

Разница между большими данными и Apache Hadoop
Все есть в интернете. Интернет имеет много данных. Поэтому все это большие данные. Знаете ли вы, что 2, 5 квинтиллиона байтов данных создаются каждый день и накапливаются как большие данные? Наши ежедневные действия, такие как комментирование, лайки, публикации и т. Д. В социальных сетях, таких как Facebook, LinkedIn, Twitter и Instagram, складываются как большие данные. Предполагается, что к 2020 году почти 1, 7 мегабайта данных будет создаваться каждую секунду для каждого человека на земле. Вы можете вообразить и рассмотреть, сколько данных генерируется при условии, что каждый человек на земле. Сегодня мы связаны и делимся своей жизнью в Интернете. Большинство из нас подключены онлайн. Мы живем в умном доме и используем умные автомобили, и все они подключены к нашим смартфонам. Вы когда-нибудь представляли, как эти устройства становятся Smart? Я хотел бы дать вам очень простой ответ, потому что он анализирует очень большой объем данных, то есть большие данные. В течение пяти лет в мире появится более 50 миллиардов интеллектуальных подключенных устройств, разработанных для сбора, анализа и обмена данными, чтобы сделать нашу жизнь более комфортной.
Ниже приведены представления о больших данных против Apache Hadoop.
Представляя термин большие данные
Что такое большие данные? Какой размер данных считается большим и будет называться большими данными? У нас есть много относительных допущений для термина большие данные. Вполне возможно, что объем данных, скажем, 50 терабайт можно рассматривать как большие данные для стартапов, но это может быть не большие данные для таких компаний, как Google и Facebook. Это потому, что у них есть инфраструктура для хранения и обработки такого количества данных. Я хотел бы определить термин большие данные как:
- Большие данные - это объем данных, выходящий за пределы возможностей технологии для эффективного хранения, управления и обработки.
- Большие данные - это данные, чей масштаб, разнообразие и сложность требуют новой архитектуры, методов, алгоритмов и аналитики для управления ими и извлечения из них ценности и скрытых знаний.
- Большие данные - это большие объемы, высокоскоростные и разнообразные информационные активы, которые требуют экономически эффективных, инновационных форм обработки информации, которые обеспечивают более глубокое понимание, принятие решений и автоматизацию процессов.
- Большие данные относятся к технологиям и инициативам, которые включают данные, которые слишком разнообразны, быстро меняются или массивны, чтобы традиционные технологии, навыки и инфраструктура могли эффективно ими заниматься. Иными словами, объем, скорость или разнообразие данных слишком велики.
3 В больших данных
- Объем: Объем относится к количеству / количеству, при котором данные создаются, например, Каждый час, транзакции клиентов Wal-Mart предоставляют компании около 2, 5 петабайта данных.
- Скорость. Скорость - это скорость, с которой данные перемещаются так, как пользователи Facebook отправляют в среднем 31, 25 миллиона сообщений и просматривают 2, 77 миллиона видео каждую минуту каждый день по Интернету.
- Разнообразие: Разнообразие относится к разным форматам данных, которые создаются как структурированные, полуструктурированные и неструктурированные данные. Как и отправка электронных писем с вложением в Gmail, это неструктурированные данные, в то время как размещение любых комментариев с некоторыми внешними ссылками также называется неструктурированными данными. Совместное использование изображений, аудиоклипов, видеоклипов является неструктурированной формой данных.
Хранить и обрабатывать этот огромный объем, скорость и разнообразие данных - большая проблема. Нам нужно думать о других технологиях, кроме RDBMS для больших данных. Это связано с тем, что СУБД способна хранить и обрабатывать только структурированные данные. Так что тут Apache Hadoop спасает.
