

Введение в ANOVA в R
В следующей статье ANOVA в R приводится схема для сравнения среднего значения разных групп. Дисперсионный анализ (ANOVA) - это очень распространенный метод, используемый для сравнения среднего значения разных групп. Модель ANOVA используется для проверки гипотез, где определенное предположение или параметр генерируется для совокупности, а статистический метод используется для определения, является ли гипотеза истинной или ложной.
Гипотеза основана на предположении исследователя и имеющейся информации о населении. ANOVA называется дисперсионным анализом и используется для проверки гипотез, где требуется измерять средние значения переменной в нескольких независимых группах.
Например, в лаборатории для изучения или изобретения нового лекарства от ожирения исследователи будут сравнивать результаты экспериментального и стандартного лечения. В исследовании ожирения, ценные результаты могут быть получены, когда средний уровень ожирения населения можно сравнить в разных возрастных группах. В этом случае хотелось бы наблюдать средний уровень ожирения среди разных возрастных групп, таких как возраст (от 5 до 18), (19, 35) и (от 36 до 50). Метод ANOVA применяется, поскольку существует более двух независимых групп. Метод ANOVA используется для сравнения среднего ожирения независимых групп. Используется функция aov (), а синтаксис - aov (формула, данные = датафрейм). В этой статье мы узнаем о модели ANOVA, а также обсудим одностороннюю и двустороннюю модель ANOVA вместе с примерами.
Почему ANOVA?
- Этот метод используется для ответа на гипотезу при анализе нескольких групп данных. Существует несколько статистических подходов, однако ANOVA в R применяется, когда сравнение необходимо проводить более чем в двух независимых группах, как в нашем предыдущем примере для трех разных возрастных групп.
- Метод ANOVA измеряет среднее значение независимых групп, чтобы предоставить исследователям результат гипотезы. Для получения точных результатов необходимо учитывать средние значения выборки, размер выборки и стандартное отклонение для каждой отдельной группы.
- Для сравнения можно наблюдать среднее значение для каждой из трех групп. Однако этот подход имеет ограничения и может оказаться неправильным, поскольку эти три сравнения не учитывают суммарные данные и, следовательно, могут привести к ошибке типа 1. R предоставляет нам функцию для проведения анализа ANOVA, чтобы исследовать изменчивость среди независимых групп данных. Существует пять этапов проведения анализа ANOVA. На первом этапе данные располагаются в формате CSV, и столбец генерируется для каждой переменной. Один из столбцов будет зависимой переменной, а остальные будут независимой переменной. На втором этапе данные считываются в R studio и соответствующим образом именуются. На третьем этапе набор данных присоединяется к отдельным переменным и считывается памятью. Наконец, ANOVA в R определяется и анализируется. В следующих разделах я привел несколько примеров из практики, в которых должны использоваться методы ANOVA.
- Шесть инсектицидов были испытаны на 12 полях каждое, и исследователи подсчитали количество ошибок, оставшихся в каждом поле. Теперь фермеры должны знать, имеют ли какое-либо значение инсектициды, и если да, то какой из них лучше всего использовать. Вы отвечаете на этот вопрос, используя функцию aov () для выполнения ANOVA.
- Пятьдесят пациентов получили один из пяти препаратов, снижающих уровень холестерина. Три условия лечения включали один и тот же препарат, который вводили по 20 мг один раз в день (1 раз) по 10 мг два раза в день (2 раза) по 5 мг четыре раза в день (4 раза). Два оставшихся состояния (drugD и drugE) представляли собой конкурирующие лекарства. Какое лекарственное лечение дало наибольшее снижение холестерина (ответ)?
ANOVA в одну сторону
- Односторонний метод является одним из базовых методов ANOVA, в которых применяется дисперсионный анализ и сравнивается среднее значение для нескольких групп населения.
- Односторонний ANOVA получил свое название благодаря доступности односторонних классифицированных данных. В одностороннем ANOVA может быть доступна одна зависимая переменная и одна или несколько независимых переменных.
