
Структуры данных и алгоритмы C ++
Структуры данных и алгоритмы C ++ - означает упорядочивание или организацию элементов определенным образом. Когда мы говорим, что мы должны упорядочить элементы, эти элементы могут быть организованы в разных формах. Например, носки могут быть расположены по-разному. Вы можете просто держать это в своем буфете, все испорчено. Или вы можете держать его аккуратно сложенным. Лучше всего складывать и расставлять их по цвету. Так что для поиска конкретной пары носков третье устройство идеально подходит.
Аналогично организации носков, Данные могут быть организованы по-разному или в разных формах. Эти различные способы организации данных называются структура данных. Давайте посмотрим формальное определение структуры данных и структуры данных и основы алгоритмов.
Структуры данных и алгоритмы C ++:
Логическая или математическая модель конкретной организации данных.
ИЛИ
Это особый способ организации данных на компьютере, чтобы их можно было использовать.
Аналогично носкам; различная организация структур данных списков и алгоритмы C ++ доступны для -
- массив
- Связанный список
- стек
- Очередь
- дерево
- график
- Хеш-таблица
- отвал
- документация
- таблицы
Эти структуры данных и алгоритмы C ++ очень важны при программировании. Хороший программист всегда делает упор на структуру данных, а не код. Каждый язык программирования работает с различными структурами данных и алгоритмами на C ++. Структуры данных, доступные в C ++, следующие.
- массив
- Связанный список
- стек
- Очередь
- дерево
- график
- Хеш-таблица
- отвал
Давайте обсудим это один за другим:
Массив # 1
Массив - это самый простой тип структур данных и алгоритмов C ++. Массив определяется как последовательная коллекция фиксированного размера элементов данных того же типа данных. Например, a0 = 12, a1 = 21, a2 = 14, a3 = 15…. Мы можем представить одномерный массив, как показано на рисунке:
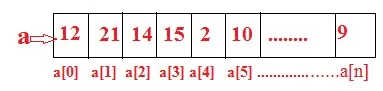
где
0, 1, 2, 3… ..n называется индекс или индекс
a (1), a (2), … a (n) называется индексной переменной
Это может быть 1-мерный, 2-мерный, 3-мерный и т. Д. Многомерный.
В памяти массив хранится в смежных местах памяти.
Самый низкий адрес соответствует первому элементу
Самый высокий адрес соответствует последнему элементу
Мы можем объявить одномерный (1-мерный) массив в C ++ следующим образом
dataType arrayName (arraySize);
Например, int num (5);
Инициализация массива в C ++
num = (23, 10, 12, 3, 6);
Мы можем объединить объявление и инициализацию в одно утверждение следующим образом.
int num = (23, 10, 12, 3, 6);
Когда мы хотим динамически распределить размер массива, мы должны использовать новый оператор следующим образом
int * a = new int (size);
Недостатком массива являются вставка и удаление элементов, медленное как в упорядоченном массиве, так и в его хранилище фиксированного размера.
# 2 Связанный список
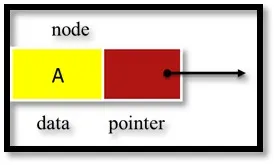
Список относится к линейной коллекции предметов. Связанный список представляет собой серию связанных узлов (элемент данных), как показано на рисунке 3. Узел заголовка указывает на первый узел списка, а последний узел указывает на NULL, обозначенный как Æ. Поскольку каждый узел содержит как минимум.
- Часть данных (любой тип)
- Указатель на следующий узел в списке
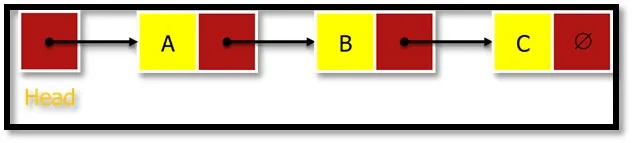
Связанный список представлен в памяти с использованием двух массивов. Один массив хранит информацию, называемую информацией, которая представляет собой данные, которые должны быть сохранены, а другой хранит поле следующего указателя, называемое LINK, которое является адресом следующего узла.
Преимущество связанного списка над массивом:
И массив, и связанный список являются представлениями списка элементов в памяти. Важным отличием является то, как предметы связаны друг с другом. Основным ограничением массива является вставка элемента в массив, а удаление элемента из упорядоченного массива затруднено, так как остальные элементы должны быть перемещены. Вставка и удаление элементов из связанного списка очень просты.
Научитесь разрабатывать и настраивать программы для различных платформ. Кодируйте, тестируйте, отлаживайте и внедряйте программные приложения. Развивайте навыки для обеспечения бесперебойной работы приложений.
