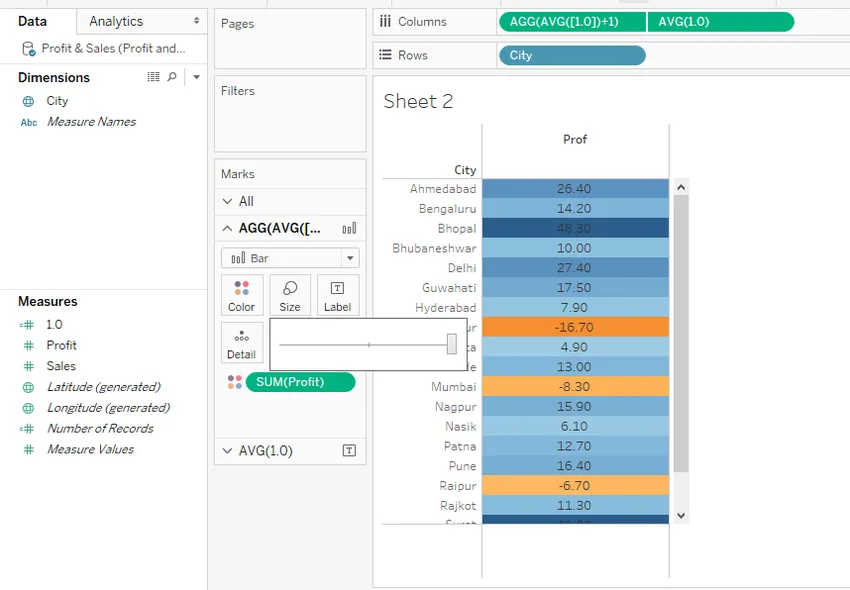
Шаг 18. Если мы находим яркость цветов фона очень высокой, мы изменяем ее, чтобы уменьшить ее, регулируя непрозрачность в соответствии с требованием, с помощью ползунка «Непрозрачность» в разделе «Цвет». В этом случае мы сохранили непрозрачность до 90%. Точно так же мы можем настроить непрозрачность для текстовых значений с помощью настроек во втором показателе 1.0. Тем не менее, непрозрачность для текстовых значений должна быть сохранена до 100%, чтобы они четко отображались на фоне цветов. Обратите внимание, что в приведенной ниже визуализации мы можем видеть, что отрицательные значения четко отличаются от положительных. Отрицательные значения обозначаются оранжевым цветом, а синим - для положительных значений. Кроме того, в зависимости от значения степень яркости изменяется для цвета.
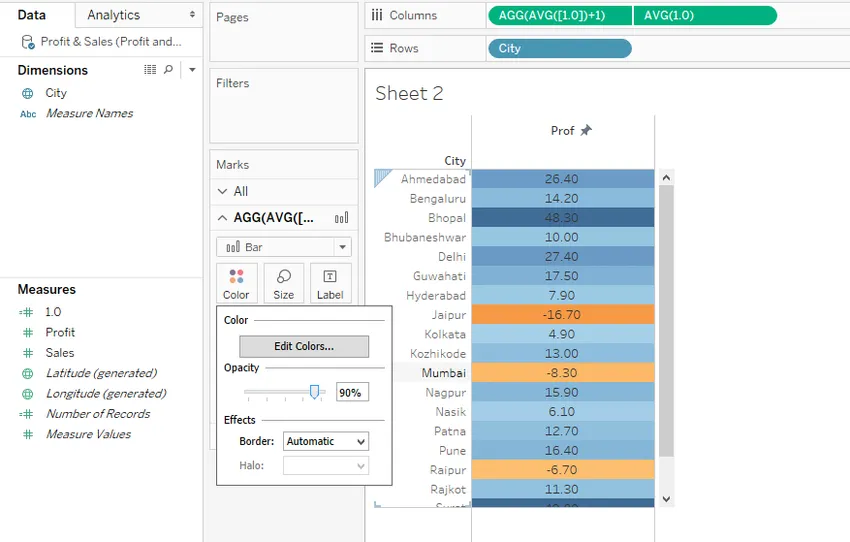
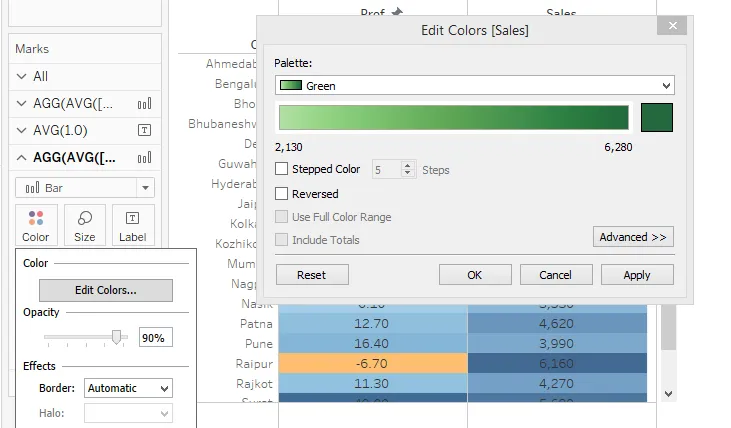
Шаг 19: Вышеуказанные шаги, которые мы выполнили для показателя Profit. У нас есть еще одна важная мера в наборе данных, это Продажи. Для измерения продаж мы также намерены провести аналогичный анализ. Итак, просто повторите вышеуказанные шаги. Наконец, измените цвет для продаж на зеленый, как показано ниже, или можно выбрать любой подходящий цвет.
