
Что такое GLM в R?
Обобщенные линейные модели являются подмножеством моделей линейной регрессии и эффективно поддерживают ненормальные распределения. Для поддержки этого рекомендуется использовать функцию glm (). GLM хорошо работает с переменной, когда дисперсия не постоянна и распределяется нормально. Функция связи определяется для преобразования переменной отклика в соответствии с подходящей моделью. Модель LM сделана и с семьей и с формулой. Модель GLM имеет три ключевых компонента: случайный (вероятность), систематический (линейный предиктор), компонент связи (для функции логита). Преимущество использования glm заключается в том, что они обладают гибкостью модели, не требуют постоянной дисперсии, и эта модель соответствует оценке максимального правдоподобия и ее отношениям. В этой теме мы собираемся узнать о GLM в R.
Функция GLM
Синтаксис: glm (формула, семейство, данные, веса, подмножество, Start = null, model = TRUE, method = ””…)
Здесь семейные типы (включая типы моделей) включают в себя биномиальное, пуассоновское, гауссовское, гамма, квази. Каждое распределение выполняет различное использование и может использоваться или в классификации и в прогнозировании. И когда модель гауссова, ответ должен быть целым числом.
И когда модель является биномиальной, ответом должны быть классы с двоичными значениями.
И когда модель Пуассона, ответ должен быть неотрицательным с числовым значением.
И когда модель гамма, ответ должен быть положительным числовым значением.
glm.fit () - чтобы соответствовать модели
Lrfit () - обозначает соответствие логистической регрессии.
update () - помогает в обновлении модели.
anova () - это необязательный тест.
Как создать GLM в R?
Здесь мы увидим, как создать простую обобщенную линейную модель с двоичными данными, используя функцию glm (). И, продолжая с набором данных деревьев.
Примеры
// Импорт библиотекиlibrary(dplyr)
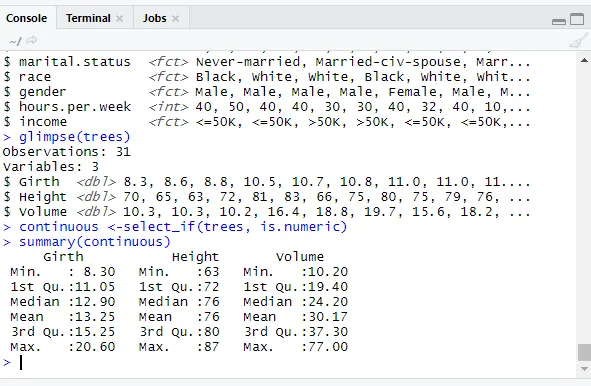
glimpse(trees)

Чтобы увидеть категориальные значения факторов присваиваются.
levels(factor(trees$Girth))
// Проверка непрерывных переменных
library(dplyr)
continuous <-select_if(trees, is.numeric)
summary(continuous)
// Включение набора данных дерева в поиск R Pathattach (деревья)
x<-glm(Volume~Height+Girth)
x
Выход:
| Call: glm (формула = объем ~ высота + обхват)
Коэффициенты: (Перехват) Высота обхвата -57, 9877 0, 3393 4, 7082 Степени свободы: 30 всего (т. Е. Ноль); 28 Остаточный Нулевое отклонение: 8106 Остаточное отклонение: 421, 9 AIC: 176, 9 |
summary(x)
| Вызов:
glm (формула = объем ~ высота + обхват) Остатки отклонения: Мин 1Q Медиана 3Q Макс -6.4065 -2.6493 -0.2876 2.2003 8.4847 Коэффициенты: Оценка Станд. Значение ошибки t Pr (> | t |) (Перехват) -57, 9877 8, 6382 -6, 713 2, 75e-07 *** Высота 0, 3393 0, 1302 2, 607 0, 0145 * Обхват 4, 7082 0, 2643 17, 816 <2e-16 *** - Signif. коды: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0, 1 '' 1 (Параметр дисперсии для семейства гауссов принят равным 15, 06862) Нулевое отклонение: 8106, 08 на 30 степенях свободы Остаточное отклонение: 421, 92 на 28 степеней свободы AIC: 176, 91 Количество итераций Фишера: 2 |
Выходные данные функции суммирования выдают вызовы, коэффициенты и остатки. Приведенный выше ответ показывает, что как коэффициент роста, так и коэффициент обхвата незначительны, поскольку вероятность их составляет менее 0, 5. И есть два варианта отклонения, называемые нулевым и остаточным. Наконец, оценка Фишера - это алгоритм, который решает проблемы максимального правдоподобия. С биномиальным ответом является вектор или матрица. cbind () используется для связывания векторов столбцов в матрице. И чтобы получить подробную информацию о подгонке резюме используется.
Чтобы выполнить тест Like Hood, выполняется следующий код.
