

Введение в анализ линейной регрессии
Часто бывает сложно понять какую-то концепцию, которая даже является частью нашей повседневной жизни. Но это не проблема, мы можем помочь и развить себя, чтобы извлечь уроки из нашей повседневной деятельности, просто анализируя вещи и не боясь задавать вопросы. Почему цена влияет на спрос на товары, почему изменение процентной ставки влияет на предложение денег. На все это можно ответить простым подходом, известным как линейная регрессия. Единственная сложность, которую испытывают при работе с линейным регрессионным анализом, - это определение зависимых и независимых переменных.
Мы должны найти то, что влияет на что, и половина проблемы решена. Мы должны увидеть, влияет ли цена или спрос на поведение друг друга. Как только мы узнали, какая из них является независимой переменной и зависимой переменной, мы можем приступить к нашему анализу. Существует несколько типов регрессионного анализа. Этот анализ зависит от доступных нам переменных.
3 типа регрессионного анализа
Эти три регрессионных анализа имеют максимальные варианты использования в реальном мире, в противном случае существует более 15 типов регрессионного анализа. Типы регрессионного анализа, которые мы собираемся обсудить:
- Линейный регрессионный анализ
- Анализ множественной линейной регрессии
- Логистическая регрессия
В этой статье мы сосредоточимся на анализе простой линейной регрессии. Этот анализ помогает нам определить взаимосвязь между независимым фактором и зависимым фактором. Проще говоря, модель регрессии помогает нам понять, как изменения в независимом факторе влияют на зависимый фактор. Эта модель помогает нам несколькими способами, такими как:
- Это простая и мощная статистическая модель
- Это поможет нам сделать прогноз и прогноз
- Это поможет нам принять лучшее деловое решение
- Это поможет нам проанализировать результаты и исправить ошибки
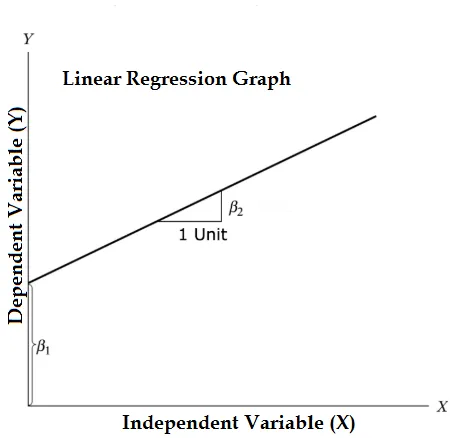
Уравнение линейной регрессии и разбить его на соответствующие части
Y = β1 + β2X + ϵ
- Где β1 в математической терминологии известен как перехват и β2 в математической терминологии известен как наклон. Они также известны как коэффициенты регрессии. term - это ошибка, это часть Y, которую регрессионная модель не может объяснить.
- Y является зависимой переменной (другими терминами, которые взаимозаменяемо используются для зависимых переменных, являются переменная отклика, регрессия, измеренная переменная, наблюдаемая переменная, ответная переменная, объясненная переменная, переменная результата, экспериментальная переменная и / или выходная переменная).
- X является независимой переменной (регрессоры, управляемая переменная, манипулируемая переменная, пояснительная переменная, переменная воздействия и / или входная переменная).
Проблема: Для понимания, что такое линейный регрессионный анализ, мы берем набор данных «Cars», который по умолчанию входит в каталоги R. В этом наборе данных имеется 50 наблюдений (в основном строки) и 2 переменные (столбцы). Названия столбцов: «Dist» и «Speed». Здесь мы должны увидеть влияние на переменные расстояния из-за изменения переменных скорости. Чтобы увидеть структуру данных, мы можем запустить код Str (набор данных). Этот код помогает нам понять структуру набора данных. Эти функциональные возможности помогают нам принимать более правильные решения, поскольку мы лучше понимаем структуру набора данных. Этот код помогает нам определить тип наборов данных.
Код:

