

Введение в AWS EMR
AWS EMR предоставляет множество функций, которые облегчают нам задачу, вот некоторые из технологий:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Амазонка лямбда
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
Amazon EMR - это одна из основных услуг, предоставляемых AWS EMR.
EMR, обычно называемый Elastic Map Reduce, предлагает простой и доступный способ обработки больших массивов данных. Представьте себе сценарий с большими данными, когда у нас есть огромное количество данных, и мы выполняем над ними набор операций, скажем, выполняется задание Map-Reduce, одной из основных проблем, с которыми сталкивается приложение Bigdata, является настройка программы. часто бывает трудно точно настроить нашу программу таким образом, чтобы все выделенные ресурсы использовались правильно. Из-за указанного выше коэффициента настройки время, затрачиваемое на обработку, постепенно увеличивается. Elastic Map Reduce от Amazon - это веб-сервис, который предоставляет платформу, которая управляет всеми этими необходимыми функциями, необходимыми для обработки больших данных, экономичным, быстрым и безопасным способом. От создания кластера до распределения данных по различным экземплярам все эти вещи легко управляются в Amazon EMR. Услуги, предоставляемые по запросу, означают, что мы можем контролировать числа на основе имеющихся у нас данных, что делает их рентабельными и масштабируемыми.
Причины использования AWS EMR
Так зачем использовать AMR, что делает его лучше от других. Мы часто сталкиваемся с очень простой проблемой, когда мы не можем распределить все ресурсы, доступные по кластеру, для какого-либо приложения, AMAZON EMR заботится об этих проблемах и основывается на размере данных и требовании приложения, которое выделяет необходимый ресурс. Кроме того, будучи эластичным по природе, мы можем изменить его соответственно EMR имеет огромную поддержку приложений, будь то Hadoop, Spark, HBase, что облегчает обработку данных. Он поддерживает различные операции ETL быстро и экономически эффективно. Может также использоваться для MLIB в Spark. Мы можем выполнять различные алгоритмы машинного обучения внутри него. Будь то пакетные данные или потоковая передача данных в реальном времени, EMR способна организовать и обрабатывать оба типа данных.
Работа AWS EMR
Теперь давайте посмотрим на эту диаграмму кластера Amazon EMR и попытаемся понять, как на самом деле это работает:
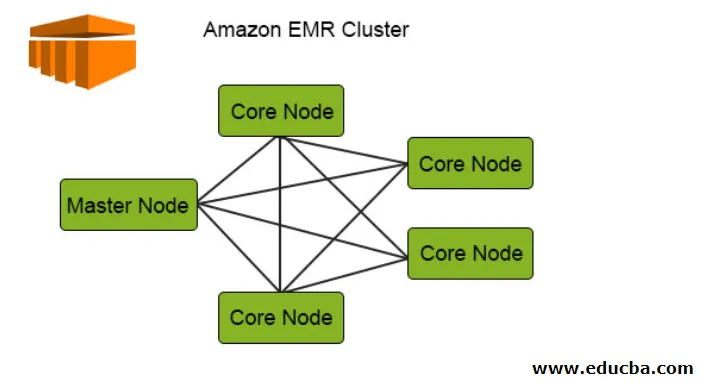
Следующая диаграмма изображает распределение кластеров внутри ЭМИ. Давайте проверим это подробно:
1. Кластеры являются центральным компонентом архитектуры Amazon EMR. Они представляют собой набор экземпляров EC2, называемых узлами. Каждый узел имеет свои определенные роли в кластере, называемые типом узла, и на основании их ролей мы можем классифицировать их по 3 типам:
- Мастер Узел
- Базовый узел
- Task Node
2. Главный узел, как следует из названия, является главным, который отвечает за управление кластером, запуск компонентов и распределение данных по узлам для обработки. Он просто отслеживает, все ли правильно управляется и работает нормально, и работает в случае сбоя.
3. Основной узел отвечает за выполнение задачи и сохранение данных в HDFS в кластере. Все обрабатывающие части обрабатываются основным узлом, а данные после этой обработки помещаются в нужное место HDFS.
4. Узел задачи, являющийся необязательным, имеет только задание для запуска задачи, при этом данные не сохраняются в HDFS.
5. Всякий раз, когда после подачи работы у нас есть несколько методов, чтобы выбрать, как работы должны быть завершены. Будучи от завершения кластера после завершения задания до продолжительного кластера, использующего консоль EMR и CLI для отправки шагов, у нас есть все привилегии для этого.
6. Мы можем напрямую запустить задание в EMR, подключив его к главному узлу через доступные интерфейсы и инструменты, которые запускают задания непосредственно в кластере.
7. Мы также можем запускать наши данные на разных этапах с помощью EMR, все, что нам нужно сделать, это отправить один или несколько упорядоченных шагов в кластере EMR. Данные хранятся в виде файла и обрабатываются последовательно. Начиная его с «Ожидание в состояние« Завершено »», мы можем проследить этапы обработки и найти ошибки, в том числе «Не удалось отменить», все эти шаги можно легко отследить до этого.
