
Введение в модели машинного обучения
Обзор различных моделей машинного обучения, используемых на практике. Согласно определению, модель машинного обучения - это математическая конфигурация, полученная после применения определенных методологий машинного обучения. Используя широкий спектр API-интерфейсов, построение модели машинного обучения в настоящее время довольно просто с меньшим количеством строк кода. Но настоящий навык специалиста в области прикладных данных заключается в выборе правильной модели, основанной на постановке задачи и перекрестной проверке, а не в случайном выбрасывании данных в причудливые алгоритмы. В этой статье мы обсудим различные модели машинного обучения и способы их эффективного использования в зависимости от типа проблем, которые они решают.
Типы моделей машинного обучения
На основе типа задач мы можем классифицировать модели машинного обучения по следующим типам:
- Модели классификации
- Модели регрессии
- Кластеризация
- Уменьшение размерности
- Глубокое обучение и т. Д.
1) Классификация
Что касается машинного обучения, классификация - это задача прогнозирования типа или класса объекта в пределах конечного числа вариантов. Выходная переменная для классификации всегда является категориальной переменной. Например, прогнозирование того, является ли электронная почта спамом или нет, является стандартной задачей двоичной классификации. Теперь давайте отметим некоторые важные модели для задач классификации.
- Алгоритм K-ближайших соседей - простой, но вычислительно исчерпывающий.
- Наивный байесовский - на основе теоремы Байеса.
- Логистическая регрессия - линейная модель для двоичной классификации.
- SVM - может использоваться для бинарных / мультиклассовых классификаций.
- Дерево решений - классификатор на основе « если нет », более устойчивый к выбросам.
- Ансамбли - Сочетание нескольких моделей машинного обучения, объединенных для получения лучших результатов.
2) Регрессия
В машине регрессия обучения представляет собой набор проблем, где выходная переменная может принимать непрерывные значения. Например, прогнозирование цены авиакомпании может рассматриваться как стандартная задача регрессии. Давайте отметим некоторые важные регрессионные модели, используемые на практике.
- Линейная регрессия - Простейшая базовая модель для задачи регрессии, которая хорошо работает только тогда, когда данные линейно разделимы, а мультиколлинеарность очень мала или отсутствует.
- Регрессия Лассо - Линейная регрессия с регуляризацией L2.
- Ridge Regression - Линейная регрессия с регуляризацией L1.
- SVM регрессия
- Регресс дерева решений и т. Д.
3) кластеризация
Проще говоря, кластеризация - это задача группировки похожих объектов. Модели машинного обучения помогают идентифицировать подобные объекты автоматически без ручного вмешательства. Мы не можем построить эффективные контролируемые модели машинного обучения (модели, которые необходимо обучать с использованием данных, отобранных вручную или помеченных) без однородных данных. Кластеризация помогает нам достичь этого более разумным способом. Ниже приведены некоторые из широко используемых моделей кластеризации:
- К означает - простой, но страдает от высокой дисперсии.
- K означает ++ - модифицированная версия K означает.
- К медоидам.
- Агломерационная кластеризация - иерархическая модель кластеризации.
- DBSCAN - алгоритм кластеризации по плотности и т. Д.
4) Уменьшение размерности
Размерность - это число переменных-предикторов, используемых для прогнозирования независимой переменной или цели. Часто в наборах данных реального мира количество переменных слишком велико. Слишком много переменных также приносят проклятие подгонки к моделям. На практике среди этих большого числа переменных не все переменные вносят одинаковый вклад в достижение цели, и в большом количестве случаев мы можем фактически сохранить отклонения с меньшим числом переменных. Давайте перечислим некоторые часто используемые модели для уменьшения размерности.
- PCA - создает большое количество новых переменных из большого числа предикторов. Новые переменные не зависят друг от друга, но менее интерпретируемы.
- TSNE - обеспечивает низкоразмерное вложение многомерных точек данных.
- SVD - Разложение по сингулярным значениям используется для разложения матрицы на более мелкие части с целью эффективного расчета.
5) глубокое обучение
Глубокое обучение - это подмножество машинного обучения, которое имеет дело с нейронными сетями. Основываясь на архитектуре нейронных сетей, давайте перечислим важные модели глубокого обучения:
- Многослойный персептрон
- Сверточные нейронные сети
- Рекуррентные нейронные сети
- Машина Больцмана
- Автоэнкодеры и др.
Какая модель самая лучшая?
Выше мы взяли идеи о множестве моделей машинного обучения. Теперь у нас возникает очевидный вопрос: «Какая из них лучшая модель?» Это зависит от рассматриваемой проблемы и других связанных атрибутов, таких как выбросы, объем доступных данных, качество данных, разработка функций и т. Д. На практике всегда предпочтительно начинать с самой простой модели, применимой к проблеме, и увеличивать сложность. постепенно путем правильной настройки параметров и перекрестной проверки. В мире науки о данных существует пословица: «Перекрестная проверка достовернее, чем знание предметной области».
Как построить модель?
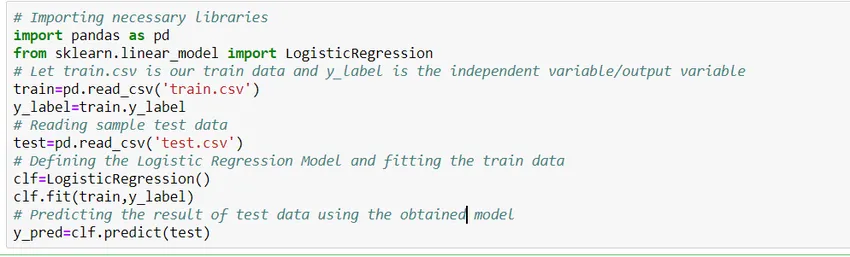
Давайте посмотрим, как построить простую модель логистической регрессии с использованием библиотеки Python Scikit Learn. Для простоты мы предполагаем, что проблема - это стандартная классификационная модель, а train.csv - поезд, а test.csv - поезд и тестовые данные соответственно.
Вывод
В этой статье мы обсудили важные модели машинного обучения, используемые в практических целях, и способы построения простой модели машинного обучения в python. Выбор подходящей модели для конкретного варианта использования очень важен для получения правильного результата задачи машинного обучения. Для сравнения производительности между различными моделями определяются метрики оценки или KPI для конкретных бизнес-задач, и наилучшая модель выбирается для производства после применения статистической проверки производительности.
Рекомендуемые статьи
Это руководство по моделям машинного обучения. Здесь мы обсуждаем 5 лучших типов машинного обучения с его определением. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Методы машинного обучения
- Типы машинного обучения
- Алгоритмы машинного обучения
- Что такое машинное обучение?
- Гиперпараметр машинного обучения
- KPI в Power BI
- Иерархический кластерный алгоритм
- Иерархическая кластеризация | Агломерационная и разделительная кластеризация