
Введение в пуассоновскую регрессию в R
Регрессия Пуассона - это тип регрессии, который похож на множественную линейную регрессию, за исключением того, что ответ или зависимая переменная (Y) является переменной подсчета. Зависимая переменная следует распределению Пуассона. Предиктор или независимые переменные могут быть непрерывными или категориальными по своей природе. В некотором смысле это похоже на логистическую регрессию, которая также имеет дискретную переменную ответа. Предварительное понимание распределения Пуассона и его математической формы очень важно, чтобы использовать его для прогнозирования. В R регрессия Пуассона может быть реализована очень эффективным образом. R предлагает полный набор функций для его реализации.
Реализация пуассоновской регрессии
Теперь перейдем к пониманию того, как применяется модель. В следующем разделе приведена пошаговая процедура для того же. Для этой демонстрации мы рассматриваем набор данных «gala» из пакета «faraway». Относится к видовому разнообразию на Галапагосских островах. Всего в наборе данных 7 переменных. Мы будем использовать регрессию Пуассона, чтобы определить связь между количеством видов растений (видов) и другими переменными в наборе данных.
1. Сначала загрузите «дальний» пакет. Если пакет отсутствует, загрузите его с помощью функции install.packages ().
2. После загрузки пакета загрузите набор данных «gala» в R с помощью функции data (), как показано ниже.
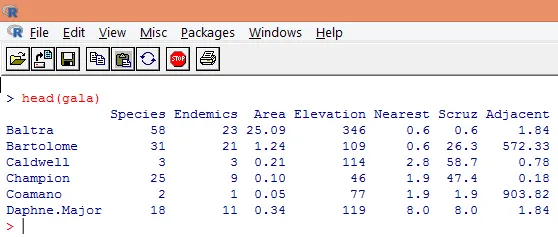
3. Загруженные данные должны быть визуализированы, чтобы изучить переменную и проверить, есть ли какие-либо расхождения. Мы можем визуализировать либо все данные, либо только первые несколько строк, используя функцию head (), как показано на скриншоте ниже.
4. Чтобы получить более полное представление о наборе данных, мы можем использовать функции справки в R, как показано ниже. Он генерирует документацию R, как показано на скриншоте после скриншота ниже.


5. Если мы изучим набор данных, как упомянуто в предыдущих шагах, то обнаружим, что Species - это переменная ответа. Теперь мы изучим основную сводку переменных предиктора.
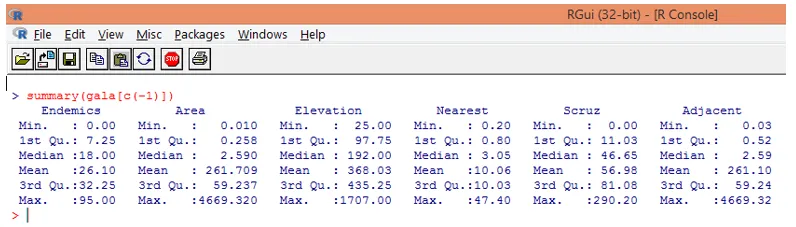
Обратите внимание, что, как видно выше, мы исключили переменную Species. Сводная функция дает нам основные идеи. Просто соблюдайте медианные значения для каждой из этих переменных, и мы можем обнаружить, что существует огромная разница, с точки зрения диапазона значений, между первой половиной и второй половиной, например, для переменной области значение медианы равно 2, 59, но максимальное значение 4669, 320.
6. Теперь, когда мы закончили с базовым анализом, мы сгенерируем гистограмму для видов, чтобы проверить, соответствует ли переменная распределению Пуассона. Это показано ниже.

Приведенный выше код генерирует гистограмму для переменной вида вместе с кривой плотности, наложенной на нее.