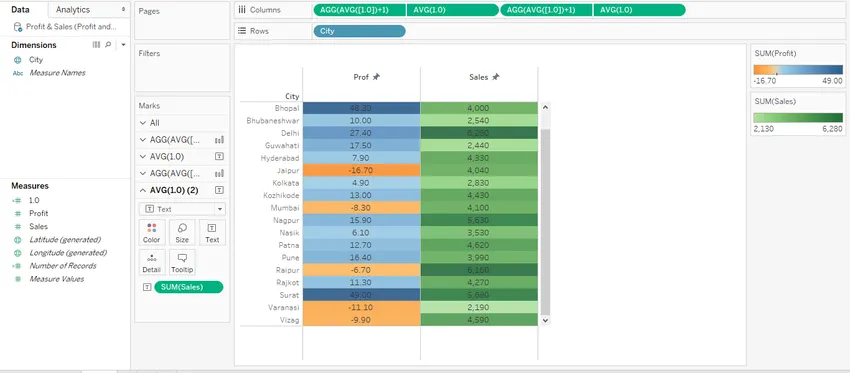
Шаг 20: Теперь анализ, который мы выполнили с использованием условного форматирования, выглядит так, как показано на скриншоте ниже. Справа мы видим цвет, назначенный на основе диапазона значений Profit и Sales. Это зависящее от значений цветовое основанное на цветах форматирование, которое предлагает важную информацию о данных, дает концепции имя.
Шаг 21: На следующем снимке экрана мы более подробно рассмотрим анализ, который мы провели с использованием условного форматирования. 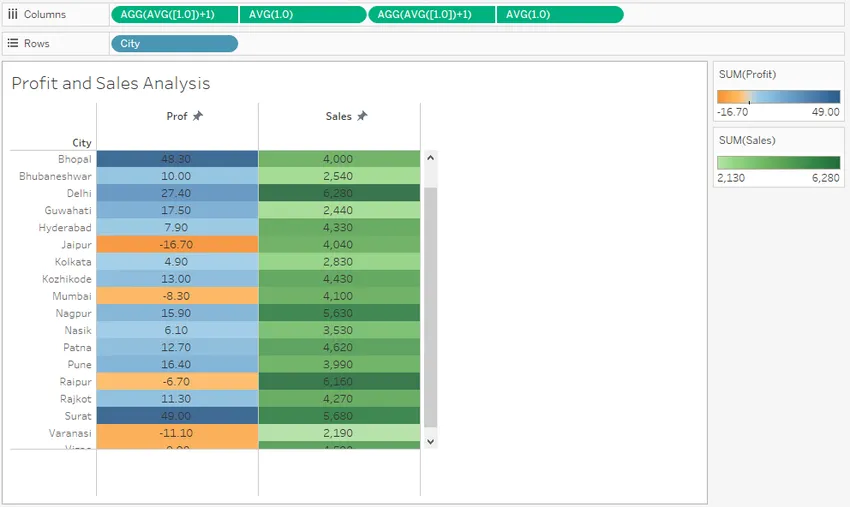
Иллюстрация 3