Представляем термин Apache Hadoop
Apache Hadoop - это программная среда с открытым исходным кодом для хранения данных и запуска приложений на кластерах стандартного оборудования. Apache Hadoop - это программная структура, которая позволяет распределенную обработку больших наборов данных по кластерам компьютеров с использованием простых моделей программирования. Он предназначен для масштабирования от отдельных серверов до тысяч машин, каждый из которых предлагает локальные вычисления и хранилище. Apache Hadoop - это платформа для хранения и обработки больших данных. Apache Hadoop способен хранить и обрабатывать все форматы данных, такие как структурированные, полуструктурированные и неструктурированные данные. Apache Hadoop - это программное обеспечение с открытым исходным кодом, а аппаратное обеспечение произвело революцию в ИТ-индустрии Он легко доступен для любого уровня компаний. Им не нужно больше вкладывать средства в настройку кластера Hadoop и в другую инфраструктуру. Итак, давайте посмотрим на полезную разницу между Big Data и Apache Hadoop подробно в этом посте.
Apache Hadoop Framework
Платформа Apache Hadoop состоит из двух частей:
- Распределенная файловая система Hadoop (HDFS): этот слой отвечает за хранение данных.
- MapReduce: этот слой отвечает за обработку данных в кластере Hadoop.
Hadoop Framework делится на ведущую и подчиненную архитектуры. Узел имени слоя распределенной файловой системы (HDFS) Hadoop является главным компонентом, а узел данных является подчиненным компонентом, а на слое MapReduce трекер заданий является главным компонентом, а трекер задач - подчиненным компонентом. Ниже приведена схема для платформы Apache Hadoop.
Почему Apache Hadoop важен?
- Возможность быстро хранить и обрабатывать огромные объемы любых данных
- Вычислительная мощность: модель распределенных вычислений Hadoop быстро обрабатывает большие данные. Чем больше вычислительных узлов вы используете, тем больше у вас вычислительной мощности.
- Отказоустойчивость: обработка данных и приложений защищена от аппаратного сбоя. Если узел выходит из строя, задания автоматически перенаправляются на другие узлы, чтобы убедиться, что распределенные вычисления не дают сбоев. Несколько копий всех данных сохраняются автоматически.
- Гибкость: вы можете хранить столько данных, сколько хотите, и решить, как их использовать позже. Это включает в себя неструктурированные данные, такие как текст, изображения и видео.
- Низкая стоимость: платформа с открытым исходным кодом является бесплатной и использует обычное оборудование для хранения больших объемов данных.
