

Введение в алгоритм AdaBoost
Алгоритм AdaBoost может быть использован для повышения производительности любого алгоритма машинного обучения. Машинное обучение стало мощным инструментом, который может делать прогнозы на основе большого количества данных. Это стало настолько популярным в последнее время, что применение машинного обучения можно найти в нашей повседневной деятельности. Типичным примером этого является получение предложений для продуктов при совершении покупок в Интернете на основе прошлых товаров, купленных клиентом. Машинное обучение, часто называемое прогнозным анализом или прогнозным моделированием, может быть определено как способность компьютеров обучаться без явного программирования. Он использует запрограммированные алгоритмы для анализа входных данных, чтобы предсказать выходные данные в приемлемом диапазоне.
Что такое алгоритм AdaBoost?
В машинном обучении повышение произошло из вопроса о том, можно ли преобразовать набор слабых классификаторов в сильный классификатор. Слабый ученик или классификатор - это ученик, который лучше, чем случайные догадки, и он будет надежным в переопределении, как в большом наборе слабых классификаторов, причем каждый слабый классификатор лучше случайного. В качестве слабого классификатора обычно используется простой порог для одного признака. Если функция выше порога, чем прогнозировалось, она принадлежит положительному, в противном случае - отрицательному.
AdaBoost означает «адаптивное повышение», которое превращает слабых учеников или предикторов в сильных предикторов для решения задач классификации.
Для классификации окончательное уравнение можно поставить так: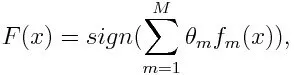
Здесь f m обозначает m- й слабый классификатор, а m обозначает соответствующий ему вес.
Как работает алгоритм AdaBoost?
AdaBoost может быть использован для повышения производительности алгоритмов машинного обучения. Он лучше всего используется для слабых учеников, и эти модели достигают более высокой точности, чем случайный случай, при решении задачи классификации. Общие алгоритмы с AdaBoost - это деревья решений первого уровня. Слабый ученик - это классификатор или предиктор, который относительно плохо работает с точки зрения точности. Кроме того, можно подразумевать, что слабых учеников просто вычислить, и многие экземпляры алгоритмов объединяются для создания сильного классификатора посредством повышения.
Если мы возьмем набор данных, содержащий п количество точек, и рассмотрим ниже
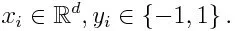
-1 обозначает отрицательный класс, а 1 обозначает положительный. Инициализируется, как показано ниже, вес для каждой точки данных как:
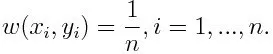
Если мы рассмотрим итерацию от 1 до M для m, мы получим следующее выражение:
Во-первых, мы должны выбрать слабый классификатор с наименьшей взвешенной ошибкой классификации, подгоняя слабые классификаторы к набору данных.
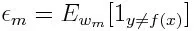
Затем вычисляем вес для m- го слабого классификатора, как показано ниже:
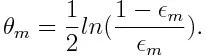
Вес является положительным для любого классификатора с точностью выше 50%. Вес становится больше, если классификатор более точен, и становится отрицательным, если точность классификатора составляет менее 50%. Прогноз может быть объединен путем инвертирования знака. Путем инверсии знака прогноза классификатор с точностью до 40% может быть преобразован в точность с 60%. Таким образом, классификатор способствует окончательному прогнозированию, даже если он работает хуже, чем случайные предположения. Тем не менее, окончательный прогноз не будет иметь никакого вклада или получить информацию от классификатора с точностью до 50%. Экспоненциальный член в числителе всегда больше 1 для неправильно классифицированного случая из положительно взвешенного классификатора. После итерации неправильно классифицированные случаи обновляются с большими весами. Отрицательно взвешенные классификаторы ведут себя так же. Но есть разница, что после того, как знак перевернут; правильные классификации первоначально превратятся в неправильную классификацию. Окончательный прогноз можно рассчитать с учетом каждого классификатора, а затем выполнить сумму их взвешенного прогнозирования.
Обновление веса для каждой точки данных, как показано ниже:
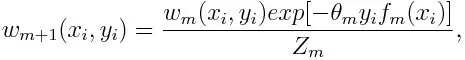
Z m здесь коэффициент нормализации. Это гарантирует, что общая сумма всех весов экземпляра станет равной 1.
Для чего используется алгоритм AdaBoost?
AdaBoost можно использовать для обнаружения лиц, так как он кажется стандартным алгоритмом обнаружения лиц на изображениях. Он использует каскад отклонения, состоящий из множества слоев классификаторов. Когда окно обнаружения не распознается на каком-либо слое как лицо, оно отклоняется. Первый классификатор в окне отбрасывает отрицательное окно, сводя вычислительные затраты к минимуму. Хотя AdaBoost сочетает в себе слабые классификаторы, принципы AdaBoost также используются для поиска лучших функций для использования на каждом уровне каскада.
Плюсы и минусы алгоритма AdaBoost
Одним из многих преимуществ алгоритма AdaBoost является его быстрота, простота и легкость в программировании. Кроме того, он обладает гибкостью, которую можно комбинировать с любым алгоритмом машинного обучения, и нет необходимости настраивать параметры, кроме T. Он был расширен для изучения проблем, выходящих за рамки двоичной классификации, и он универсален, поскольку его можно использовать с текстовым или числовым данные.
AdaBoost также имеет несколько недостатков, таких как эмпирические данные и особенно уязвим для равномерного шума. Слабые классификаторы, являющиеся слишком слабыми, могут привести к низкой марже и переоснащению.
Пример алгоритма AdaBoost
Мы можем рассмотреть пример поступления студентов в университет, где они будут либо приняты, либо от них отказано. Здесь количественные и качественные данные можно найти с разных сторон. Например, результат приема, который может быть да / нет, может быть количественным, тогда как любая другая область, такая как навыки или хобби студентов, может быть качественной. Мы можем легко придумать правильную классификацию обучающих данных с большей вероятностью, чем шанс для условий, например, если ученик хорошо разбирается в конкретном предмете, то он / она допускается. Но трудно найти очень точный прогноз, и тогда слабые ученики входят в картину.
Вывод
AdaBoost помогает в выборе обучающего набора для каждого нового классификатора, который обучается на основе результатов предыдущего классификатора. Также при объединении результатов; он определяет, какой вес следует придать каждому предложенному классификатору ответу. Он объединяет слабых учеников, чтобы создать сильного ученика для исправления ошибок классификации, что также является первым успешным алгоритмом повышения для задач двоичной классификации.
Рекомендуемые статьи
Это было руководство по алгоритму AdaBoost. Здесь мы обсудили концепцию, использование, работу, плюсы и минусы с примером. Вы также можете просмотреть наши другие Предлагаемые статьи, чтобы узнать больше -
- Наивный байесовский алгоритм
- Интервью по маркетингу в социальных сетях
- Стратегии построения ссылок
- Маркетинговая платформа в социальных сетях