

Что такое AWS Kinesis?
Kinesis - это платформа, которая помогает собирать, обрабатывать и анализировать потоковые данные в Amazon Web Services. Потоковые данные - это большой объем данных, которые создаются из различных источников, таких как социальные сети, датчики IoT, прогноз погоды, здравоохранение и т. Д. Они используются при создании приложений в соответствии с требованиями пользователя. Некоторые из распространенных приложений включают в себя прогнозную аналитику в больших данных, машинное обучение и т. Д. В этом разделе мы познакомимся с AWS Kinesis.
Сервис AWS Kinesis
Прежде чем перейти к услугам, давайте сначала разберемся в некоторых терминологиях, используемых в Kinesis.
терминология
| Срок | Определение |
| Запись данных | Блок данных хранится в потоке данных Kinesis. Он состоит из двоичного объекта данных, порядкового номера и ключа раздела |
| осколок | Набор последовательности записей данных. Количество сегментов может быть увеличено или уменьшено при увеличении скорости передачи данных. |
| Срок хранения | Период времени, в течение которого данные могут быть доступны после их добавления в поток.
Срок хранения по умолчанию: 24 часа |
| Режиссер | Он передает записи данных в Kinesis Stream |
| потребитель | Он получает записи из Kinesis Stream и обрабатывает их. |
Kinesis предоставляет 3 основных сервиса. Они есть:
1. Кинезис Потоки
Kinesis Stream состоит из набора последовательностей записей данных, известных как Осколки. Эти шарды имеют фиксированную емкость, которая может обеспечить максимальную скорость чтения 2 МБ / с и скорость записи 1 МБ / с. Максимальная емкость потока - это сумма емкости каждого шарда.
Работа Kinesis:
- Данные, создаваемые IoT и другими источниками, известными как производители, поступают в потоки Kinesis для хранения в шардах.
- Эти данные будут доступны в шарде не более 24 часов.
- Если он должен храниться дольше, чем это время по умолчанию, пользователь может увеличить срок хранения до 7 дней.
- Как только данные достигают сегментов, экземпляры EC2 могут использовать эти данные для различных целей.
- Экземпляры EC2, которые извлекают данные, называются Потребителями.
- После обработки данных они передаются в одну из веб-служб Amazon, такую как Simple Storage Service (S3), DynamoDB, Redshift и т. Д.
2. Kinesis Firehose
Kinesis Firehose помогает переносить данные в веб-сервисы Amazon, такие как Redshift, Simple Storage, Elastic Search и т. Д. Он является частью потоковой платформы, которая не управляет какими-либо ресурсами. Производители данных настроены таким образом, что данные должны отправляться в Kinesis Firehose, а затем он автоматически отправляет их в соответствующий пункт назначения.
Работа Kinesis Firehose:
- Как уже упоминалось в работе AWS Kinesis Streams, Kinesis Firehose также получает данные от таких производителей, как мобильные телефоны, ноутбуки, EC2 и т. Д. Но для этого не нужно переносить данные в сегменты или увеличивать сроки хранения, такие как Kinesis Streams. Это потому, что Kinesis Firehose делает это автоматически.
- Затем данные автоматически анализируются и передаются в Simple Storage Service
- Поскольку срок хранения отсутствует, данные необходимо анализировать или отправлять в любое хранилище в зависимости от требований пользователя.
- Если данные должны быть отправлены в Redshift, они должны быть сначала перемещены в Simple Storage Service и их необходимо скопировать в Redshift оттуда.
- Но, в случае Elastic Search, данные могут быть напрямую переданы в него, как в Simple Storage Service.
3. Кинезис Аналитика
Kinesis Firehose позволяет выполнять запросы SQL в данных, которые присутствуют в Kinesis Firehose. Используя эти SQL-запросы, данные могут храниться в Redshift, Simple Storage Service, ElasticSearch и т. Д.