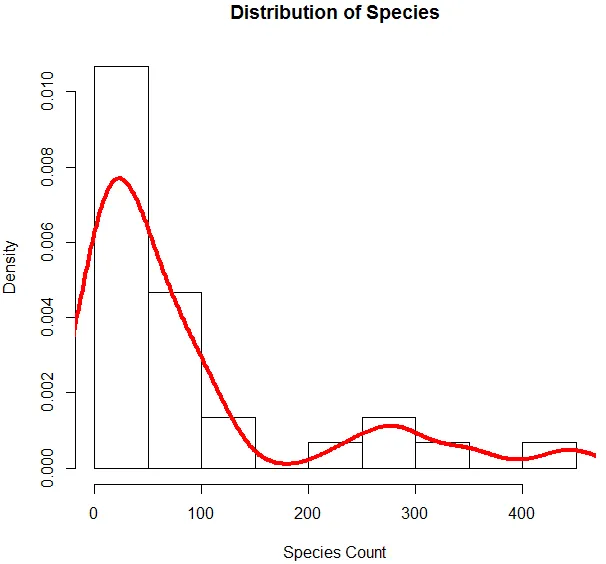
Приведенная выше визуализация показывает, что вид следует распределению Пуассона, так как данные искажены вправо. Мы также можем сгенерировать блокпост, чтобы лучше понять схему распределения, как показано ниже.
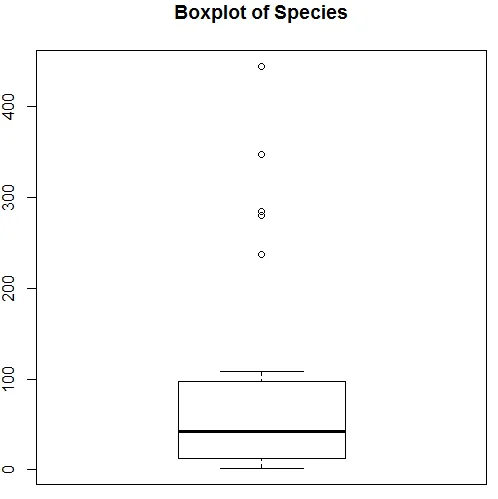
7. Закончив предварительный анализ, мы применим регрессию Пуассона, как показано ниже.
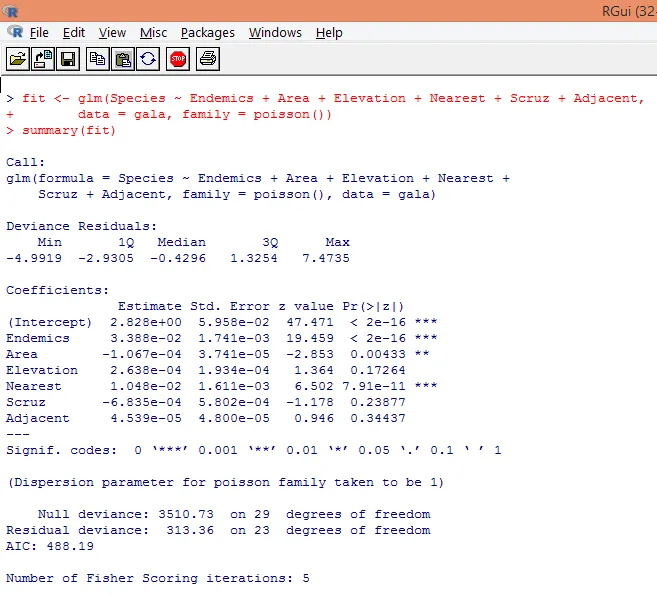
На основании приведенного выше анализа мы находим, что переменные Endemics, Area и Nearest являются значимыми, и только их включения достаточно для построения правильной модели регрессии Пуассона.
8. Мы построим модифицированную модель регрессии Пуассона, принимая во внимание только три переменные, а именно. Эндемики, Площадь и Ближайшие. Посмотрим, какие результаты мы получим.