8. Как только все экземпляры завершены, достигается завершенное состояние для кластера.
Архитектура для AWS EMR
Архитектура EMR представляет себя, начиная с части хранения и заканчивая частью приложения.
- Самый первый уровень поставляется с уровнем хранения, который включает в себя различные файловые системы, используемые с нашим кластером. Будь то HDFS, EMRFS и локальная файловая система, все они используются для хранения данных во всем приложении. Кэширование промежуточных результатов при обработке MapReduce может быть достигнуто с помощью этих технологий, которые поставляются с EMR.
- Второй уровень поставляется с управлением ресурсами для кластера, этот уровень отвечает за управление ресурсами для кластеров и узлов в приложении. Это в основном помогает как инструмент управления, который помогает равномерно распределять данные по кластеру и правильно управлять им. Инструментом управления ресурсами по умолчанию, который использует EMR, является YARN, представленный в Apache Hadoop 2.0. Он централизованно управляет ресурсами для нескольких сред обработки данных. Он заботится обо всей информации, необходимой для нормальной работы кластера, начиная от работоспособности узла и заканчивая распределением ресурсов с управлением памятью.
- Третий уровень поставляется с платформой обработки данных, этот уровень отвечает за анализ и обработку данных. EMR поддерживает множество платформ, которые играют важную роль в параллельной и эффективной обработке данных. Некоторые из поддерживаемых нами фреймворков - APACHE HADOOP, SPARK, SPARK STREAMING и т. Д.
- Четвертый уровень сочетается с Приложением и такими программами, как HIVE, PIG, потоковая библиотека, алгоритмы ML, которые полезны для обработки и управления большими наборами данных.
Преимущества AWS EMR
Давайте теперь проверим некоторые преимущества использования EMR:
- Высокая скорость: поскольку все ресурсы используются должным образом, время обработки запроса сравнительно меньше, чем у других инструментов обработки данных, и они имеют достаточно четкую картину.
- Массовая обработка данных: чем больше размер данных, тем больше у EMR возможность обрабатывать огромное количество данных за достаточное время.
- Минимальная потеря данных. Поскольку данные распределяются по кластеру и обрабатываются параллельно по сети, вероятность потери данных минимальна, и, следовательно, точность обработки обработанных данных выше.
- Экономически эффективен: будучи экономически выгодным, он дешевле, чем любая другая доступная альтернатива, что делает его сильным по сравнению с использованием в промышленности. Поскольку цены ниже, мы можем разместить большие объемы данных и обработать их в рамках бюджета.
- Интегрированная AWS: она интегрирована со всеми сервисами AWS, что обеспечивает легкую доступность под крышей, поэтому безопасность, хранение и сетевое взаимодействие - все интегрировано в одном месте.
- Безопасность. Имеется замечательная группа безопасности для управления входящим и исходящим трафиком, а также использование ролей IAM делает его более безопасным, поскольку оно предлагает различные разрешения, обеспечивающие безопасность данных.
- Мониторинг и развертывание: у нас есть надлежащие инструменты мониторинга для всех приложений, работающих на кластерах EMR, что делает его прозрачным и легким для анализа, а также имеет функцию автоматического развертывания, где приложение настраивается и развертывается автоматически.
Есть намного больше преимуществ в том, чтобы иметь EMR как лучший выбор другого метода вычисления кластера.
Цены на AWS EMR
EMR поставляется с удивительным прайс-листом, который привлекает разработчиков или рынок к нему. Так как он поставляется с функцией ценообразования по требованию, мы можем использовать его чуть более почасово и с количеством узлов в нашем кластере. За каждую секунду, которую мы используем, мы можем платить за каждую секунду с минимальной минутой. Мы также можем выбрать наши экземпляры, которые будут использоваться в качестве зарезервированных экземпляров или выборочных экземпляров, что позволяет значительно сэкономить.
Мы можем рассчитать общий счет за простой ежемесячный калькулятор по ссылке ниже: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
Для получения более подробной информации о точных ценах, вы можете обратиться к документу ниже Amazon:
https://aws.amazon.com/emr/pricing/
Вывод
Из вышеприведенной статьи мы увидели, как EMR можно использовать для добросовестной обработки больших данных со всеми используемыми ресурсами.
Наличие EMR решает нашу основную проблему обработки данных и значительно сокращает время обработки на большое количество, будучи экономически эффективным, его легко и удобно использовать.
Рекомендуемая статья
Это было руководство по AWS EMR. Здесь мы обсуждаем введение в AWS EMR, а также его работу и архитектуру, а также преимущества. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- Альтернативы AWS
- Команды AWS
- Сервисы AWS
- Вопросы интервью AWS
- Сервисы хранения AWS
- Топ 7 конкурентов AWS
- Список функций веб-сервисов Amazon