AWS Kinesis Architecture
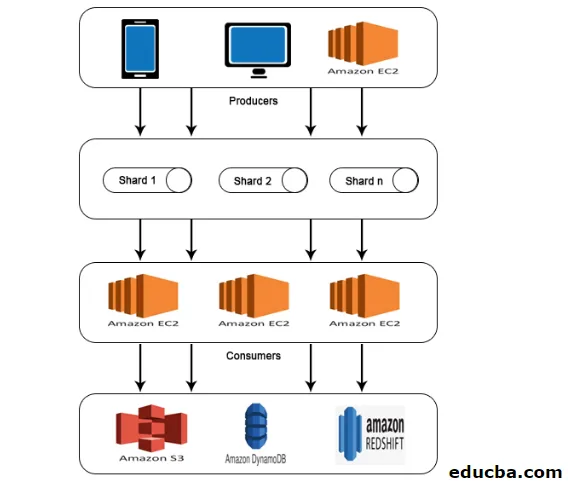
AWS Kinesis Architecture состоит из
- Производители
- Осколки
- Потребители
- Место хранения
Аналогично работе, описанной в AWS Kinesis Data Stream, данные от производителей поступают в Shards, где данные обрабатываются и анализируются. Затем проанализированные данные перемещаются в экземпляры EC2 для выполнения определенных приложений. Наконец, данные будут храниться в любых веб-сервисах Amazon, таких как S3, Redshift и т. Д.
Как использовать AWS Kinesis?
Чтобы работать с AWS Kinesis, необходимо выполнить следующие два шага.
1. Установите интерфейс командной строки AWS (CLI).
Установка интерфейса командной строки различна для разных операционных систем. Итак, установите CLI на основе вашей операционной системы.
Для пользователей Linux используйте команду sudo pip install AWS CLI
Убедитесь, что у вас есть версия Python 2.6.5 или выше. После загрузки настройте его с помощью команды AWS configure. Затем будут запрошены следующие детали, как показано ниже.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Для пользователей Windows: загрузите соответствующий установщик MSI и запустите его.
2. Выполните операции Kinesis с помощью CLI
Обратите внимание, что потоки данных Kinesis недоступны для бесплатного уровня AWS. Итак, созданные потоки Kinesis будут платными.
Теперь давайте посмотрим некоторые операции кинезиса в CLI.
- Создать поток
Создайте поток KStream с количеством осколков 2, используя следующую команду.
aws kinesis create-stream --stream-name KStream --shard-count 2
Проверьте, создан ли поток.
aws kinesis describe-stream --stream-name KStream
Если он создан, появится вывод, похожий на следующий пример.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Поставить запись
Теперь запись данных может быть вставлена с помощью команды put-record. Здесь запись, содержащая тест данных, вставляется в поток.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Если вставка прошла успешно, вывод будет отображаться, как показано ниже.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Получить запись
Во-первых, пользователь должен получить итератор сегмента, который представляет позицию потока для сегмента.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Затем выполните команду, используя полученный итератор осколка.
aws kinesis get-records --shard-iterator ###########
Пример вывода будет получен, как показано ниже.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Очистить
Чтобы избежать начислений, созданный поток можно удалить с помощью приведенной ниже команды.
aws kinesis delete-stream --stream-name KStream
Вывод
AWS Kinesis - это платформа, которая собирает, обрабатывает и анализирует потоковые данные для нескольких приложений, таких как машинное обучение, прогнозная аналитика и т. Д. Потоковые данные могут иметь любой формат, такой как аудио, видео, данные датчиков и т. Д.
Рекомендуемые статьи
Это руководство по AWS Kinesis. Здесь мы обсудим, как использовать AWS Kinesis, а также его Сервис с работой и архитектурой. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Архитектура AWS
- Что такое AWS Lambda?
- Технологии больших данных
- Архитектура интеллектуального анализа данных
- Сервисы хранения AWS
- Руководство для конкурентов AWS с функциями