
Разница между BFS и DFS
Поиск в ширину (BFS) и поиск в глубину (DFS) - два важных алгоритма, используемых для поиска. Поиск в ширину начинает свой поиск с первого узла, а затем перемещается по уровням, расположенным ближе к корневому узлу, в то время как алгоритм поиска в глубину начинается с первого узла, а затем завершает свой путь к конечному узлу соответствующего пути. Оба алгоритма проходят через каждый узел во время поиска. Разные коды написаны для двух алгоритмов, чтобы выполнить процесс обхода. Они также считаются важными алгоритмами поиска в искусственном интеллекте.
В этой теме мы собираемся узнать о BFS VS DFS.
Как работают BFS и DFS?
Механизм работы обоих алгоритмов поясняется ниже на примерах. Пожалуйста, обратитесь к ним для лучшего понимания используемого подхода.
Пример поиска в ширину
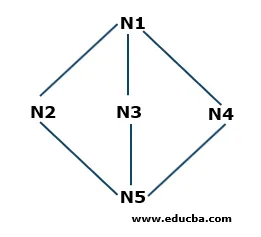
- Шаг 1: N1 является корневым узлом, поэтому он начнется отсюда. N1 связан с тремя узлами N2, N3 и N4. Все три узла еще не посещены. Итак, мы начинаем с N2 и сохраняем его в очереди. Итак, очередь с именем Q содержит только N2.
Q: N2
- Шаг 2: Следующим узлом, который подключен к N1, является N3. Поскольку мы перешли или посетили узел, мы будем хранить его в очереди. Итак, обновленная очередь
Q: N3, N2
- Шаг 3: Следующим узлом, который связан с корневым узлом, является N4. Мы будем хранить его в очереди.
Q: N4, N3, N2
- Шаг 4: Все узлы, которые подключены к N1, сохраняются в очереди. Теперь мы удаляем N2 из очереди в соответствии с принципом «первым пришел - первым вышел» (FIFO) и находим узлы, которые подключены к N2, то есть N5. N5 не посещается один раз, поэтому мы будем хранить его в очереди.
Q: N5, N4, N3
- Шаг 5: Все вершины посещены, поэтому мы продолжаем удалять узлы из очереди, пока она не станет пустой.
Пример поиска в глубину
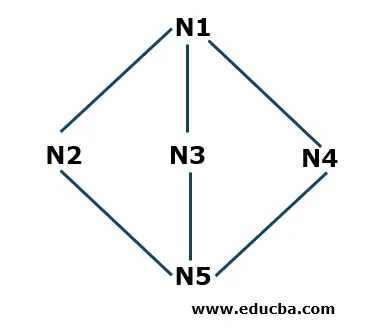
- Шаг 1: Мы начнем с N1 в качестве начального узла и сохраним его в стеке S. N1 связан с тремя соседними узлами N2, N3 и N4. Начиная с N2 (вы можете начать в алфавитном или числовом формате), мы поместим это в стек.
S: N2 (вверху), N1
- Шаг 2: Теперь соседними узлами N2 являются N1 и N5. Поскольку N1 уже присутствует в стеке, это означает, что он посещен, поэтому мы возьмем N5 и поместим его в стек S.
S: N5 (вверху), N2, N1
- Шаг 3: Теперь соседними узлами N5 являются N3 и N4. Запускаем N3 и кладем его в стек.
S: N3 (вверху), N5, N2, N1
Теперь N3 подключен к N5 и N1, которые уже присутствуют в стеке, что означает, что они посещаются, поэтому мы удалим N3 из стека в соответствии с принципом «последний пришел первым» (LIFO).
S: N5 (вверху), N2, N1
- Шаг 4: Теперь мы поместим последний узел, который мы не встречали во всем обходе в N4, и поместим его в стек.
S: N4 (вверху), N5, N2, N1
- Шаг 5: Теперь у нас нет других узлов, поэтому мы проверим в стеке, есть ли в нем какие-либо узлы, связанные с соответствующими узлами, которые не посещены. Если все подключенные узлы посещены, то мы удалим узлы, присутствующие в стеке. Например, N4 не имеет соединительных узлов, которые мы не проверяли, поэтому мы удалим его из стека. Точно так же мы можем проверить другие узлы. Алгоритм останавливается, когда стек пуст.
Сравнение лицом к лицу между BFS и DFS (инфографика)
Ниже приведены 6 основных различий между BFS и DFS.