Для этой иллюстрации мы будем использовать набор данных, использованный на первой иллюстрации. Здесь мы выделим пятерку лучших и пятерку нижних городов Поехали в Таблицу:
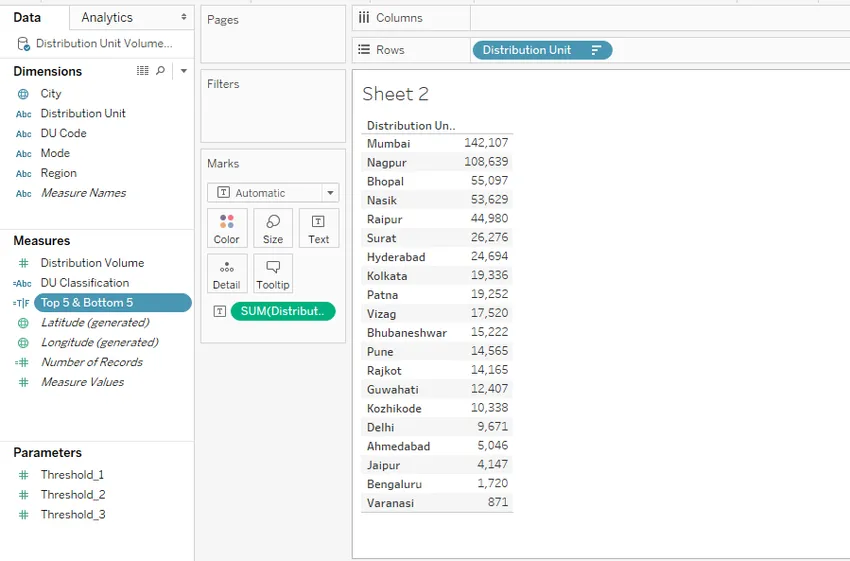
Шаг 1: у нас есть данные, загруженные с измерениями и мерами, как показано на скриншоте ниже.
Шаг 2: Перетащите единицу измерения измерения в область строк и измерьте объем распределения по тексту на карте меток, как показано на снимке экрана ниже.
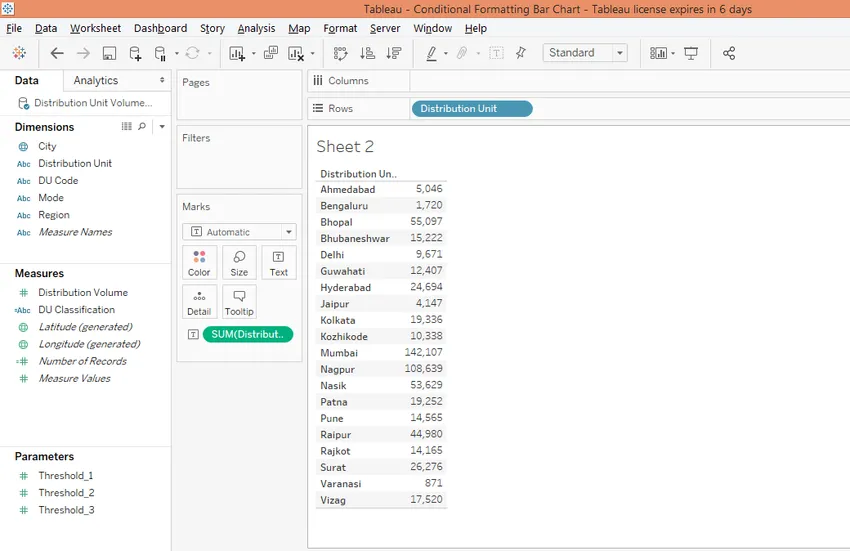
Шаг 3: Сортируйте результат в порядке убывания, чтобы получить города с наивысшим или минимальным объемом распределения. Это как показано ниже.