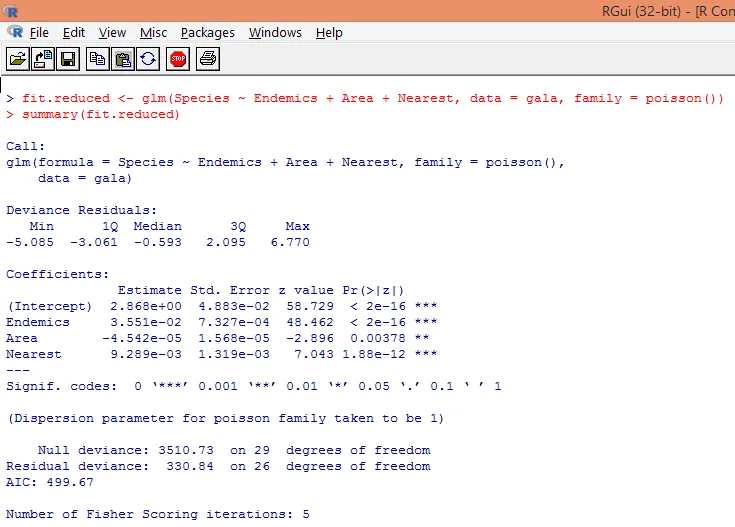
Выходные данные дают отклонения, параметры регрессии и стандартные ошибки. Видно, что каждый из параметров значим при уровне p <0, 05.
9. Следующий шаг - интерпретация параметров модели. Коэффициенты модели могут быть получены либо путем изучения коэффициентов в приведенном выше выводе, либо с помощью функции coef ().
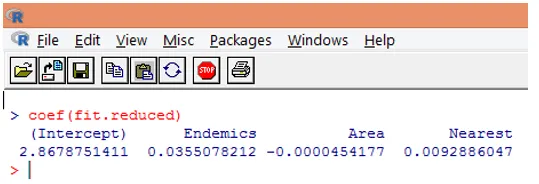
В регрессии Пуассона зависимая переменная моделируется как логарифм условного среднего ложа (l). Параметр регрессии 0, 0355 для Endemics указывает, что увеличение переменной на единицу связано с увеличением на 0, 04 среднего логарифмического числа видов, в котором другие переменные остаются постоянными. Перехват - это логарифмическое число видов, когда каждый из предикторов равен нулю.
10. Однако гораздо проще интерпретировать коэффициенты регрессии в исходной шкале зависимой переменной (количество видов, а не логарифм числа видов). Возведение в степень коэффициентов позволит легко интерпретировать. Это делается следующим образом.
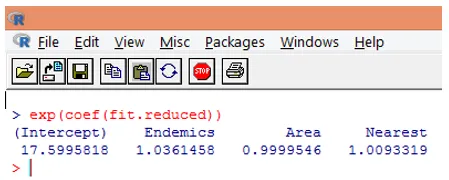
Исходя из вышеизложенных результатов, мы можем сказать, что увеличение на одну единицу Района умножает ожидаемое количество видов на 0, 9999, а увеличение единицы эндемичных видов, представленных эндемиками, увеличивает число видов на 1, 0361. Наиболее важным аспектом регрессии Пуассона является то, что возведенные в степень параметры имеют мультипликативный, а не аддитивный эффект на переменную отклика.
11. Используя вышеупомянутые шаги, мы получили регрессионную модель Пуассона для прогнозирования количества видов растений на Галапагосских островах. Тем не менее, очень важно проверить наличие избыточной дисперсии. В регрессии Пуассона дисперсия и средние значения равны.
Чрезмерная дисперсия возникает, когда наблюдаемая дисперсия переменной отклика больше, чем было бы предсказано распределением Пуассона. Анализ избыточной дисперсии становится важным, так как это обычно для данных подсчета, и может отрицательно повлиять на конечные результаты. В R избыточная дисперсия может быть проанализирована с использованием пакета «qcc». Анализ иллюстрируется ниже.