- Например, мы выполним технику ANOVA для набора данных холестерина. Набор данных состоит из двух переменных trt (которые являются обработками на 5 разных уровнях) и переменных отклика. Независимая переменная - группы медикаментозного лечения, зависимая переменная - означает 2 или более групп ANOVA. Исходя из этих результатов, вы можете подтвердить, что прием 5 мг 4 раза в день лучше, чем прием 20 мг один раз в день. Препарат D обладает лучшими эффектами по сравнению с этим препаратом E
Препарат D обеспечивает лучшие результаты при приеме в дозе 20 мг по сравнению с препаратом E
Использует набор данных холестерина в пакете multcompinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
Тест ANOVA F для лечения (trt) является значимым (p <.0001), подтверждая, что пять обработок
# не все одинаково эффективны.
Резюме (aov_model)
открепление (холестерин)

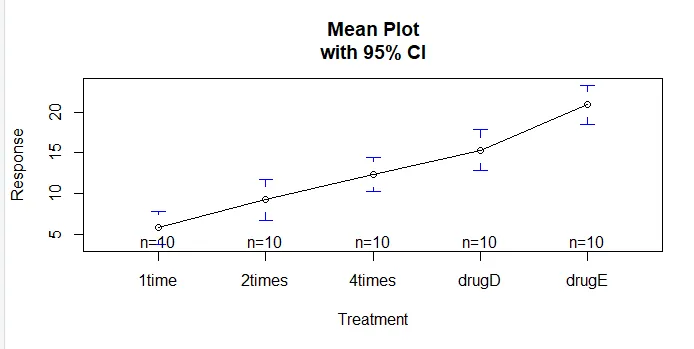
Функция plotmeans () в пакете gplots может быть использована для создания графика средних групп и их доверительных интервалов. Это ясно показывает различия в леченииinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
Давайте рассмотрим выходные данные TukeyHSD () для парных различий между групповыми средними
TukeyHSD (aov_model)
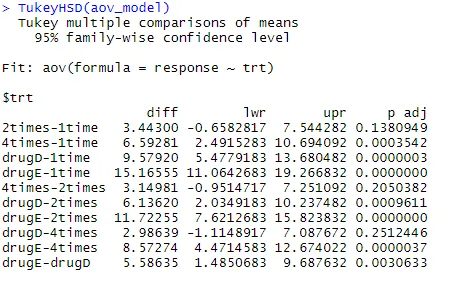
Среднее снижение уровня холестерина за 1 раз и 2 раза достоверно не отличается друг от друга (р = 0, 138), тогда как разница между 1 раз и 4 раза значительно отличается (р <0, 001).
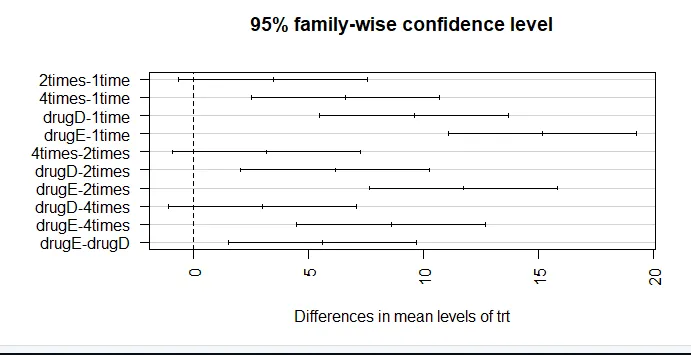
par (mar = c (5, 8, 4, 2)) # увеличение левого поля (TukeyHSD (aov_model), las = 2)
Уверенность в результатах зависит от степени, в которой ваши данные удовлетворяют предположениям, лежащим в основе статистических тестов. В одностороннем ANOVA зависимая переменная считается нормально распределенной и имеет одинаковую дисперсию в каждой группе. Вы можете использовать график QQ для оценки библиотеки предположений о нормальности (автомобиль).
График QQ (лм (отклик ~ trt, данные = холестерин), симуляция = ИСТИНА, основная = «График QQ», метки = ЛОЖЬ)
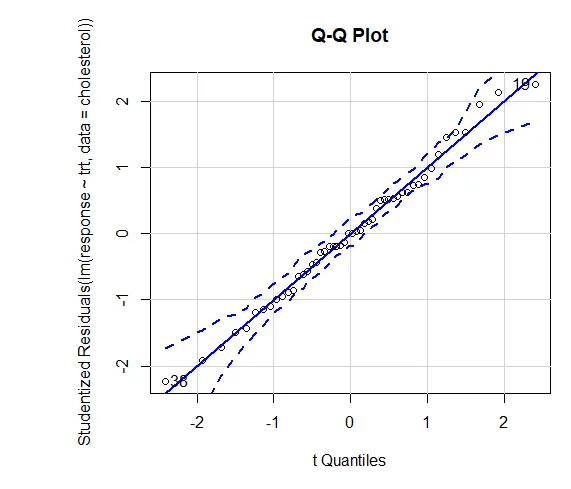
Пунктирная линия = 95% доверительный интервал, свидетельствующий о том, что допущение нормальности было выполнено достаточно хорошо. ANOVA предполагает, что дисперсии равны между группами или выборками. Тест Бартлетта может быть использован для проверки этого предположения
bartlett.test (ответ ~ trt, данные = холестерин). Тест Бартлетта показывает, что дисперсии в пяти группах не отличаются значительно (р = 0, 97).