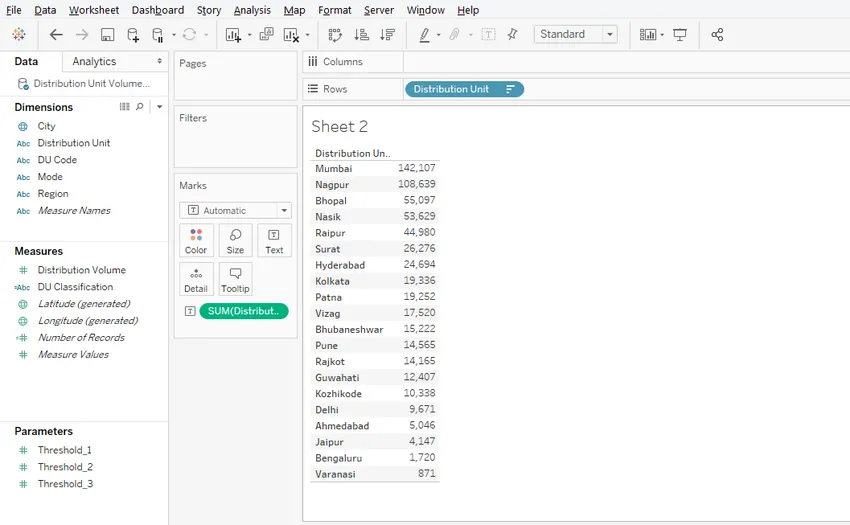
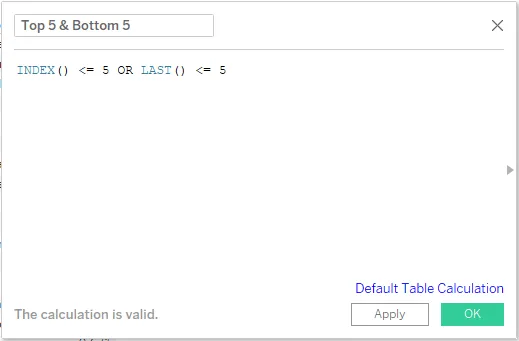
Шаг 4: Затем создайте вычисляемое поле. Шаги для создания вычисляемого поля были описаны в предыдущих разделах. Мы хотим выделить верхнюю пятерку и нижнюю пятерку единиц распределения, поэтому назовите рассчитанное поле как «Top 5 & Bottom 5». В разделе кода мы используем функции INDEX () и LAST (). Функция INDEX () возвращает индекс текущей строки, а функция LAST () возвращает количество строк от текущей строки до последней строки. INDEX () начинает вычисление с 1, а LAST () начинается с 0. Обе функции были использованы, как показано на скриншоте ниже.
Шаг 5: Вновь созданное вычисляемое поле отображается как мера, как показано на снимке экрана ниже.
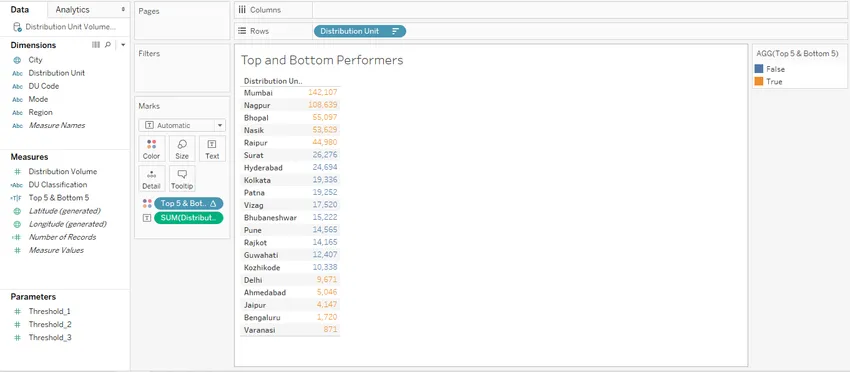
Шаг 6: Теперь просто перетащите только что созданное вычисляемое поле «Top 5 & Bottom 5» на Color на карточке Marks, и мы увидим, что верхняя и нижняя 5 областей выделены красным цветом. Категории отображаются в виде значений False и True, которые можно увидеть в правой части экрана.
Вывод
Посредством различных иллюстраций мы попытались глубже понять концепцию условного форматирования в Tableau. Однако, будучи очень интерактивным инструментом визуализации, можно обнаружить несколько способов, которые требуют использования функций, предоставляемых этим инструментом. Таким образом, Tableau облегчает применение условного форматирования к визуализациям без ограничения фиксированным способом.
Рекомендуемые статьи
Это руководство по условному форматированию в таблице. Здесь мы обсуждаем пошаговый подход к выполнению условного форматирования в Таблице через три вида иллюстраций. Вы также можете просмотреть другие наши статьи, чтобы узнать больше-
- Таблицы Графики
- Tableau Dashboard Design
- Таблица типов диаграмм
- Создание набора в таблице
- Таблица агрегатных функций
- Поворот в Таблице
- Tableau Context Filter
- Tableau Bullet Chart
- Введение в особенности и атрибуты таблицы
- Как создать группы в таблице?