Типы связанного списка:
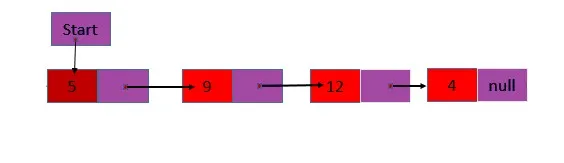
1. Односвязный список : содержит только одно связанное поле, которое содержит адрес следующего узла в списке, и поле информации, содержащее информацию, подлежащую сохранению.
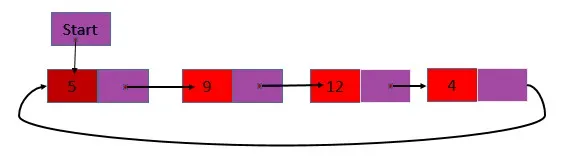
2. Одиночный круговой связанный список является только одним списком, но последний узел списка содержит адрес первого узла вместо нуля. То есть содержимое заголовка и следующего поля последнего узла совпадают.
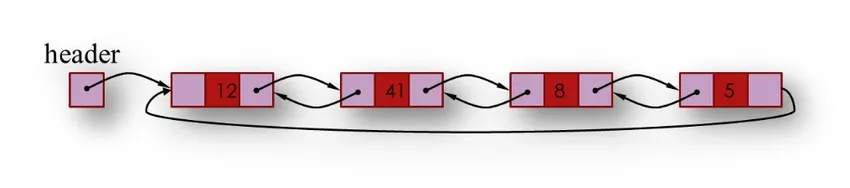
3. Двусвязный список содержит два связанных поля предыдущего и следующего. Ранее связанное поле, которое содержит адрес предыдущего узла в списке, а следующее связанное поле содержит адрес следующего узла в списке, а в поле информации хранится информация для хранения.

4. Двойной круговой связанный список - это дважды связанный список, но следующее поле последнего узла содержит адрес первого узла вместо нуля.
Рекомендуемые курсы
- Курс на VB.NET
- Обучение программированию данных
- Интернет курс ISTQB
- Kali Linux Учебный курс
Реализация связанного списка в C ++ включает создание узла, удаление узла из списка, вставку вновь созданного узла в список и поиск узла с определенным ключом.
Код для создания узла выдается следующим образом:

Вставка узла в список включает три случая
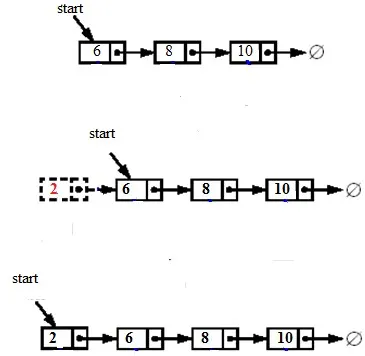
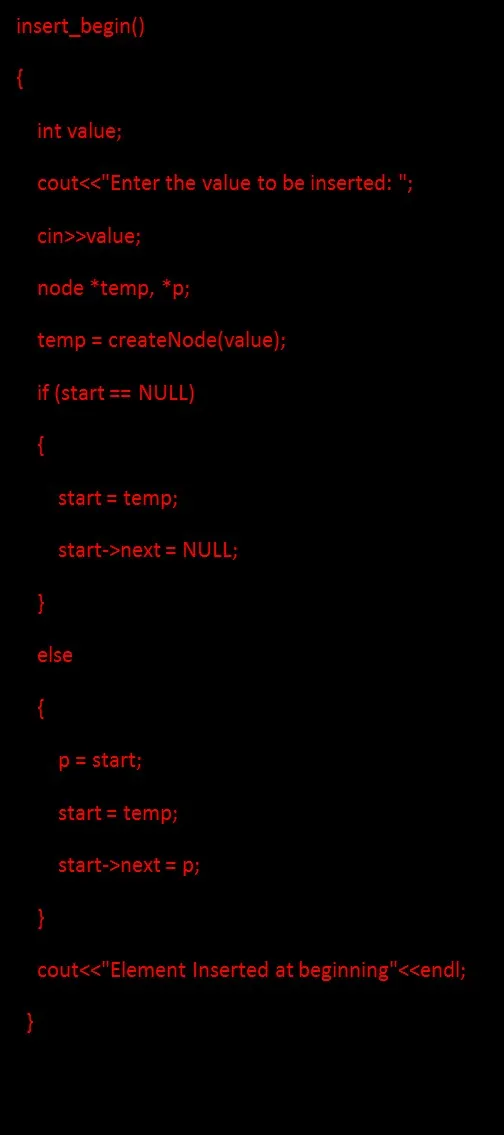