- Масштабируемость: вы можете легко расширить свою систему для обработки большего количества данных, просто добавляя узлы. Маленькая администрация требуется
Сравнение больших данных с Apache Hadoop (Инфографика)
Ниже приведено сравнение четырех лучших данных между большими данными и Apache Hadoop.
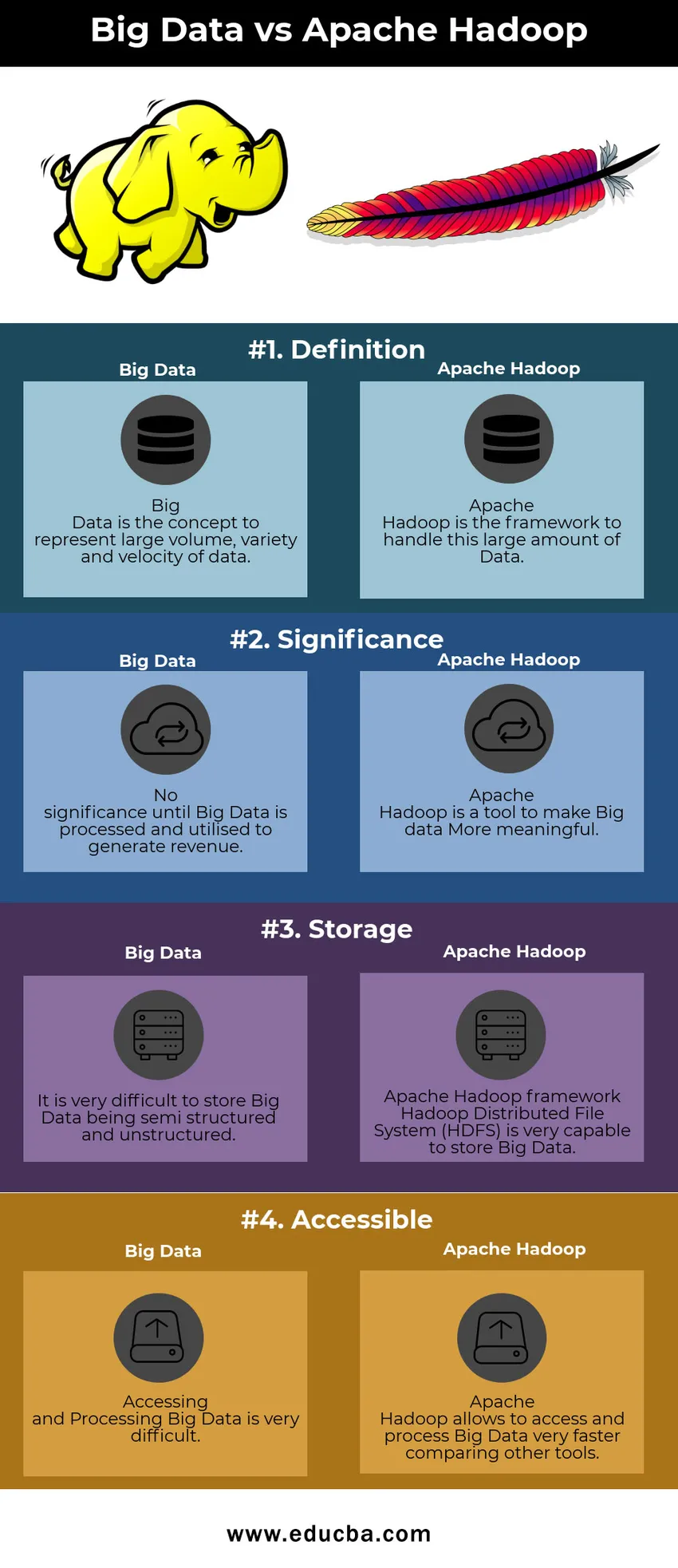
Сравнение больших данных с Apache Hadoop
Я обсуждаю основные артефакты и различаю Big Data против Apache Hadoop
| Большое количество данных | Apache Hadoop | |
| Определение | Большие данные - это концепция представления большого объема, разнообразия и скорости передачи данных. | Apache Hadoop - это платформа для обработки такого большого количества данных. |
| Значимость | Не имеет значения, пока большие данные не будут обработаны и использованы для получения дохода | Apache Hadoop - это инструмент, который делает большие данные более значимыми |
| Место хранения | Хранить большие данные очень сложно, будучи полуструктурированными и неструктурированными. | Платформа Apache Hadoop Распределенная файловая система Hadoop (HDFS) очень способна хранить большие данные. |
| доступной | Доступ и обработка больших данных очень сложны | Apache Hadoop позволяет быстрее получать доступ и обрабатывать большие данные, сравнивая другие инструменты |
Вывод - большие данные против Apache Hadoop
Вы не можете сравнивать большие данные и Apache Hadoop. Это потому, что большие данные - это проблема, а Apache Hadoop - это решение. Поскольку объем данных растет экспоненциально во всех секторах, поэтому очень сложно хранить и обрабатывать данные из одной системы. Поэтому для обработки такого большого количества данных нам необходима распределенная обработка и хранение данных. Поэтому Apache Hadoop предлагает решение для хранения и обработки очень большого количества данных. В заключение я сделаю вывод, что большие данные представляют собой большое количество сложных данных, в то время как Apache Hadoop - это механизм для хранения и эффективной обработки больших данных.
Рекомендуемая статья
Это было руководство по Big Data против Apache Hadoop, их значению, сравнению «голова к голове», ключевым различиям, сравнительной таблице и выводам. Эта статья состоит из всех полезных отличий между Big Data и Apache Hadoop. Вы также можете посмотреть следующие статьи, чтобы узнать больше -
- Большие данные против Data Science - чем они отличаются?
- 5 главных тенденций в области больших данных, которые придется освоить компаниям
- Hadoop vs Apache Spark - Интересные вещи, которые нужно знать
- Apache Hadoop против Apache Spark | 10 лучших сравнений, которые вы должны знать!