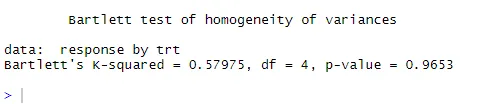
ANOVA также чувствителен к тестам на выбросы с использованием функции outlierTest () в пакете автомобиля. Вам может не понадобиться запускать этот пакет для обновления вашей автомобильной библиотеки.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
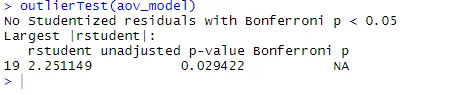
Из полученных результатов видно, что в данных по холестерину нет признаков выбросов (NA возникает, когда p> 1). Если взять график QQ, тест Бартлетта и тест на выбросы вместе, то данные, по-видимому, вполне соответствуют модели ANOVA.
Двухсторонняя анова
Еще одна переменная добавлена в двухстороннем тесте ANOVA. Когда есть две независимые переменные, нам нужно будет использовать двухстороннюю ANOVA, а не одностороннюю технику ANOVA, которая использовалась в предыдущем случае, когда у нас была одна непрерывная зависимая переменная и более одной независимой переменной. Для проверки двустороннего ANOVA необходимо выполнить несколько допущений.
- Наличие независимых наблюдений
- Наблюдения должны быть нормально распределены
- Дисперсия должна быть равной в наблюдениях
- Выбросы не должны присутствовать
- Независимые ошибки
Для проверки двустороннего ANOVA в набор данных добавляется еще одна переменная с именем BP. Переменная указывает уровень артериального давления у пациентов. Мы хотели бы проверить, есть ли статистическая разница между АД и дозировкой, назначаемой пациентам.
df <- read.csv («file.csv»)
Д.Ф.
anova_two_way <- aov (ответ ~ trt + BP, data = df)
Резюме (anova_two_way)
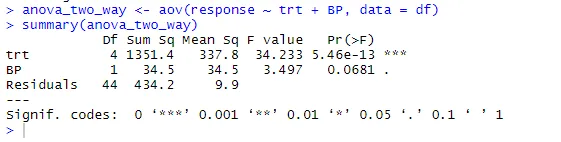
Исходя из результатов, можно сделать вывод, что как trt, так и BP статистически отличаются от 0. Следовательно, гипотеза Null может быть отклонена.
Преимущества ANOVA в R
Тест ANOVA определяет разницу в среднем между двумя или более независимыми группами. Этот метод очень полезен для анализа нескольких товаров, что очень важно для анализа рынка. С помощью теста ANOVA можно получить необходимые данные из данных. Например, во время опроса продукта, где от пользователей собираются различные данные, такие как списки покупок, лайки и антипатии. Тест ANOVA помогает нам сравнивать группы населения. Группой может быть мужчина против женщины или разные возрастные группы. Метод ANOVA помогает различать средние значения разных групп населения, которые действительно различны.
Вывод - ANOVA в R
ANOVA является одним из наиболее часто используемых методов проверки гипотез. В этой статье мы выполнили тест ANOVA на наборе данных, состоящем из пятидесяти пациентов, которые получали медикаментозное лечение, снижающее уровень холестерина, и дополнительно увидели, как можно проводить двухсторонний анализ ANOVA при наличии дополнительной независимой переменной.
Рекомендуемые статьи
Это руководство по ANOVA в R. Здесь мы обсуждаем одностороннюю и двустороннюю модель Anova, а также примеры и преимущества ANOVA. Вы также можете просмотреть наши другие предлагаемые статьи -
- Регрессия против ANOVA
- Что такое SPSS?
- Как интерпретировать результаты с помощью теста ANOVA
- Функции в R