

Введение в карту Присоединиться в Улей
Присоединение к карте - это функция, используемая в запросах Hive для повышения эффективности с точки зрения скорости. Объединение - это условие, используемое для объединения данных из 2 таблиц. Таким образом, когда мы выполняем обычное объединение, задание отправляется в задачу Map-Reduce, которая разбивает основную задачу на 2 этапа - «Этап карты» и «Этап сокращения». Этап Map интерпретирует входные данные и возвращает вывод на этап сокращения в форме пар ключ-значение. Далее идет этап перемешивания, где они сортируются и объединяются. Редуктор принимает это отсортированное значение и завершает задание соединения.
Таблица может быть загружена в память полностью внутри картографа без использования процесса Map / Reducer. Он считывает данные из таблицы меньшего размера и сохраняет их в хэш-таблице в памяти, а затем сериализует их в файл хэш-памяти, тем самым существенно сокращая время. Это также известно как Map Side Join в Hive. По сути, это включает в себя выполнение объединений между двумя таблицами, используя только фазу Map и пропуская фазу Reduce. Уменьшение времени вычислений ваших запросов может наблюдаться, если они регулярно используют небольшие объединения таблиц.
Синтаксис для присоединения к карте в Hive
Если мы хотим выполнить запрос на соединение, используя map-join, тогда мы должны указать ключевое слово «/ * + MAPJOIN (b) * /» в выражении, как показано ниже:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Для этого примера нам нужно создать 2 таблицы с именами tablename1 и tablename2, имеющими 2 столбца: emp_id и emp_name. Один должен быть большим файлом, а другой - меньшим.
Перед выполнением запроса мы должны установить для свойства ниже значение true:
hive.auto.convert.join=true
Запрос на соединение для соединения с картой написан, как указано выше, и мы получаем следующий результат:
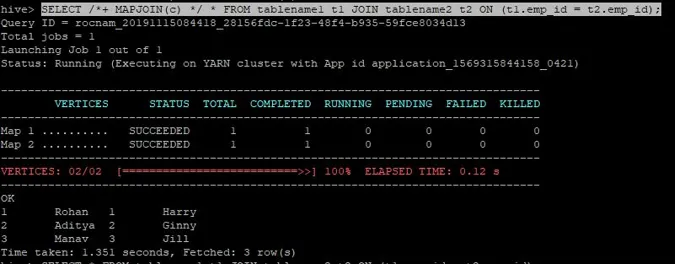
Запрос был выполнен за 1, 351 секунды.
Примеры присоединения карты в улье
Вот следующие примеры упоминания ниже
1. Пример соединения карты
Для этого примера давайте создадим 2 таблицы с именами table1 и table2 с 100 и 200 записями соответственно. Вы можете использовать приведенную ниже команду и снимки экрана для выполнения того же самого:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Теперь мы загружаем записи в обе таблицы, используя следующие команды:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Давайте выполним обычный запрос присоединения карты к их идентификаторам, как показано ниже, и проверим время, затраченное на то же самое:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
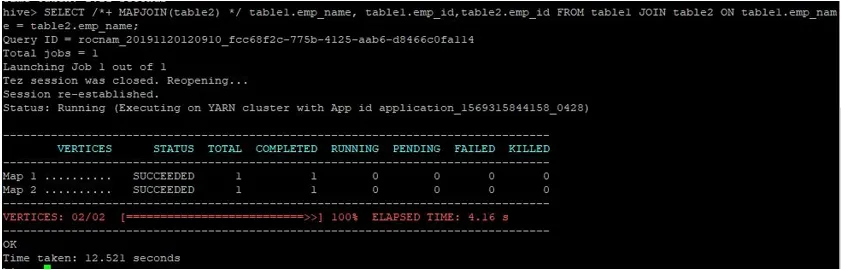
Как мы видим, обычный запрос присоединения карты занял 12, 521 секунды.
2. Пример соединения Bucket-Map
Давайте теперь использовать объединение Bucket-map для запуска того же самого. Есть несколько ограничений, которые необходимо соблюдать для группирования:
- Группы могут быть объединены друг с другом, только если общее количество групп в одной таблице кратно количеству блоков в другой таблице.
- Должны быть намотаны столы для изготовления ковшей. Поэтому давайте создадим то же самое.
