

Введение в Join в Spark SQL
Как мы знаем, объединения в SQL используются для объединения данных или строк из двух или более таблиц на основе общего поля между ними. В этой теме мы не узнаем о Join в Spark SQL Join в Spark SQL.
В Spark SQL Dataframe или Dataset представляют собой табличную структуру в памяти, имеющую строки и столбцы, которые распределены по нескольким узлам. Как и обычные таблицы SQL, мы также можем выполнять операции соединения на Dataframe или наборе данных в Spark SQL на основе общего поля между ними.
Существуют различные типы операций объединения, доступных в SQL. В зависимости от бизнес-случая мы выбираем операцию соединения. В следующем разделе мы собираемся продемонстрировать каждый тип объединения с примером.
Типы объединения в Spark SQL
Ниже приведены различные типы объединений, доступных в Spark SQL:
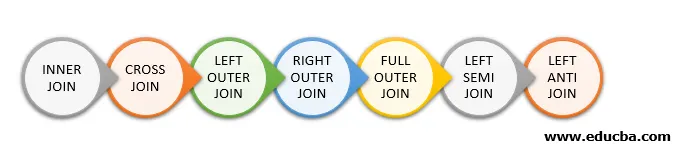
- ВНУТРЕННЕЕ СОЕДИНЕНИЕ
- CROSS JOIN
- ЛЕВОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
- ПРАВО НАРУЖНОЕ
- ПОЛНОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
- ЛЕВАЯ ПОЛУЗАПИСЬ
- ЛЕВЫЙ АНТИ СОЕДИНЕНИЕ
Пример создания данных
Мы будем использовать следующие данные для демонстрации различных типов объединений:
Набор данных книги:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Набор данных Writer:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Типы соединений
Ниже перечислены 7 различных типов соединений:
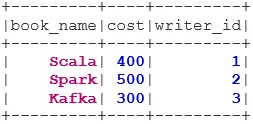
1. ВНУТРЕННИЕ СОЕДИНЕНИЯ
INNER JOIN возвращает набор данных, в котором есть строки с совпадающими значениями в обоих наборах данных, т.е. значение общего поля будет одинаковым.
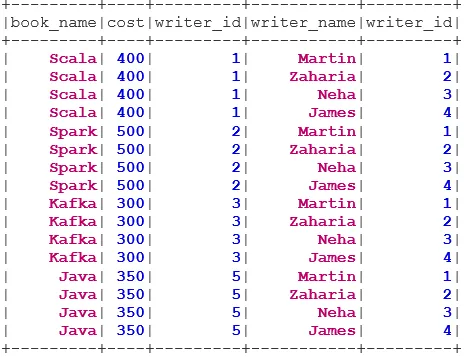
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS JOIN
CROSS JOIN возвращает набор данных, который представляет собой количество строк в первом наборе данных, умноженное на количество строк во втором наборе данных. Такой результат называется декартовым произведением.
Предварительное условие: для использования перекрестного соединения для spark.sql.crossJoin.enabled должно быть установлено значение true. В противном случае будет сгенерировано исключение.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. ЛЕВОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
LEFT OUTER JOIN возвращает набор данных, в котором есть все строки из левого набора данных, и совпадающие строки из правого набора данных.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. ПРАВО НАРУЖНОЕ СОЕДИНЕНИЕ
RIGHT OUTER JOIN возвращает набор данных, в котором есть все строки из правого набора данных, и совпадающие строки из левого набора данных.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. ПОЛНОЕ НАРУЖНОЕ СОЕДИНЕНИЕ
FULL OUTER JOIN возвращает набор данных, в котором есть все строки, если есть совпадение в левом или правом наборе данных.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. ЛЕВАЯ ПОЛУЗАПИСЬ
LEFT SEMI JOIN возвращает набор данных, в котором все строки из левого набора данных имеют свои соответствия в правом наборе данных. В отличие от LEFT OUTER JOIN, возвращенный набор данных в LEFT SEMI JOIN содержит только столбцы из левого набора данных.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. ЛЕВЫЙ АНТИ ПРИСОЕДИНЯЙТЕСЬ
ANTI SEMI JOIN возвращает набор данных, в котором есть все строки из левого набора данных, у которых нет соответствия в правом наборе данных. Он также содержит только столбцы из левого набора данных.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Вывод - присоединяйтесь в Spark SQL
Объединение данных является одной из наиболее распространенных и важных операций для выполнения нашего бизнес-сценария. Spark SQL поддерживает все основные типы объединений. При присоединении мы также должны учитывать производительность, поскольку для этого могут потребоваться большие передачи по сети или даже создание наборов данных за пределами нашей способности обрабатывать. Для повышения производительности Spark использует оптимизатор SQL для изменения порядка или установки фильтров. Spark также ограничивает опасное соединение i. e CROSS JOIN. Для использования перекрестного соединения для spark.sql.crossJoin.enabled должно быть явно задано значение true.
Рекомендуемые статьи
Это руководство по присоединению к Spark SQL. Здесь мы обсуждаем различные типы соединений, доступных в Spark SQL, с примером. Вы также можете посмотреть на следующую статью.
- Типы объединений в SQL
- Таблица в SQL
- SQL Вставить Запрос
- Транзакции в SQL
- PHP фильтры | Как проверить пользовательский ввод с использованием различных фильтров?