step(x, test="LRT")
Start: AIC=176.91
Volume ~ Height + Girth
Df Deviance AIC scaled dev. Pr(>Chi)
421.9 176.91
- Height 1 524.3 181.65 6.735 0.009455 **
- Girth 1 5204.9 252.80 77.889 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Call: glm(formula = Volume ~ Height + Girth)
Coefficients:
(Intercept) Height Girth
-57.9877 0.3393 4.7082
Degrees of Freedom: 30 Total (ie Null); 28 Residual
Null Deviance: 8106
Residual Deviance: 421.9 AIC: 176.9
Модель подходит
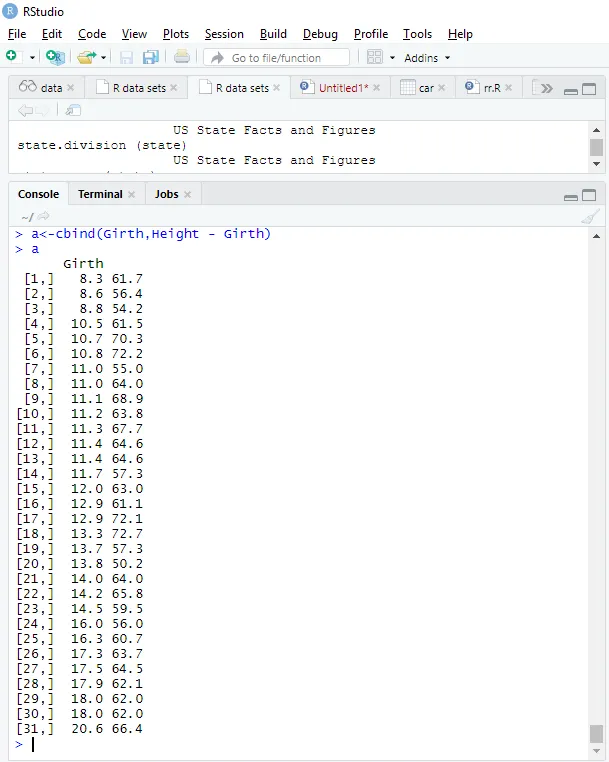
a<-cbind(Height, Girth - Height)
> a
резюме (деревья)
Girth Height Volume
Min. : 8.30 Min. :63 Min. :10.20
1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40
Median :12.90 Median :76 Median :24.20
Mean :13.25 Mean :76 Mean :30.17
3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30
Max. :20.60 Max. :87 Max. :77.00
Чтобы получить соответствующее стандартное отклонение
apply(trees, sd)
Girth Height Volume
3.138139 6.371813 16.437846
predict <- predict(logit, data_test, type = 'response')
Далее мы ссылаемся на переменную count count, чтобы смоделировать хорошее соответствие ответа. Чтобы вычислить это, мы будем использовать набор данных USAccDeath.
Давайте введем следующие фрагменты в консоль R и посмотрим, как для них выполняется подсчет года и годовой квадрат.
data("USAccDeaths")
force(USAccDeaths)
// Проанализировать год с 1973-1978.
disc <- data.frame(count=as.numeric(USAccDeaths), year=seq(0, (length(USAccDeaths)-1), 1)))
yearSqr=disc$year^2
a1 <- glm(count~year+yearSqr, family="poisson", data=disc)
summary(a1)
| Вызов:
glm (формула = число ~ год + годSqr, семья = "пуассон", данные = диск) Остатки отклонения: Мин 1Q Медиана 3Q Макс -22, 4344 -6, 4401 -0, 0981 6, 0508 21, 4578 Коэффициенты: Оценка Станд. Значение ошибки z Pr (> | z |) (Перехват) 9, 187e + 00 3, 555e-03 2582, 49 <2e-16 *** год -7.207e-03 2.354e-04 -30.62 <2e-16 *** yearSqr 8, 841e-05 3, 221e-06 27, 45 <2e-16 *** - Signif. коды: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0, 1 '' 1 (Параметр дисперсии для семейства Пуассона принят за 1) Нулевое отклонение: 7357, 4 на 71 степени свободы Остаточное отклонение: 6358, 0 на 69 степенях свободы AIC: 7149, 8 Количество итераций Фишера: 4 |
Чтобы проверить наилучшее соответствие модели, можно использовать следующую команду, чтобы найти
остатки для теста. Из приведенного ниже результата значение равно 0.
1 - pchisq(deviance(a1), df.residual(a1))
Использование семейства QuasiPoisson для большей дисперсии в данных
a2 <- glm(count~year+yearSqr, family="quasipoisson", data=disc)
summary(a2)
| Вызов:
glm (формула = число ~ год + годSqr, семья = "квазипуассон", данные = диск) Остатки отклонения: Мин 1Q Медиана 3Q Макс -22, 4344 -6, 4401 -0, 0981 6, 0508 21, 4578 Коэффициенты: Оценка Станд. Значение ошибки t Pr (> | t |) (Перехват) 9.187e + 00 3.417e-02 268.822 <2e-16 *** год -7.207e-03 2.261e-03 -3.188 0, 00216 ** yearSqr 8, 841e-05 3, 095e-05 2, 857 0, 00565 ** - (Параметр дисперсии для семейства квазипуассонов принят за 92, 28857) Нулевое отклонение: 7357, 4 на 71 степени свободы Остаточное отклонение: 6358, 0 на 69 степенях свободы AIC: NA Количество итераций Фишера: 4 |
Сравнение Пуассона с биномиальным значением AIC существенно отличается. Они могут быть проанализированы по точности и коэффициенту возврата. Следующим шагом является проверка отклонения остатков пропорционально среднему значению. Затем мы можем построить график с использованием библиотеки ROCR для улучшения модели.
Вывод
Поэтому мы сосредоточились на специальной модели, называемой обобщенной линейной моделью, которая помогает фокусировать и оценивать параметры модели. Это прежде всего потенциал для переменной непрерывного отклика. И мы увидели, как glm подходит для встроенных пакетов R. Они являются наиболее популярными подходами для измерения данных подсчета и надежным инструментом для методов классификации, используемых ученым. Язык R, конечно, помогает в выполнении сложных математических функций
Рекомендуемые статьи
Это руководство по GLM в R. Здесь мы обсуждаем функцию GLM и Как создать GLM в R с примерами наборов данных дерева и выходными данными. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Язык программирования R
- Архитектура больших данных
- Логистическая регрессия в R
- Аналитика больших данных
- Пуассоновская регрессия в R | Реализация пуассоновской регрессии