Ниже приведены команды, используемые для создания таблиц с таблицами table1 и table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Мы вставим те же записи из таблицы 1 в эти таблицы с интервалами:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
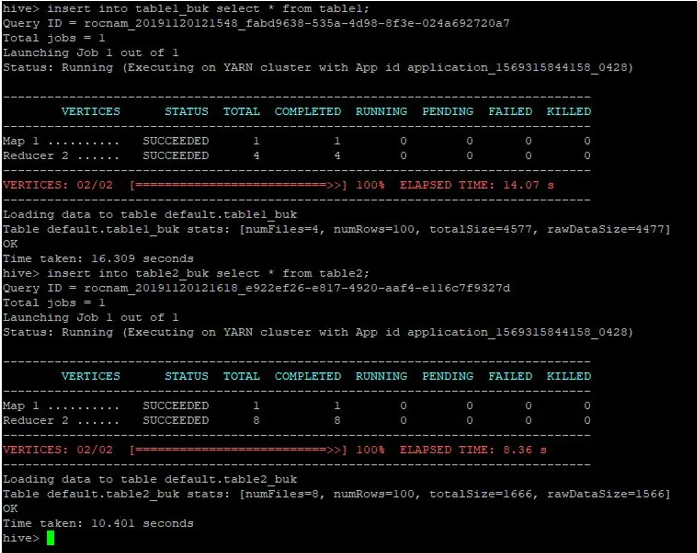
Теперь, когда у нас есть 2 таблицы с разбивкой, давайте выполним объединение по картам. Первая таблица имеет 4 сегмента, тогда как вторая таблица содержит 8 сегментов, созданных в одном столбце.
Чтобы запрос на объединение карты корзины работал, мы должны установить для свойства ниже значение true в кусте:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
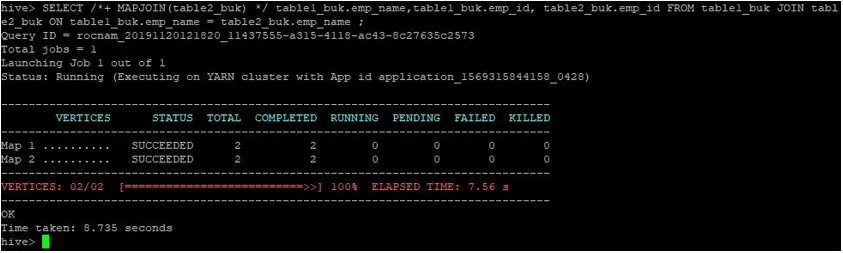
Как мы видим, запрос был выполнен за 8, 735 секунд, что быстрее, чем соединение карты нормалей.
3. Пример объединения карт сортировки слиянием (SMB)
SMB может выполняться на столах с пачкой, имеющих одинаковое количество ковшей, и если таблицы должны быть отсортированы и объединены в столбцы соединения. Уровень Mapper соответственно присоединяется к этим сегментам.
Так же, как в соединении Bucket-map, есть 4 сегмента для table1 и 8 сегментов для table2. Для этого примера мы создадим другую таблицу с 4 сегментами.
Чтобы выполнить запрос SMB, нам нужно установить следующие свойства улья, как показано ниже:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Для выполнения SMB-соединения необходимо отсортировать данные в соответствии со столбцами соединения. Следовательно, мы перезаписываем данные в таблице 1 сгруппированными, как показано ниже:
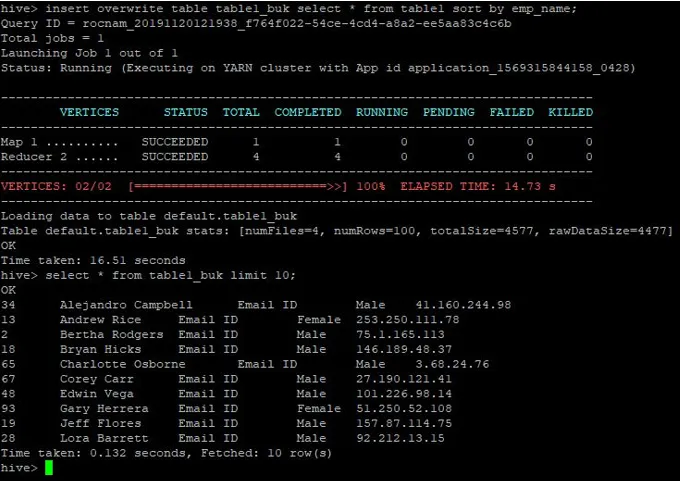
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Теперь данные отсортированы, что можно увидеть на скриншоте ниже:
Мы также перезапишем данные в объединенной таблице2, как показано ниже:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Давайте выполним объединение для вышеуказанных 2 таблиц следующим образом:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
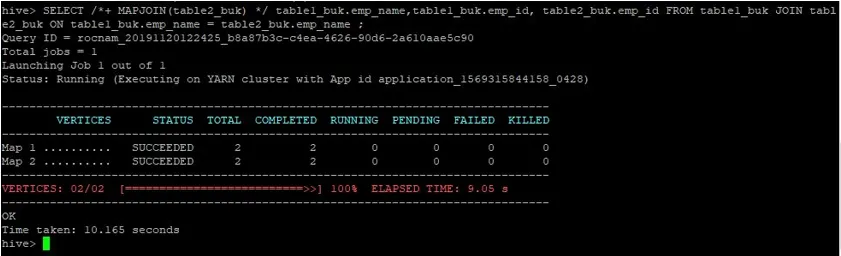
Мы видим, что запрос занял 10, 165 секунд, что опять-таки лучше, чем объединение карты нормалей.