Аналогично, для проверки контрольных точек статистики набора данных мы можем использовать код Summary (cars). Этот Код предоставляет средний, средний, диапазон набора данных на ходу, который исследователь может использовать при решении проблемы.
Выход:
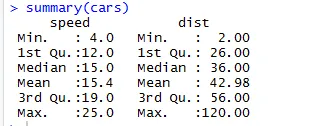
Здесь мы можем увидеть статистический вывод каждой переменной в нашем наборе данных.
Графическое представление наборов данных
Типы графического представления, которые будут охватывать здесь, и почему:
- Диаграмма рассеяния: с помощью графика мы можем видеть, в каком направлении движется наша модель линейной регрессии, есть ли убедительные доказательства, подтверждающие нашу модель, или нет.
- Box Box: Помогает нам найти выбросы.
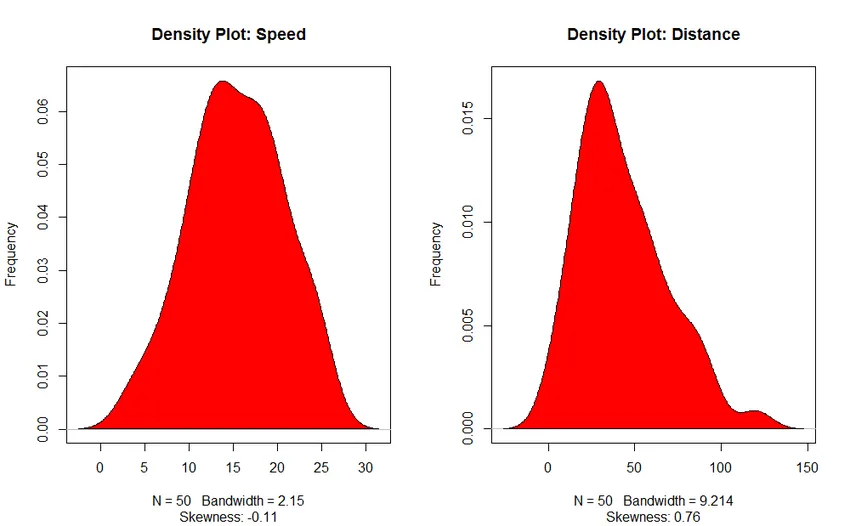
- График плотности: Помогите нам понять распределение независимой переменной, в нашем случае независимой переменной является «Скорость».
Преимущества графического представления
Вот следующие преимущества:
- Легко понять
- Помогает нам принять быстрое решение
- Сравнительный анализ
- Меньше усилий и времени
1. График рассеяния: он поможет визуализировать любые отношения между независимой переменной и зависимой переменной.
Код:

Выход:
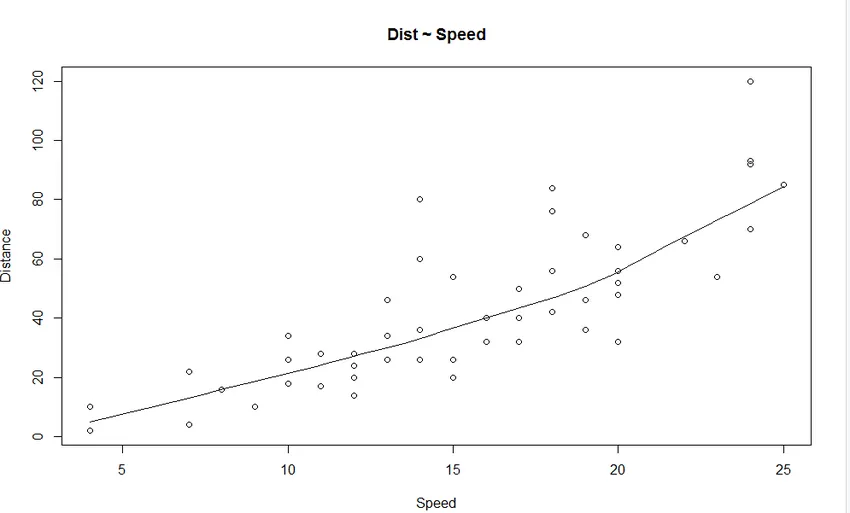
Мы можем видеть на графике линейно возрастающую зависимость между зависимой переменной (Distance) и независимой переменной (Speed).
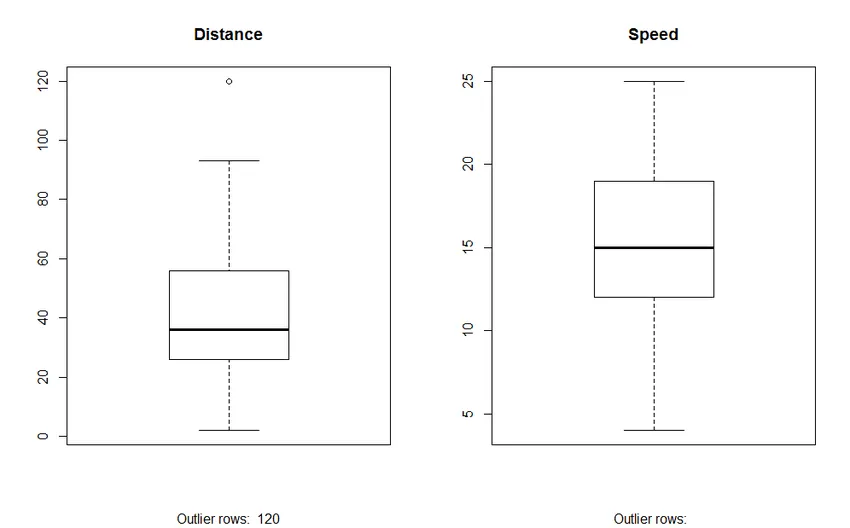
2. График Box: График Box помогает нам идентифицировать выбросы в наборах данных. Преимущества использования блочного участка:
- Графическое отображение местоположения и распространения переменных.
- Это помогает нам понять асимметрию и симметрию данных.
Код:

Выход:
3. График плотности (для проверки нормальности распределения)
Код:
 Выход:
Выход:
Корреляционный анализ
Этот анализ помогает нам найти связь между переменными. Существует в основном шесть видов корреляционного анализа.
- Положительная корреляция (от 0, 01 до 0, 99)
- Отрицательная корреляция (от -0, 99 до -0, 01)
- Нет корреляции
- Идеальная корреляция
- Сильная корреляция (значение ближе к ± 0, 99)
- Слабая корреляция (значение ближе к 0)
Точечная диаграмма помогает нам определить, какие типы наборов данных корреляции среди них есть, и код для нахождения корреляции

Выход:
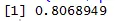
Здесь мы имеем сильную положительную корреляцию между скоростью и расстоянием, что означает, что они имеют прямую связь между ними.
Модель линейной регрессии
Это ключевой компонент анализа, ранее мы просто пытались и проверяли, достаточно ли логичен набор данных, который у нас есть, для проведения такого анализа или нет. Функцией, которую мы планируем использовать, является lm (). Эта функция содержит два элемента: Формула и Данные. Прежде чем присваивать то, какая переменная является зависимой или независимой, мы должны быть очень уверены в этом, потому что вся наша формула зависит от этого.
Формула выглядит так,
Линейная регрессия <- lm (зависимая переменная ~ независимая переменная, data = Date.Frame)
Код:

Выход:
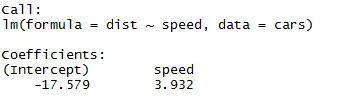
Как мы можем вспомнить из вышеприведенного сегмента статьи, уравнение линейной регрессии имеет вид:
Y = β1 + β2X + ϵ
Теперь мы поместим информацию, полученную из приведенного выше кода в этом уравнении.
dist = −17.579 + 3.932 ∗ speed
Только нахождения уравнения линейной регрессии недостаточно, мы должны также проверить его статистическую значимость. Для этого мы должны передать код «Сводка» в нашей модели линейной регрессии.
Код:

Выход:

Существует несколько способов проверки статистической значимости модели, здесь мы используем метод P-значения. Мы можем рассматривать модель как статистически подходящую, когда значение P меньше предварительно определенного статистически значимого уровня, который в идеале равен 0, 05. Мы можем видеть в нашей сводной таблице (linear_regression), что значение P ниже 0, 05 уровня, поэтому мы можем сделать вывод, что наша модель является статистически значимой. Как только мы уверены в нашей модели, мы можем использовать наш набор данных для прогнозирования.
Рекомендуемые статьи
Это руководство по анализу линейной регрессии. Здесь мы обсуждаем три типа анализа линейной регрессии, графическое представление наборов данных с преимуществами и модели линейной регрессии. Вы также можете просмотреть другие наши статьи, чтобы узнать больше-
- Формула регрессии
- Регрессионное тестирование
- Линейная регрессия в R
- Типы методов анализа данных
- Что такое регрессионный анализ?
- Основные отличия регрессии от классификации
- 6 главных отличий линейной регрессии от логистической регрессии