1. Вставка узла в начале означает вставку вновь созданного узла в качестве начального узла. Для вставки узла в начале сначала создайте новый узел и сделайте так, чтобы новый узел указывал на старое начало, а затем обновите начало, чтобы указать на новый узел, как показано на рисунке ниже:
Код для вставки узла в начале:
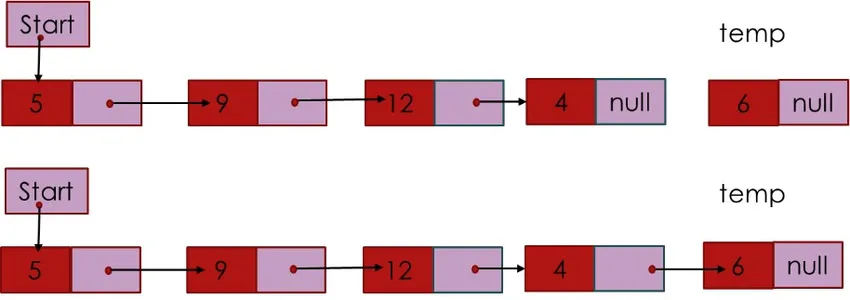
2. Вставка узла в хвост означает вставку вновь созданного узла в качестве последнего узла. Для вставки узла в качестве хвостового узла необходимо создать новый узел и сделать так, чтобы старый последний узел указывал на новый узел, а затем обновлять хвост, чтобы он указывал на новый узел.
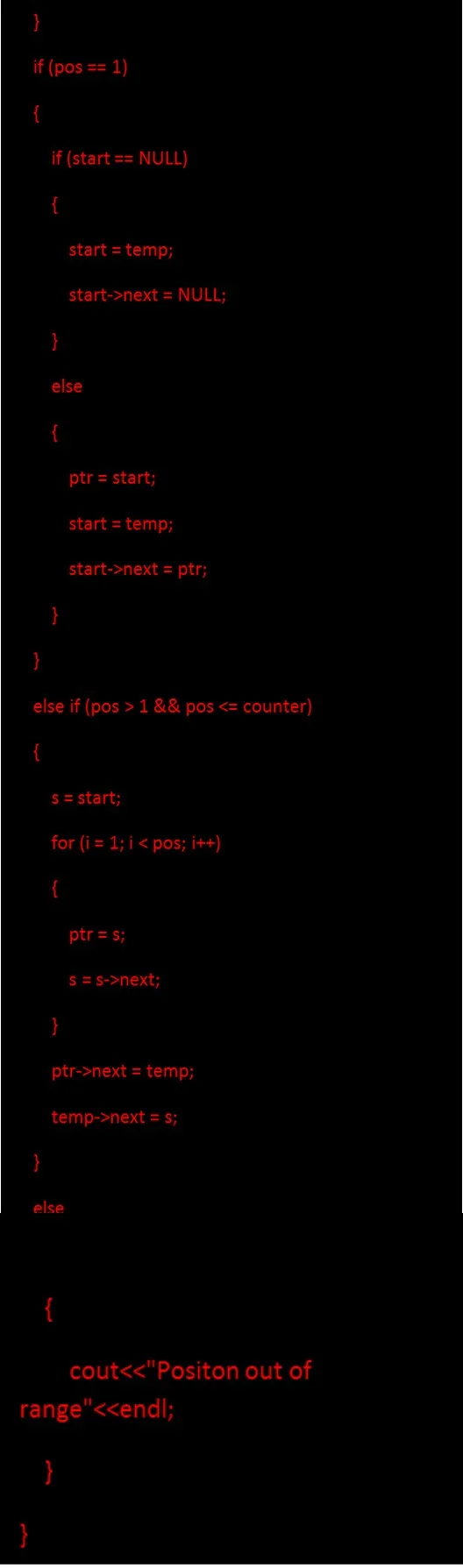
3. Вставка узла в заданную позицию включает в себя создание нового временного узла, затем необходимо найти позицию вставки вновь созданного узла.
Код для вставки узла в заданную позицию:

Удаление узла из списка включает в себя удаление узла из существующего списка. Удаление узла из списка ссылок проще, чем вставка узла в список. В C ++ код для удаления узла выдается следующим образом:

Обход узла с определенным ключом (значением) из списка будет искать узел из списка, информация которого будет совпадать с ключом данного узла. Следующий код C ++ будет проходить по списку. структуры данных и алгоритмы C ++


# 3 Стек
Стек - это список элементов, в которые элемент может быть вставлен или удален только на одном конце, называемом вершиной стека. Рассмотрим пример башни Ханоя. Здесь, когда нам нужно вставить диск, мы должны вставить его только сверху, и аналогично извлечение диска происходит только сверху.