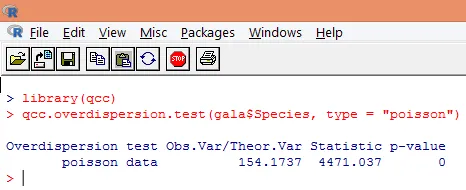
Вышеуказанный значимый тест показывает, что значение р составляет менее 0, 05, что настоятельно свидетельствует о наличии избыточной дисперсии. Мы попытаемся подобрать модель, используя функцию glm (), заменив family = «Poisson» на family = «quasipoisson». Это показано ниже.
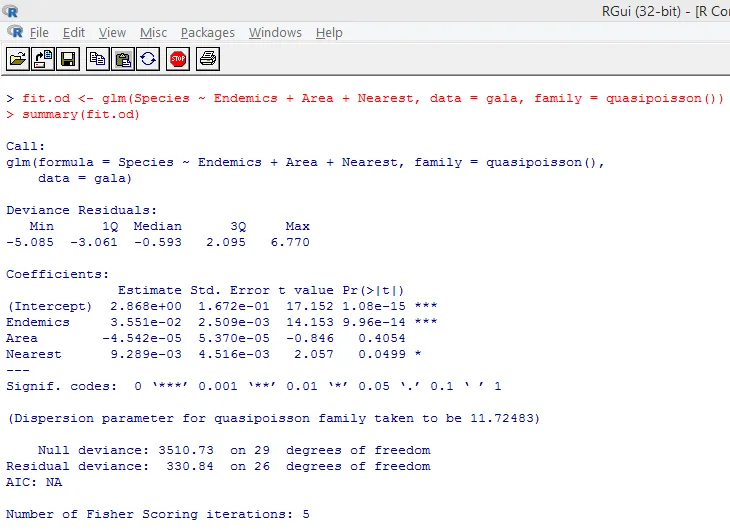
Внимательно изучив вышеприведенные результаты, мы видим, что оценки параметров в квазипуассоновском подходе идентичны оценкам, полученным в рамках пуассоновского подхода, хотя стандартные ошибки различны для обоих подходов. Более того, в этом случае для области значение р больше 0, 05, что связано с большей стандартной ошибкой.
Важность пуассоновской регрессии
- Регрессия Пуассона в R полезна для правильного предсказания дискретной / счетной переменной.
- Это помогает нам определить те объясняющие переменные, которые оказывают статистически значимое влияние на переменную ответа.
- Регрессия Пуассона в R лучше всего подходит для событий «редкой» природы, поскольку они имеют тенденцию следовать распределению Пуассона по сравнению с общими событиями, которые обычно следуют нормальному распределению.
- Он подходит для применения в случаях, когда переменная ответа представляет собой небольшое целое число.
- Он имеет широкое применение, так как прогнозирование дискретных переменных имеет решающее значение во многих ситуациях. В медицине его можно использовать для прогнозирования воздействия препарата на здоровье. Он широко используется в анализе выживания, таких как гибель биологических организмов, отказ механических систем и т. Д.
Вывод
Пуассоновская регрессия основана на концепции распределения Пуассона. Это еще одна категория, относящаяся к набору методов регрессии, которая сочетает в себе свойства как линейных, так и логистических регрессий. Однако в отличие от логистической регрессии, которая генерирует только двоичный вывод, она используется для прогнозирования дискретной переменной.
Рекомендуемые статьи
Это руководство по пуассоновской регрессии в R. Здесь мы обсуждаем введение Внедрение пуассоновской регрессии и важность пуассоновской регрессии. Вы также можете просмотреть наши другие предлагаемые статьи, чтобы узнать больше -
- GLM в R
- Генератор случайных чисел в R
- Формула регрессии
- Логистическая регрессия в R
- Линейная регрессия против логистической регрессии | Основные отличия