Теперь давайте создадим еще одну таблицу для table2 с 4 сегментами и теми же данными, отсортированными по emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
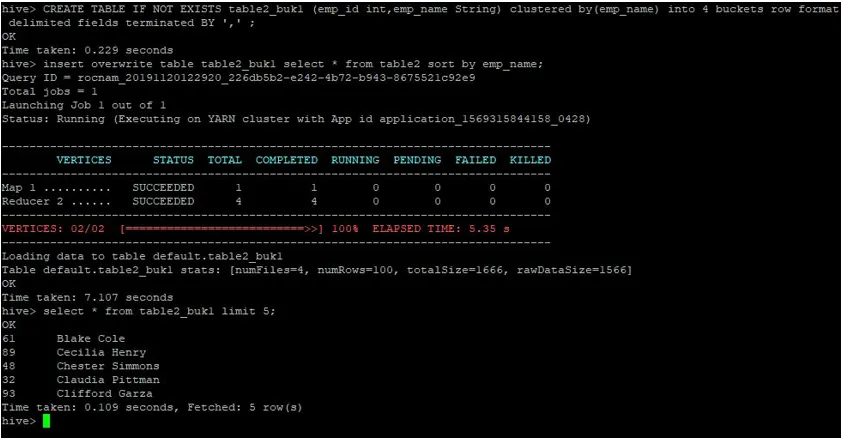
Учитывая, что теперь у нас есть обе таблицы с 4 сегментами, давайте снова выполним запрос на соединение.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
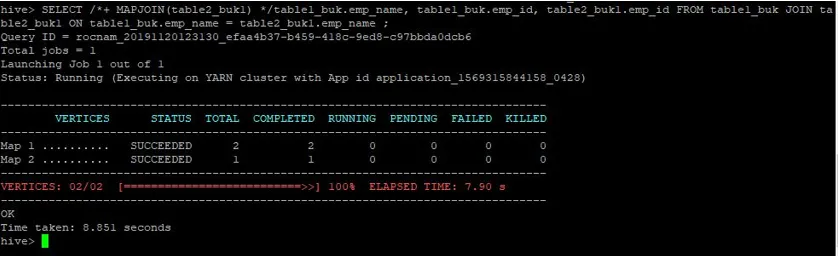
Запрос снова занял 8, 851 секунды быстрее, чем запрос на присоединение к карте нормалей.
преимущества
- Присоединение к карте сокращает время, затрачиваемое на процессы сортировки и слияния, происходящие в случайном порядке, и сокращает количество этапов, что также сводит к минимуму затраты.
- Это повышает эффективность выполнения задачи.
Ограничения
- Нельзя использовать одну и ту же таблицу / псевдоним для объединения разных столбцов в одном запросе.
- Запрос на присоединение к карте не может преобразовать полные внешние объединения в соединения на стороне карты.
- Присоединение к карте может быть выполнено только тогда, когда одна из таблиц достаточно мала, чтобы ее можно было разместить в памяти. Следовательно, это не может быть выполнено, когда данные таблицы огромны.
- Левое объединение возможно сделать с соединением карты, только когда правильный размер таблицы мал.
- Правильное соединение возможно сделать с соединением карты, только когда размер левого стола мал.
Вывод
Мы постарались включить лучшие точки Map Join в Hive. Как мы видели выше, соединение на стороне карты работает лучше всего, когда в одной таблице меньше данных, поэтому задание выполняется быстро. Время, необходимое для запросов, показанных здесь, зависит от размера набора данных, поэтому время, показанное здесь, предназначено только для анализа. Объединение карт может быть легко реализовано в приложениях реального времени, поскольку у нас есть огромные данные, что помогает снизить сетевой трафик ввода-вывода.
Рекомендуемые статьи
Это руководство к Map Join in Hive. Здесь мы обсуждаем примеры Map Join в Hive вместе с преимуществами и ограничениями. Вы также можете посмотреть следующую статью, чтобы узнать больше -
- Присоединяется в Улей
- Встроенные функции улья
- Что такое улей?
- Команды улья