

Введение в RDBMS Интервью Вопросы и ответы
Так что если вы готовитесь к собеседованию в RDBMS. Я уверен, что вы хотите знать наиболее распространенные вопросы и ответы на вопросы о СУРБД 2019 года, которые помогут вам с легкостью взломать интервью СУРБД. Ниже приведен список лучших вопросов и ответов на вопросы по СУРБД.
Следовательно, мы склонны добавлять топ-2019 вопросов интервью RDBMS, которые задаются в основном в интервью
1. Каковы различные особенности СУБД?
Ответ:
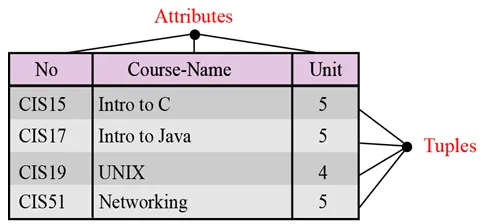
Имя. Каждое отношение в реляционной базе данных должно иметь имя, которое является уникальным среди всех других отношений.
Атрибуты. Каждый столбец в отношении называется атрибутом.
Кортежи. Каждая строка в отношении называется кортежем. Кортеж определяет коллекцию значений атрибутов.
2. Объясните ER модель?
Ответ:
Модель ER является моделью Entity-Relationship. Модель ER основана на реальном мире, который состоит из сущностей и объектов отношений. Объекты иллюстрируются в базе данных набором атрибутов.
3. Определить объектно-ориентированную модель?
Ответ:
Объектно-ориентированная модель основана на коллекциях объектов. Объект вмещает значения, которые хранятся в переменных экземпляра внутри объекта. Объекты с одинаковым типом значений и одинаковыми методами группируются в классы.
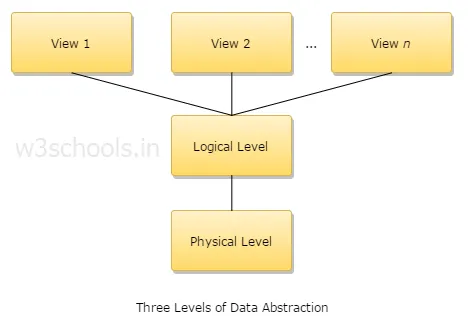
4. Объясните три уровня абстракции данных?
Ответ:
1. Физический уровень: это самый низкий уровень абстракции, и он описывает, как хранятся данные.
2. Логический уровень: следующий уровень абстракции является логическим, он описывает, какой тип данных хранится в базе данных и какова связь между этими данными.
3. Уровень представления: самый высокий уровень абстракции, и он описывает только всю базу данных.
 https://www.w3schools.in/dbms/data-schemas/
https://www.w3schools.in/dbms/data-schemas/
5. Чем отличаются 12 правил Кодда для реляционной базы данных?
Ответ:
12 правил Кодда представляют собой набор из 13 правил (от нуля до двенадцати), предложенных Эдгаром Ф. Коддом.
Правила Кодда: -
Правило 0: система должна квалифицироваться как реляционная, как база данных, а также как система управления.
Правило 1: Правило информации: каждая информация в базе данных должна быть представлена уникально, в основном это значения имен в позициях столбцов в разных строках таблицы.
Правило 2: Правило гарантированного доступа: все данные должны быть агрессивными. Это говорит о том, что каждое скалярное значение в базе данных должно быть правильно / логически адресуемым.
Правило 3: Систематическая обработка нулевых значений: СУБД должна позволять каждому кортежу оставаться нулевым.
Правило 4: Активный онлайн-каталог (структура базы данных), основанный на реляционной модели: система должна поддерживать онлайн, реляционную и т. Д. Структуру, доступную для разрешенных пользователей посредством их регулярного запроса.
Правило 5: всеобъемлющий подъязык данных: система должна поддерживать как минимум один язык отношений, который:
1.Имеет линейный синтаксис
2. которые можно использовать как в интерактивном режиме, так и в прикладных программах,
3.Он поддерживает операции определения данных (DDL), операции манипулирования данными (DML), ограничения безопасности и целостности, а также операции управления транзакциями (начало, принятие и откат).
Правило 6: Правило обновления представления. Все представления, которые теоретически улучшаются, должны быть обновлены системой.
