

Введение в интеллектуальный анализ данных
Это метод интеллектуального анализа данных, используемый для размещения элементов данных в их похожих группах. Кластер - это процедура разделения объектов данных на подклассы. Качество кластеризации зависит от метода, который мы использовали. Кластеризацию также называют сегментацией данных, так как большие группы данных делятся по своему сходству.
Что такое кластеризация в интеллектуальном анализе данных?
Кластеризация - это группировка конкретных объектов на основе их характеристик и сходства. Что касается интеллектуального анализа данных, эта методология разделяет данные, которые лучше всего подходят для требуемого анализа, используя специальный алгоритм объединения. Этот анализ позволяет объекту не быть частью или строго частью кластера, который называется жестким разделением этого типа. Однако гладкие разбиения позволяют предположить, что каждый объект в одинаковой степени принадлежит кластеру. Более конкретные подразделения могут быть созданы как объекты нескольких кластеров, один кластер может быть вынужден участвовать или даже иерархические деревья могут быть построены в групповых отношениях. Эта файловая система может быть установлена по-разному в зависимости от модели. Эти Отдельные Алгоритмы применяются к каждой модели, отличая их свойства, а также их результаты. Хороший алгоритм кластеризации способен идентифицировать кластер независимо от формы кластера. Есть 3 основных этапа алгоритма кластеризации, которые показаны ниже
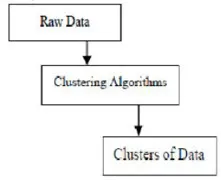
Алгоритмы кластеризации в интеллектуальном анализе данных
В зависимости от недавно описанных моделей кластеров, многие кластеры могут использоваться для разделения информации на набор данных. Следует сказать, что каждый метод имеет свои преимущества и недостатки. Выбор алгоритма зависит от свойств и характера набора данных.
Методы кластеризации для интеллектуального анализа данных могут быть показаны ниже
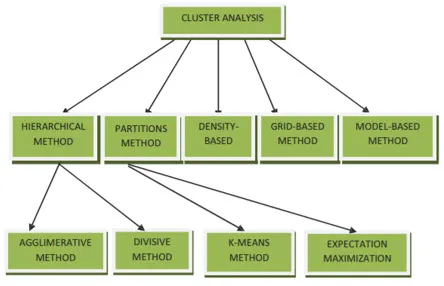
- Метод на основе разбиения
- Метод на основе плотности
- Центроидный метод
- Иерархический метод
- Метод на основе сетки
- Модельно-ориентированный метод
1. Метод на основе разбиения
Алгоритм разбиения делит данные на множество подмножеств.
Давайте предположим, что алгоритм разделения строит разделение данных, так как k и n - это объекты, присутствующие в базе данных. Следовательно, каждое разбиение будет представлено как k ≤ n.
Это дает представление о том, что классификация данных состоит из k групп, что может быть показано ниже.
На рисунке 1 показаны исходные точки в кластеризации

На рисунке 2 показана кластеризация разделов после применения алгоритма
Это указывает на то, что каждая группа имеет как минимум один объект, так как каждый объект должен принадлежать ровно к одной группе.
2. Метод на основе плотности
Эти алгоритмы создают кластеры в определенном месте на основе высокой плотности участников набора данных. Он объединяет некоторое понятие диапазона для членов группы в кластерах до стандартного уровня плотности. Такие процессы могут выполнять меньше при обнаружении областей поверхности группы.
3. Центроидный метод
Практически на каждый кластер ссылается вектор значений в этом типе группирования ОС. По сравнению с другими кластерами каждый объект является частью кластера с минимальной разницей в стоимости. Количество кластеров должно быть предопределено, и это самая большая проблема алгоритма такого типа. Эта методология наиболее близка к предмету идентификации и широко используется для задач оптимизации.
4. Иерархический метод
Метод создаст иерархическую декомпозицию заданного набора объектов данных. Основываясь на том, как формируется иерархическая декомпозиция, мы можем классифицировать иерархические методы. Этот метод дается следующим образом
- Агломерационный подход
- Разделительный подход
Агломерационный подход также известен как кнопочный подход. Здесь мы начнем с каждого объекта, который составляет отдельную группу. Он продолжает сливать объекты или группы близко друг к другу
Разделительный подход также известен как нисходящий подход. Начнем со всех объектов в одном кластере. Этот метод является жестким, то есть он никогда не может быть отменен после завершения слияния или разделения
5. Сеточный метод
Методы на основе сетки работают в объектном пространстве, а не делят данные на сетку. Сетка делится на основе характеристик данных. Используя этот метод, можно легко управлять нечисловыми данными. Порядок данных не влияет на разбиение сетки. Важным преимуществом модели на основе сетки является более высокая скорость выполнения.
Преимущества иерархической кластеризации заключаются в следующем
- Это применимо к любому типу атрибута.
- Это обеспечивает гибкость, связанную с уровнем детализации.
6. Модельно-ориентированный метод
Этот метод использует гипотетическую модель, основанную на распределении вероятностей. Кластеризация функции плотности, этот метод находит кластеры. Он отражает пространственное распределение точек данных.
Применение кластеризации в Data Mining
Кластеризация может помочь во многих областях, таких как биология, растения и животные, классифицированные по их свойствам, а также в маркетинге. Кластеризация поможет идентифицировать клиентов определенной клиентской записи с аналогичным поведением. Во многих приложениях, таких как исследование рынка, распознавание образов, обработка данных и изображений, кластерный анализ используется в больших количествах. Кластеризация также может помочь рекламодателям в их клиентской базе находить разные группы. И их группы клиентов могут быть определены путем покупки. В биологии он используется для определения таксономий растений и животных, для классификации генов с аналогичной функциональностью и для понимания структур, присущих популяциям. В базе данных наблюдения Земли кластеризация также облегчает поиск областей аналогичного использования на земле. Это помогает идентифицировать группы домов и квартир по типу, стоимости и назначению домов. Кластеризация документов в Интернете также полезна для обнаружения информации. Кластерный анализ - это инструмент, позволяющий получить представление о распределении данных для наблюдения за характеристиками каждого кластера в качестве функции интеллектуального анализа данных.
Вывод
Кластеризация важна для анализа данных и их анализа. В этой статье мы увидели, как можно кластеризовать, применяя различные алгоритмы кластеризации, а также его применение в реальной жизни.
Рекомендуемая статья
Это было руководство к тому, что такое кластеризация в Data Mining. Здесь мы обсудили понятия, определения, особенности, применение кластеризации в Data Mining. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Что такое обработка данных?
- Как стать аналитиком данных?
- Что такое SQL-инъекция?
- Определение того, что такое SQL Server?
- Обзор архитектуры интеллектуального анализа данных
- Кластеризация в машинном обучении
- Иерархический кластерный алгоритм
- Иерархическая кластеризация | Агломерационная и разделительная кластеризация