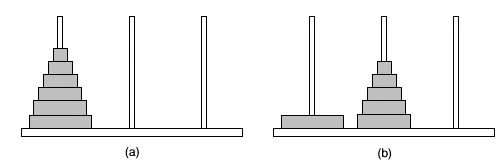
Стек использует принцип LIFO, что означает, что он работает в порядке «последний пришел первым». То есть последний элемент, добавленный в стек, является первым элементом удаления. Таким образом, в стеке можно выполнить четыре основные операции:
- Isempty: эта операция определяет, пуст ли стек.
- Push : эта операция добавляет новый элемент в стек.
- Pop: эта операция удаляет элемент из стека, добавленный последним.
- Вверх: Эта операция возвращает элемент, который был добавлен в стек за последнее время.
На следующем рисунке приведен пример стека, в котором вставка в стек и удаление из стека элемента происходит с вершины стека и нигде больше.
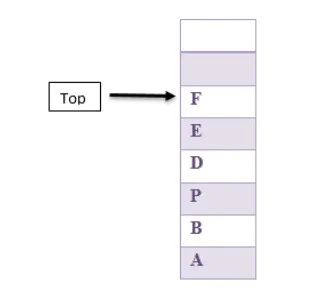
Переполнение стека
Условие, возникающее в результате попытки поместить элемент в полный стек.
Стека стека
Условие, возникающее в результате попытки выгрузить пустой стек.
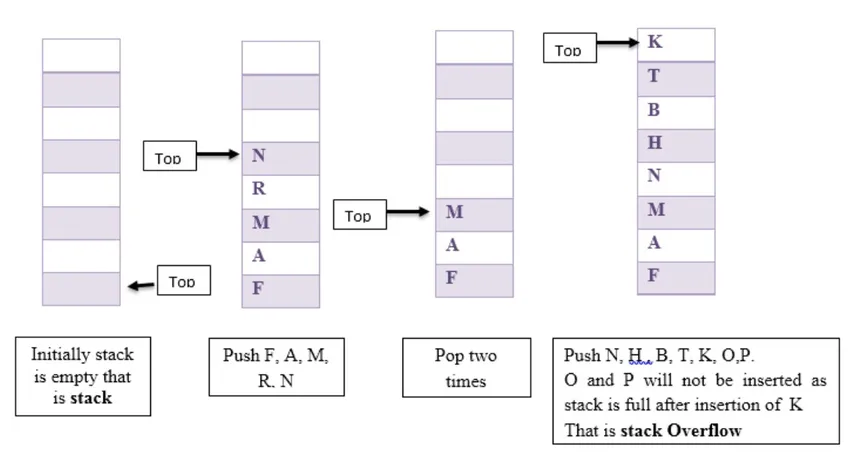
Здесь мы показали некоторые операции push и pop в стеке. Предположим, что изначально стек пуст, затем мы добавили F, A, M, R, N. Затем вытолкните два раза и нажмите N, H, B, T, K, O, P.
Реализация стека:
Это может быть реализовано с использованием массива или связанного списка обоих.
Следующий приведенный код показывает, как стек реализован в C ++ с использованием Class. Здесь мы определили один класс с именем стека, в котором создан массив с именем stick с динамическим размером и две основные функции push и pop.
Переполнение стека: Когда вершина> = размер-1
Недостаточность стека: когда вершина <0

Статьи по Теме:-
Вот несколько статей, связанных со структурами данных и алгоритмами C ++, которые помогут вам получить более подробную информацию об Алгоритмах C ++ и структурах данных и алгоритмах, поэтому любезно перейдите по ссылке, приведенной ниже. если вам нравятся статьи структуры данных и алгоритмы C ++, тогда дайте нам ваш ценный комментарий.
- Шпаргалка для языка программирования C ++
- Linux против Ubuntu
- C ++ Интервью Вопросы, которые вы должны знать
- Структуры данных и алгоритмы Вопросы для интервью | Наиболее полезный
- Лучшая статья по алгоритмам и криптографии (примеры)
- 8 Потрясающий Алгоритм Интервью Вопросы и Ответы
- Удивительное руководство по Kali Linux vs Ubuntu
- C ++ Vector vs Array: Каковы лучшие функции