

Что такое алгоритм MapReduce?
Алгоритм MapReduce главным образом основан на модели функционального программирования. Он используется для обработки и генерации больших данных. Эти наборы данных могут быть запущены одновременно и распределены в кластере. Программа MapReduce в основном состоит из процедуры отображения и метода сокращения для выполнения сводной операции, такой как подсчет или получение некоторых результатов. Система MapReduce работает на распределенных серверах, которые работают параллельно и управляют всеми коммуникациями между различными системами. Модель представляет собой специальную стратегию разделения-применения-объединения, которая помогает в анализе данных. Сопоставление выполняется классом Mapper, а сокращение задачи выполняется классом Reducer.
Понимание алгоритма MapReduce
Алгоритм MapReduce в основном работает в три этапа:
- Функция карты
- Функция случайного воспроизведения
- Уменьшить функцию
Давайте обсудим каждую функцию и ее обязанности.
1. Функция карты
Это первый шаг алгоритма MapReduce. Он берет наборы данных и распределяет их на более мелкие подзадачи. Далее это делается в два этапа, разделение и отображение. Разделение берет входной набор данных и разделяет набор данных, в то время как отображение берет эти подмножества данных и выполняет требуемое действие. Результатом этой функции является пара ключ-значение.
2. Функция перемешивания
Это также называется функцией объединения и включает в себя слияние и сортировку. Слияние объединяет все пары ключ-значение. Все они будут иметь одинаковые ключи. Сортировка берет ввод с шага слияния и сортирует все пары ключ-значение, используя ключи. Этот шаг также вернется к парам ключ-значение. Вывод будет отсортирован.
3. Уменьшить функцию
Это последний шаг этого алгоритма. Он берет пары ключ-значение из тасования и сокращает время работы.
Как алгоритмы MapReduce облегчают работу?
Системы реляционных баз данных имеют централизованный сервер, который помогает хранить и обрабатывать данные. Обычно это были централизованные системы. Когда на изображение попадает несколько файлов, обработка становится утомительной и создает узкое место при обработке нескольких файлов. MapReduce отображает набор данных и преобразует набор данных, в котором все данные разделены на кортежи, и задача сокращения получит выходные данные этого шага и объединит эти кортежи данных в меньшие наборы. Он работает на разных этапах и создает пары ключ-значение, которые могут быть распределены по разным системам.
Что вы можете сделать с алгоритмами MapReduce?
MapReduce можно использовать с различными приложениями. Он может быть использован для распределенного поиска по шаблону, распределенной сортировки, обращения к графу веб-ссылок, статистики журнала веб-доступа. Он также может помочь в создании и работе с несколькими кластерами, настольными сетками, добровольными вычислительными средами. Можно также создавать динамические облачные среды, мобильные среды, а также высокопроизводительные вычислительные среды. Google использовал MapReduce, который обновляет индекс Google World Wide Web. Используя его, старые специальные программы обновляются, и они выполняют различные виды анализа. Он также интегрировал результаты поиска в реальном времени без перестройки полного индекса. Все входы и выходы хранятся в распределенной файловой системе. Данные переходного процесса хранятся на локальном диске.
Работа с алгоритмом MapReduce
Чтобы работать с алгоритмом MapReduce, вы должны знать весь процесс его работы. Получаемые данные проходят следующие этапы:
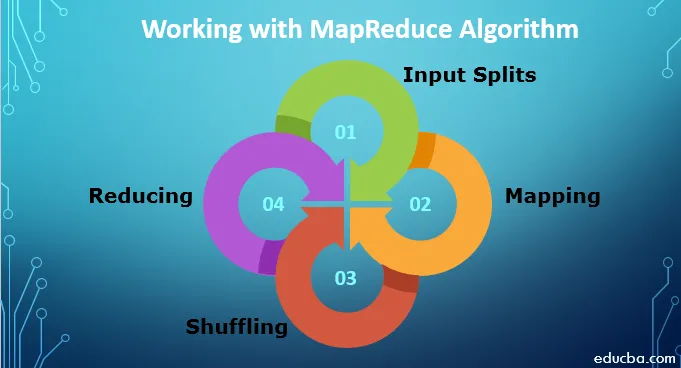
1. Входные разбиения. Любые входные данные, поступающие в задание MapReduce, делятся на равные части, известные как входные разбиения. Это кусок ввода, который может быть использован любым из картографов.