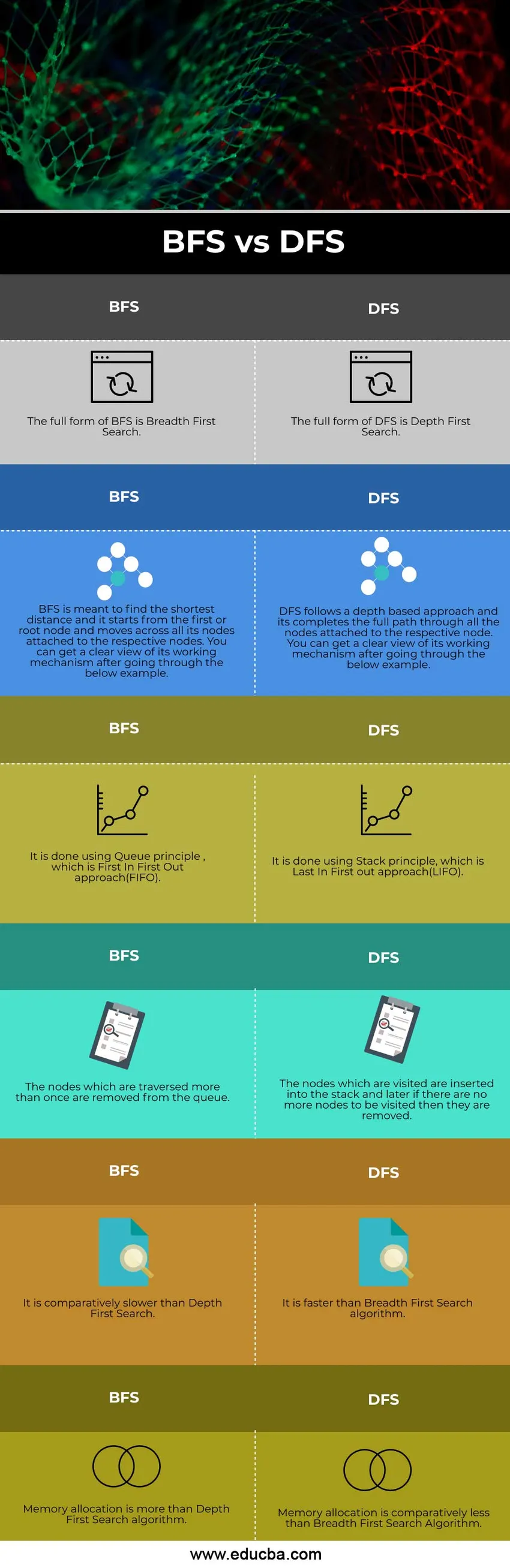
Ключевые различия между BFS и DFS
Давайте обсудим некоторые из основных ключевых различий между BFS и DFS
- Поиск в ширину (BFS) начинается с корневого узла и посещает все соответствующие узлы, подключенные к нему, в то время как DFS запускается с корневого узла и завершает полный путь, присоединенный к узлу.
- BFS следует подходу Queue, в то время как DFS следует подходу Stack.
- Подход, используемый в BFS, является оптимальным, в то время как процесс, используемый в DFS, не является оптимальным.
- Если наша цель - найти кратчайший путь, то BFS предпочтительнее DFS.
BFS и DFS Сравнительная таблица
Давайте обсудим лучшее сравнение между BFS и DFS
| BFS | ДФС |
| Полная форма BFS - поиск в ширину. | Полная форма DFS - поиск в глубину |
| BFS предназначен для нахождения кратчайшего расстояния и начинается с первого или корневого узла и перемещается по всем его узлам, прикрепленным к соответствующим узлам. Вы можете получить четкое представление о его рабочем механизме, пройдя нижеприведенный пример. | DFS следует основанному на глубине подходу и завершает полный путь через все узлы, присоединенные к соответствующему узлу. Вы можете получить четкое представление о его рабочем механизме, пройдя нижеприведенный пример. |
| Это делается с использованием принципа очереди, который является подходом First In First Out (FIFO). | Это делается с использованием принципа стека, который является подходом «первым пришел - первым вышел» (LIFO). |
| Узлы, которые пройдены более одного раза, удаляются из очереди. | Узлы, которые посещаются, вставляются в стек, и позже, если больше нет посещаемых узлов, они удаляются. |
| Это сравнительно медленнее, чем поиск в глубину. | Это быстрее, чем алгоритм поиска в ширину. |
| Выделение памяти больше, чем алгоритм поиска в глубину. | Распределение памяти сравнительно меньше, чем алгоритм поиска в ширину |
Вывод
Существует много приложений, в которых вышеуказанные алгоритмы используются в качестве машинного обучения или для поиска решений, связанных с искусственным интеллектом, и т. Д. Они в основном используются на графиках, чтобы определить, является ли это двудольным или нет, для обнаружения циклов или компонентов, которые связаны между собой. Они также считаются важными алгоритмами при поиске пути или поиске кратчайшего расстояния. В зависимости от требований бизнеса мы можем использовать два алгоритма. Однако поиск по ширине считается оптимальным способом, а не по алгоритму поиска по глубине.
Рекомендуемые статьи
Это руководство по BFS VS DFS. Здесь мы обсуждаем ключевые различия BFS VS DFS с помощью инфографики и сравнительной таблицы. Вы также можете взглянуть на следующие статьи, чтобы узнать больше -
- Алгоритм BFS
- TeraData против Oracle
- Большие данные против хранилища данных
- Большие данные по сравнению с Apache Hadoop: сравнение 4-х лучших, которые вы должны изучить