Правило 7: Вставка, обновление и удаление высокого уровня: Система должна поддерживать операторы вставки, обновления и удаления.
Правило 8: Физическая независимость данных: изменение физического уровня (способ хранения данных, использование массивов или связанных списков и т. Д.) Не должно требовать модификации приложения.
Правило 9: Логическая независимость данных: изменение логического уровня (таблицы, столбцы, строки и т. Д.) Не должно требовать модификации приложения.
Правило 10: Независимость целостности. Ограничения целостности должны идентифицироваться индивидуально из прикладных программ и храниться в каталоге.
Правило 11. Независимость от распределения. Распределение частей базы данных по разным местам не должно быть видно пользователям базы данных.
Правило 12: Правило недопустимости: если система предоставляет низкоуровневый интерфейс (т. Е. Записи), то этот интерфейс нельзя использовать для подрыва системы.
6. Что такое нормализация? и что объясняет разные формы нормализации.
Ответ:
Нормализация базы данных - это процесс организации данных для минимизации избыточности данных. Что, в свою очередь, обеспечивает согласованность данных. Есть много проблем, связанных с избыточностью данных, таких как потеря дискового пространства, несогласованность данных, запросы DML (Data Manipulation Language) становятся медленными. Существуют различные формы нормализации: - 1NF, 2NF, 3NF, BCNF, 4NF, 5NF, ONF, DKNF.
1. 1NF: - Данные в каждом столбце должны состоять из нескольких значений, разделенных запятой. Таблица не содержит повторяющихся групп столбцов. Идентификация каждой записи однозначно с использованием первичного ключа.
2. 2NF: - таблица должна соответствовать всем условиям 1NF и перемещать избыточные данные в отдельную таблицу. Более того, он создает связь между этими таблицами, используя внешние ключи.
3. 3NF: - для таблицы 3NF должны выполняться все условия 1NF и 2NF. 3NF не содержит атрибутов, которые частично зависят от первичного ключа.
7. Определите первичный ключ, внешний ключ, ключ-кандидат, супер-ключ?
Ответ:
Первичный ключ: первичный ключ - это ключ, который не допускает дублирования значений и значений NULL. Первичный ключ может быть определен на уровне столбца или таблицы. Разрешается только один первичный ключ на таблицу.
Внешний ключ: внешний ключ допускает значения, присутствующие только в указанном столбце. Это позволяет дублировать или нулевые значения. Его можно определить как уровень столбца или уровень таблицы. Он может ссылаться на столбец уникального / первичного ключа.
Ключ-кандидат. Ключ- кандидат является минимальным супер-ключом, поэтому не существует соответствующей подгруппы атрибутов ключа-кандидата, которая может быть супер-ключом.
Суперключ: Суперключ - это набор атрибутов схемы отношений, от которых частично зависят все атрибуты схемы. Никакие две строки не могут иметь одинаковое значение атрибутов суперключа.
8. Что такое другой тип индексов?
Ответ:
Индексы: -
Кластерный индекс: - это индекс, по которому физически хранятся данные на диске. Следовательно, только один кластерный индекс может быть создан для таблицы базы данных.
Некластеризованный индекс: - Он не определяет физические данные, но определяет логический порядок. Как правило, B-Tree или B + Tree создаются для этой цели.
9. Каковы преимущества СУРБД?
Ответ:
• Контроль избыточности.
• Целостность может быть обеспечена.
• Несоответствия можно избежать.
• Данные могут быть разделены.
• Стандарт может быть обеспечен.
10. Назовите некоторые подсистемы СУРБД?
Ответ:
Ввод-вывод, безопасность, обработка языка, управление хранением, ведение журналов и восстановление, управление распределением, управление транзакциями, управление памятью.
11. Что такое Buffer Manager?
Ответ:
Buffer Manager управляет сбором данных с дискового хранилища в основную память и определяет, какие данные должны быть в кэш-памяти для более быстрой обработки.
Рекомендуемая статья
Это было руководство к Списку Вопросов Интервью RDBMS и ответов, чтобы кандидат мог легко разобрать эти Вопросы Интервью RDBMS. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Важнейшие вопросы интервью аналитики данных
- 13 удивительных вопросов и ответов на вопросы интервьюирования базы данных
- 10 лучших вопросов и ответов по шаблонам дизайна
- 5 полезных вопросов и ответов SSIS Interview