2. Отображение: после того, как данные разбиты на куски, они проходят фазу отображения в программе уменьшения карты. Эти данные разделения передаются в функцию отображения, которая выдает различные выходные значения.
3. Перемешивание: после того, как сопоставление выполнено, данные отправляются на этот этап. Его задача - объединить необходимые записи из предыдущего этапа.
4. Уменьшение: на этом этапе выходной сигнал фазы перемешивания агрегируется. На этом этапе все значения перемешиваются и объединяются путем агрегирования, чтобы он возвращал одно выходное значение. Создает сводку полного набора данных.
Преимущества алгоритма MapReduce
Приложения, использующие MapReduce, имеют следующие преимущества:
- Они были обеспечены сходимостью и хорошими показателями обобщения.
- Данные могут быть обработаны с использованием приложений, интенсивно использующих данные.
- Это обеспечивает высокую масштабируемость.
- Подсчет любых вхождений каждого слова прост и имеет обширную коллекцию документов.
- Универсальный инструмент может быть использован для поиска инструмента во многих анализах данных.
- Он предлагает время балансировки нагрузки в больших кластерах.
- Это также помогает в процессе извлечения контекстов местоположения пользователя, ситуаций и т. Д.
- Он может быстро получить доступ к большим выборкам респондентов.
Почему мы должны использовать алгоритм MapReduce?
MapReduce - это приложение, которое используется для обработки огромных наборов данных. Эти наборы данных могут обрабатываться параллельно. MapReduce потенциально может создавать большие наборы данных и большое количество узлов. Эти большие наборы данных хранятся в HDFS, что облегчает анализ данных. Он может обрабатывать любые данные, такие как структурированные, неструктурированные или полуструктурированные.
Зачем нам нужен алгоритм MapReduce?
MapReduce быстро растет и помогает в параллельных вычислениях. Это помогает в определении цены на продукты и помогает в получении самой высокой прибыли. Это также помогает в прогнозировании и рекомендации анализа. Это позволяет программистам запускать модели для различных наборов данных и использует передовые статистические методы и методы машинного обучения, которые помогают в прогнозировании данных. Он фильтрует и отправляет данные в разные узлы кластера и функционирует в соответствии с функциями картографирования и редуктора.
Как эта технология поможет вам в карьерном росте?
Hadoop является одним из самых востребованных рабочих мест в наши дни. Это ускоряет темпы и возможности, которые очень быстро растут в этой области. Там будет бум в этой области еще больше. У ИТ-специалистов, работающих в Java, есть плюс, так как они являются наиболее востребованными людьми. Кроме того, разработчики, архитекторы данных, хранилища данных и специалисты по бизнес-аналитикам могут отнимать огромные суммы заработной платы, изучая эту технологию.
Вывод
MapReduce - это основа фреймворка Hadoop. Изучив это, вы обязательно попадете на рынок аналитики данных. Вы можете подробно изучить его и узнать, как обрабатываются большие наборы данных и как эта технология вносит изменения в обработку и хранение данных.
Рекомендуемые статьи
Это руководство по алгоритмам MapReduce. Здесь мы обсуждаем концепцию, понимание, работу, потребность, преимущества и карьерный рост. Вы также можете просмотреть наши другие Предлагаемые статьи, чтобы узнать больше -
- MapReduce Интервью Вопросы
- Что такое MapReduce в Hadoop?
- Как работает MapReduce?
- Что такое MapReduce?
- Отличия Hadoop от MapReduce
- Различные операции, связанные с кортежами